
大宗交易資料探勘(一)
思路
在網上可以看到很多關於股票的資料探勘,其中也包括了一些大宗交易的資料探勘和分析。本人之前也做過比較長時間的學習,所以出於好奇,嘗試對這類資料進行挖掘:
最開始的想法
來看下百度百科對於大宗交易的解釋:
百度百科的大宗交易介紹總的來說,就是大宗交易在盤後完成,交易所公佈交易雙方的價格,數量和席位名稱(如XX證券公司XX營業部)。
有一個說法:股東要減持的話,往往是需要大量的時間和高超的操盤技巧的。如果存在一些第三方機構,可以直接把股票一次性接走,會省不少事。於是我們的目標就是嘗試找到這些機構,或者找到符合某些規則的股票,就可以嘗試去抱下大腿。實現的思路
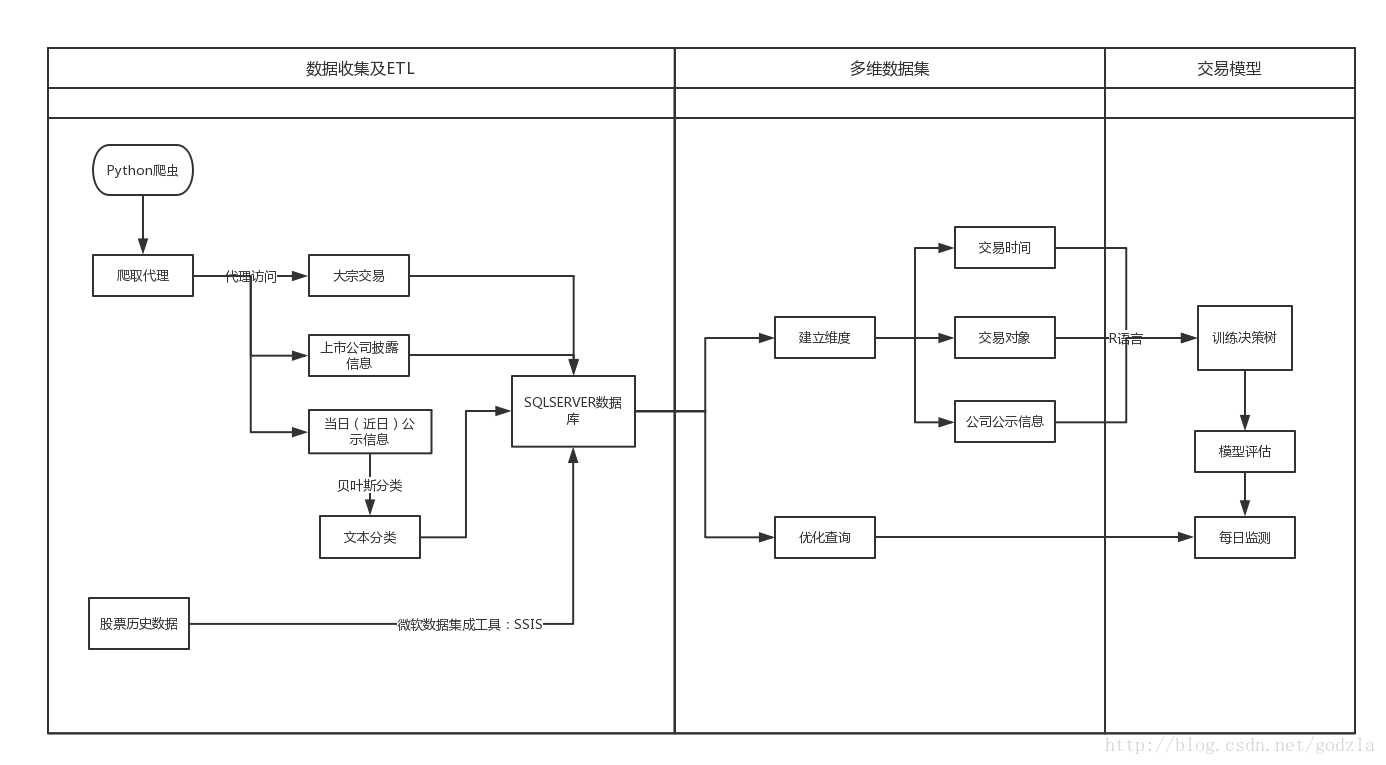
- 從交易所或者第三方網站爬取大宗交易資料,通過交易軟體獲取股票的歷史交易資料(日線);
- 資料儲存和維度;
- 建模。
工具
python3.6, SQL SERVER2012, R3.4x流程圖
相關推薦
大宗交易資料探勘(一)
思路 在網上可以看到很多關於股票的資料探勘,其中也包括了一些大宗交易的資料探勘和分析。本人之前也做過比較長時間的學習,所以出於好奇,嘗試對這類資料進行挖掘: 最開始的想法 來看下百度百科對於大宗交易的解釋: 百度百科的大宗交易介紹 總的來說,就是大宗
用 WEKA 進行資料探勘 (1)簡介和迴歸
簡介 什麼是 資料探勘?您會不時地問自己這個問題,因為這個主題越來越得到技術界的關注。您可能聽說過像 Google 和 Yahoo! 這樣的公司都在生成有關其所有使用者的數十億的資料點,您不禁疑惑,“它們要所有這些資訊幹什麼?”您可能還會驚奇地發現 Walmart 是最為先進的進行資料探勘並將結果
資料探勘(KDD)初學基礎概要
資料探勘(KDD)Knowledge discovery in database 從各種各樣的應用資料中發現有趣資料模式。 資料來源包括:資料庫、資料倉庫、Web、其他資訊儲存庫。 可挖掘的資料型別:資
資料探勘(1)知識點總結
詳細文章轉自:https://blog.csdn.net/sinat_22594309/article/details/74923643資料探勘的一般過程包括以下這幾個方面:1、 資料預處理2、 資料探勘3、 後處理一、資料預處理主要手段分為兩種:選擇分析所需的資料物件和屬性
資料探勘(2)關聯規則FpGrowth演算法
介紹了關聯規則挖掘的一些基本概念和經典的Apriori演算法,Aprori演算法利用頻繁集的兩個特性,過濾了很多無關的集合,效率提高不少,但是我們發現Apriori演算法是一個候選消除演算法,每一次消除都需要掃描一次所有資料記錄,造成整個演算法在面臨大資料集時顯得無能
