
Tika文字提取工具的使用(word、pdf、excel等)
阿新 • • 發佈:2019-01-09
Tika是Apache的Lucene專案下面的子專案,在lucene的應用中可以使用tika獲取大批量文件中的內容來建立索引,非常方便,也很容易使用~
Tika的缺點就是都是依賴外部的jar包,導致jar包的重量太大,lucene的核心包只有1M,tika約20M,tika依賴的外部的jar包有多樣的功能,比如PDFBox和Apache POI能獲取文件的字型,佈置和內建圖片資訊,而Tika只是獲取文字資訊。但是這些外部的jar包又沒有把獲取文字資訊的抽離出一個單獨的jar包。
1、Tika的作用
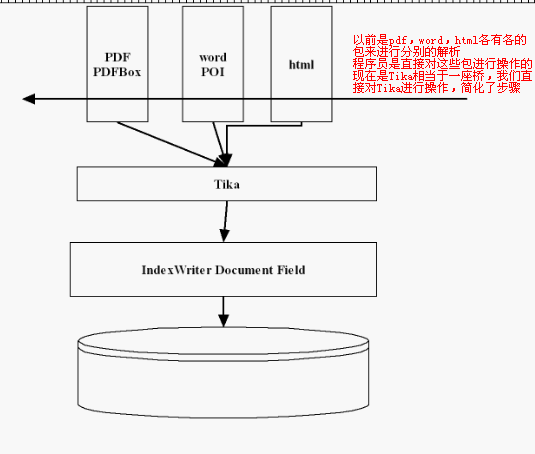
工程結構:
2、Tika的工具類
[java] view plaincopyprint- package org.lucene.util;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.IOException;
- import java.io.InputStream;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.document.Field;
- import org.apache.lucene.index.CorruptIndexException;
- import org.apache.lucene.index.IndexWriter;
- import org.apache.lucene.index.IndexWriterConfig;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.apache.lucene.store.LockObtainFailedException;
- import org.apache.lucene.util.Version;
- import org.apache.tika.Tika;
- import org.apache.tika.exception.TikaException;
- import org.apache.tika.metadata.Metadata;
- import org.apache.tika.parser.AutoDetectParser;
- import org.apache.tika.parser.ParseContext;
- import org.apache.tika.parser.Parser;
- import org.apache.tika.sax.BodyContentHandler;
- import org.xml.sax.ContentHandler;
- import org.xml.sax.SAXException;
- import com.chenlb.mmseg4j.analysis.MMSegAnalyzer;
- publicclass IndexUtil {
- /**
- * 直接讀取pdf建立索引,結果是索引建立成功了,但是索引儲存的資料卻是亂的
- */
- publicvoid index() {
- try {
- File f = new File("F:\\文件資料\\lucene_in_action中文版.pdf");
- Directory dir = FSDirectory.open(new File("f:/lucene"));
- IndexWriter writer = new IndexWriter(dir,new IndexWriterConfig(Version.LUCENE_35, new MMSegAnalyzer()));
- writer.deleteAll();
- Document doc = new Document();
- doc.add(new Field("content",new Tika().parse(f)));
- writer.addDocument(doc);
- writer.close();
- } catch (CorruptIndexException e) {
- e.printStackTrace();
- } catch (LockObtainFailedException e) {
- e.printStackTrace();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- /**
- * 根據Tika得到文件的內容,這種比下面那種獲取的要簡單很多,
- * 據tika的文件上說,效率沒有下面的那種高,可能封裝的比較多
- * @param f
- * @return
- * @throws IOException
- * @throws TikaException
- */
- public String tikaTool(File f) throws IOException, TikaException {
- Tika tika = new Tika();
- Metadata metadata = new Metadata();
- metadata.set(Metadata.AUTHOR, "空號");//重新設定文件的媒體內容
- metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
- String str = tika.parseToString(new FileInputStream(f),metadata);
- for(String name:metadata.names()) {
- System.out.println(name+":"+metadata.get(name));
- }
- return str;
- }
- /**
- * 根據Parser得到文件的內容
- * @param f
- * @return
- */
- public String fileToTxt(File f) {
- Parser parser = new AutoDetectParser();//自動檢測文件型別,自動建立相應的解析器
- InputStream is = null;
- try {
- Metadata metadata = new Metadata();
- metadata.set(Metadata.AUTHOR, "空號");//重新設定文件的媒體內容
- metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
- is = new FileInputStream(f);
- ContentHandler handler = new BodyContentHandler();
- ParseContext context = new ParseContext();
- context.set(Parser.class,parser);
- parser.parse(is,handler, metadata,context);
- for(String name:metadata.names()) {
- System.out.println(name+":"+metadata.get(name));
- }
- return handler.toString();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- } catch (TikaException e) {
- e.printStackTrace();
- } finally {
- try {
