
深入學習Hadoop之第二篇——MapReduce
概念:MapReduce是一種資料處理的程式設計模型
一、Map
1.資料流:
一個MapReduce job是客戶端所執行的work的單元,它包括:輸入資料、MapReduce程式以及配置資訊;
Hadoop把MapReduce job分割為更小的tasks(map tasks和reduce tasks)來執行,這些tasks被YARN排程在叢集節點上執行;如果一個task失敗了,它會被自動排程到其他節點上重新執行;
Hadoop把MapReduce的輸入資料分割成固定長度的片段,稱作輸入切片或切片;Hadoop為每一個切片建立一個map task,並由該task來執行使用者定義的map函式從而處理切片中的每條記錄;擁有許多切片意味著處理每個切片的時間少於處理整個輸入的時間。因此,如果並行處理每個分片,且每個切片比較小,那麼整個處理過程將獲得比較好的負載均衡;因為在一個job的執行過程中,一臺更快的機器比慢的機器處理更多的切片,並且是按比例的;即使使用同樣的機器,失敗的程序和其他並行執行的jobs也能夠達到滿意的負載均衡;而且隨著切片的粒度更細負載均衡的會更高;另一方面,如果切片粒度太細,那麼管理切片的總時間和構建map任務的總時間將決定整個job的執行時間。
對於大多數job來說,一個合理的切片大小趨向於HDFS的block size,預設是128MB,不過可以針對叢集調整這個預設值(新建的所有檔案),或對新建的每個檔案具體而定。
關於切片大小的具體分析:
如果切片大小不等於block size,
1. 切片大小>block size ;
每個切片中的資料要存放在兩個甚至更多的block中,然而對於HDFS中任意一個節點基本上都不可能同時擁有這兩個block
,因此切片中的部分資料需要通過網路傳輸到map task節點,與使用本地資料執行整個map task相比,效率很低。
2. 切片大小<block size
浪費空間,一個切片放入一個block中,block卻仍留有餘地;
2.資料本地化優化
Hadoop在存有輸入資料(HDFS中的資料)的節點上執行map task,可以獲得最佳效能,這就是所謂的"資料本地化優化",因為它無需使用寶貴的叢集頻寬資源。但是,有時對於一個map task的輸入來說,存有某個HDFS block副本的三個節點可能正在執行其他map tasks,此時作業排程需要在三個副本中的某個資料尋求其所在rack中其他空閒的機器來執行該map task ;僅僅在非常偶然的情況下(該情況基本不會發生),會使用其他rack上的機器執行該map task,這將導致rack間的網路傳輸 (圖1列出了以上3種情況)。
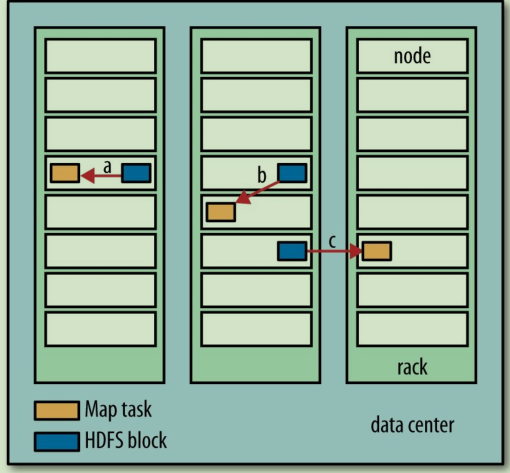
圖1. a代表本地資料,b代表本rack上的資料,c代表其他rack上的資料
如果該節點上執行的map task在將map中間結果傳送到reduce task之前failed,Hadoop會在另一個節點上重新執行這個map task以再次構建map中間結果;
二、Reduce
reduce任務並不具備資料本地化的優勢————單個reduce task的input通常來自於所有mapper的輸出;因此,排過序的map output需要通過網路傳輸傳送到執行reduce task的節點。資料在reduce端合併,然後由使用者定義的reduce函式處理(圖2,3,4顯示了具體情況)。
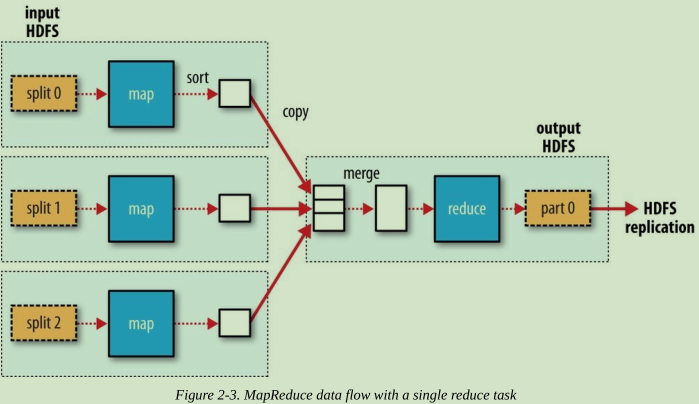
圖2.單個Reducer的資料流
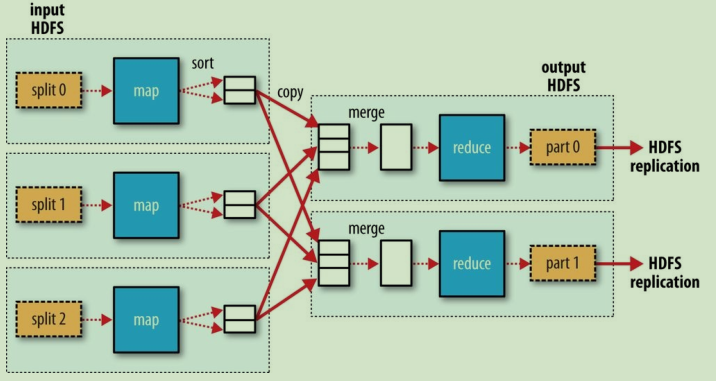
圖3.多個Reducer的資料流

圖4.無Reducer的資料流
reduce的output通常儲存在HDFS中以實現可靠儲存:對於每個reduce output的HDFS block,第一個副本儲存在本地節點上,其他副本儲存在其他rack的節點上。因此將reduce的output寫入HDFS確實需要佔用網路頻寬,但這與正常的HDFS流水線寫入的消耗一樣。
reduce的task數量並非由輸入資料的大小決定,而是獨立指定的。
如果有多個reduce tasks,每個map task就會針對map output進行partition,即為每個reduce task建一個分割槽。分割槽由使用者定義的parttition函式控制,但通常用預設的partitioner通過hash函式來分割槽很高效。
combiner函式:
叢集上的可用頻寬限制了MapReduce作業的數量,因此儘量避免map和reduce task之間的資料傳輸是有利的。combiner實際上是一個本地的reducer。combiner作為一個優化方案,有些時候並不能用,比如求均值。