在R中使用支援向量機(SVM)進行資料探勘(上)
在R中,可以使用e1071軟體包所提供的各種函式來完成基於支援向量機的資料分析與挖掘任務。請在使用相關函式之前,安裝並正確引用e1071包。該包中最重要的一個函式就是用來建立支援向量機模型的svm()函
資料倉庫與資料探勘(三)
一·資料處理的兩種基本型別:操作型,分析型。 二·操作型數據和分析型資料的區別 操作型資料 分析型資料 細節的 綜合的,或提煉的 在存取瞬間是準確的(當前資料) 代表過去的資料(歷史資料) 可更新 不可更新 操作需求
資料探勘(三)分類模型的描述與效能評估,以決策樹為例
關於分類的第一部分我們要講一些關於分類的基本概念,然後介紹最基本的一種分類模型-決策樹模型,再基於此討論一下關於分類模型的效能評估。 =================================
跟我一起資料探勘(1)——建立資料倉庫的意義
資料倉庫,英文名稱為Data Warehouse,可簡寫為DW或DWH。資料倉庫是為企業所有級別的決策制定過程提供支援的所有型別資料的戰略集合。它是單個數據儲存,出於分析性報告和決策支援的目的而建立。 為企業提供需要業務智慧來指導業務流程改進和監視時間、成本、質量和控制。
淺談資料探勘(概論)
前言:學習資料的來源均出自,《圖解機器學習》-杉山將,中國工信出版集團。《資料探勘導論》-戴紅,清華大學出版書,資料探勘演算法原理與實現。 筆者自述:不知道什麼時候就開始有想學習資料探勘這一塊的知識,但是卻從來都沒有過開始。直到幾天前,突然鬼使神差的去了圖書館,找了基本資料
跟我一起資料探勘(20)——網站日誌挖掘
收集web日誌的目的 Web日誌挖掘是指採用資料探勘技術,對站點使用者訪問Web伺服器過程中產生的日誌資料進行分析處理,從而發現Web使用者的訪問模式和興趣愛好等,這些資訊對站點建設潛在有用的可理解的未知資訊和知識,用於分析站點的被訪問情況,輔助站點管理和決策支援等。 1、
新浪微博資料探勘(python)本週人們在討論的熱門話題的提取
分析熱門話題微博: (1)人們在討論(查詢)什麼話題(熱門話題) (2)該話題下的微博獲取 (3)那些人轉發了微博(涉及的人物) (4)轉發的時間和地點(話題的在時間和空間上的影響度) (5)網民對此持有什麼態度(情感分析) 開始之前,python的字典和列表的操作知識必須
KDD資料探勘(韓家煒)學習----導論
為什麼進行資料探勘 有需求,才會有解決需求的辦法。 對於工作,學習,生活中的各種海量資料,我們需要一種工具來從這些資料中發現有價值的資訊,把這些資料轉化成有組織的知識----需求產生 解決辦法:資料探勘 經典的例子:谷歌預測流感趨勢 資料庫系統技術的演變,如下圖