- if(is!=null) is.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- returnnull;
- }
- }
package org.lucene.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.util.Version;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.ContentHandler;
import org.xml.sax.SAXException;
import com.chenlb.mmseg4j.analysis.MMSegAnalyzer;
public class IndexUtil {
/**
* 直接讀取pdf建立索引,結果是索引建立成功了,但是索引儲存的資料卻是亂的
*/
public void index() {
try {
File f = new File("F:\\文件資料\\lucene_in_action中文版.pdf");
Directory dir = FSDirectory.open(new File("f:/lucene"));
IndexWriter writer = new IndexWriter(dir,new IndexWriterConfig(Version.LUCENE_35, new MMSegAnalyzer()));
writer.deleteAll();
Document doc = new Document();
doc.add(new Field("content",new Tika().parse(f)));
writer.addDocument(doc);
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 根據Tika得到文件的內容,這種比下面那種獲取的要簡單很多,
* 據tika的文件上說,效率沒有下面的那種高,可能封裝的比較多
* @param f
* @return
* @throws IOException
* @throws TikaException
*/
public String tikaTool(File f) throws IOException, TikaException {
Tika tika = new Tika();
Metadata metadata = new Metadata();
metadata.set(Metadata.AUTHOR, "空號");//重新設定文件的媒體內容
metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
String str = tika.parseToString(new FileInputStream(f),metadata);
for(String name:metadata.names()) {
System.out.println(name+":"+metadata.get(name));
}
return str;
}
/**
* 根據Parser得到文件的內容
* @param f
* @return
*/
public String fileToTxt(File f) {
Parser parser = new AutoDetectParser();//自動檢測文件型別,自動建立相應的解析器
InputStream is = null;
try {
Metadata metadata = new Metadata();
metadata.set(Metadata.AUTHOR, "空號");//重新設定文件的媒體內容
metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
is = new FileInputStream(f);
ContentHandler handler = new BodyContentHandler();
ParseContext context = new ParseContext();
context.set(Parser.class,parser);
parser.parse(is,handler, metadata,context);
for(String name:metadata.names()) {
System.out.println(name+":"+metadata.get(name));
}
return handler.toString();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (TikaException e) {
e.printStackTrace();
} finally {
try {
if(is!=null) is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
3、測試類 [java] view plaincopyprint?
- package org.lucene.test;
- import java.io.File;
- import java.io.IOException;
- import org.apache.tika.exception.TikaException;
- import org.junit.Test;
- import org.lucene.util.IndexUtil;
- publicclass TestIndex {
- @Test
- publicvoid testIndex() {
- IndexUtil iu = new IndexUtil();
- iu.index();
- }
- @Test
- publicvoid testTika01() {
- IndexUtil iu = new IndexUtil();
- System.out.println(iu.fileToTxt(new File("F:\\文件資料\\lucene_in_action中文版.pdf")));
- }
- @Test
- publicvoid testToka02() throws IOException, TikaException {
- IndexUtil iu = new IndexUtil();
- System.out.println(iu.tikaTool(new File("F:\\文件資料\\初級SQL開發指南.doc")));
- }
- }
package org.lucene.test;
import java.io.File;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.junit.Test;
import org.lucene.util.IndexUtil;
public class TestIndex {
@Test
public void testIndex() {
IndexUtil iu = new IndexUtil();
iu.index();
}
@Test
public void testTika01() {
IndexUtil iu = new IndexUtil();
System.out.println(iu.fileToTxt(new File("F:\\文件資料\\lucene_in_action中文版.pdf")));
}
@Test
public void testToka02() throws IOException, TikaException {
IndexUtil iu = new IndexUtil();
System.out.println(iu.tikaTool(new File("F:\\文件資料\\初級SQL開發指南.doc")));
}
}