
大資料學習總結(一) 分散式Hadoop系統
阿新 • • 發佈:2019-01-09
Scala tips:在前面的類層次結構圖中可以看到,Null型別是所有AnyRef型別的子型別,也即它處於AnyRef類的底層,對應java中的null引用。而Nothing是scala類中所有類的子類,它處於scala類的最底層。
近期投入大資料組工作,就寫一寫總結,記錄一下學習過程。
Hadoop分散式系統主要涵蓋以下幾個模組:分散式檔案系統HDFS,經典計算模型MAP-REDUCE,資料倉庫工具Hive,分散式資料庫Hbase。
下面是HDFS結構體:
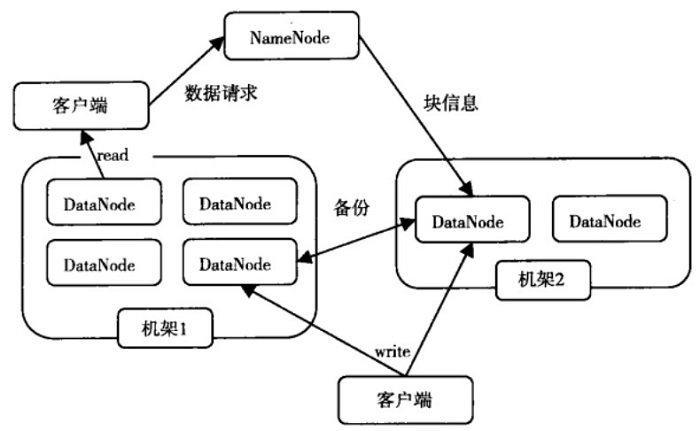
HDFS採用主從(Master/Slave)結構模型,一個HDFS叢集是由一個NameNode和若干個DataNode組成的(在最新的Hadoop2.2版本已經實現多個NameNode的配置-這也是一些大公司通過修改hadoop原始碼實現的功能,在最新的版本中就已經實現了)。NameNode作為主伺服器,管理檔案系統名稱空間和客戶端對檔案的訪問操作。DataNode管理儲存的資料。HDFS支援檔案形式的資料。
從內部來看,檔案被分成若干個資料塊,這若干個資料塊存放在一組DataNode上。NameNode執行檔案系統的名稱空間,如開啟、關閉、重新命名檔案或目錄等,也負責資料塊到具體DataNode的對映。DataNode負責處理檔案系統客戶端的檔案讀寫,並在NameNode的統一排程下進行資料庫的建立、刪除和複製工作。NameNode是所有HDFS元資料的管理者,使用者資料永遠不會經過NameNode。