使用Weka進行資料探勘(Weka教程九)模型序列化/持久化儲存和載入
有很多時候,你在構建了一個模型並完成調優後,你很可能會想把這個模型存入到磁碟中,免得下次再重新訓練。尤其是神經網路、SVM等模型訓練時間非常長,重新訓練非常浪費時間。那麼怎麼持久化模型呢? 其實既然模型也是一個JAVA物件,那我就按照JAVA的序列化和反序列化
【強烈推薦】:關於系統學習資料探勘(Data Mining)的一些建議!!
微信公眾號 關鍵字全網搜尋最新排名 【機器學習演算法】:排名第一 【機器學習】:排名第一 【Python】:排名第三 【演算法】:排名第四 關於資料探勘 提到收據挖掘(Data Mining, DM),很多想學習的同學大多數都會問我: 什麼是資料探勘? 怎麼培養資料分析的能力? 如何成為一名資料科學家? (
python/pandas資料探勘(十四)-groupby,聚合,分組級運算
groupby import pandas as pd df = pd.DataFrame({'key1':list('aabba'), 'key2': ['one','two','one','two','one'],
使用Weka進行資料探勘(Weka教程六)Weka取樣Filter/Resample/SMOTE
資料預處理中,有一個原理很簡單但是非常重要的部分:取樣。良好的取樣可以讓資料集變得平衡,會大大的提高預測和分類的效果。 取樣是很複雜的一個領域,背後涉及到資料的分佈/資料的性質等很多內容。常見的取樣有: Simple Random Sampling(簡單隨機
資料探勘(機器學習)面試--SVM面試常考問題
應聘資料探勘工程師或機器學習工程師,面試官經常會考量面試者對SVM的理解。 以下是我自己在準備面試過程中,基於個人理解,總結的一些SVM面試常考問題(想到會再更新),如有錯漏,請批評指正。(大神請忽視) 轉載請註明出處:blog.csdn.net/szlcw1 SVM的原
python/pandas資料探勘(十四)-groupby,聚合,分組級運算---很全
groupby import pandas as pd df = pd.DataFrame({'key1':list('aabba'), 'key2': ['one','two','one','two','one'],
機器學習和資料探勘(主流演算法介紹)
對機器學習和資料探勘的科學定義是這樣的: 機器學習(Machine Learning, ML)是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、演算法複雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不