
《Hadoop》之"踽踽獨行"(七)Hadoop的偽分散式叢集搭建
在上一章我給大家介紹了Hadoop的單節點叢集本地模式的搭建,在這一章中,我們來了解一下Hadoop偽分散式叢集的搭建與用途。
一、Hadoop偽分散式叢集(pseudo distributed cluster)
1、簡介
hadoop的pseudo distributed cluster(偽分散式叢集),就是在一臺主機上模擬多個主機。即hadoop的守護程式在本地計算機(這個指的是Linux虛擬機器)上執行,模擬叢集環境,並且是相互獨立的Java程序。
在這種模式下,Hadoop使用的是分散式檔案系統,各個作業也是由ResourceManager服務來管理的獨立程序。
比local mode 多了程式碼除錯功能,允許檢查記憶體使用情況,HDFS輸入輸出,以及其他的守護程序互動。
2、用途
類似於完全分散式模式下的叢集。因此,這種模式常用來開發測試Hadoop程式的執行是否正確。
二、搭建偽分散式
安裝前說明:
1、普通使用者:hyxy
2、建立~/apps目錄,用於管理軟體包
3、將jdk-7u80-linux-x64.tar.gz 和 hadoop-2.7.3.tar.gz 上傳到/home/hyxy/apps/目錄下
第一步、安裝JDK,配置環境變數
使用tar指令將jdk的軟體包解壓到apps目錄下,後刪除軟體包,然後建立一個軟連結jdk.soft
[[email protected] apps ]$ tar -zxv -f jdk-7u80-linux-x64.tar.gz。
[[email protected] apps]$ rm jdk-7u80-linux-x64.tar.gz #解壓後刪除軟體包,節省空間
[[email protected] apps]$ ln -s jdk1.7.0_80/ jdk.soft #軟連結叫jdk.soft我們在~/.bash_profile配置檔案內,配置jdk的環境變數,然後重新載入配置檔案,並檢測java和javac兩個命令
[[email protected] apps]$ vim ~/.bash_profile
............
PATH=$PATH:$HOME/bin #可要可不要
# jdk environment
JAVA_HOME=/home/hyxy/apps/jdk.soft #配置環境變數JAVA_HOME
PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH #千萬別忘記拼接$PATH
export PATH JAVA_HOME
[[email protected] apps]$ source ~/.bash_profile #重新載入配置檔案
[[email protected] apps]$ java -version #檢測jdk版本
java version "1.7.0_80"
............
[[email protected] apps]$ javac #測試javac命令第二步、解壓hadoop,配置環境變數
使用tar指令解壓hadoop軟體包,然後刪除軟體包,再建立軟連結hadoop.soft
[[email protected] apps]$ tar -zxv -f hadoop-2.7.3.tar.gz #1.解壓軟體包
[[email protected] apps]$ rm hadoop-2.7.3.tar.gz #2.刪除軟體包
[[email protected] apps]$ ln -s hadoop-2.7.3/ hadoop.soft #3.建立軟連結hadoop.soft
[[email protected] apps]$ ll
drwxr-xr-x. 9 hyxy hyxy 4096 8月 18 2016 hadoop-2.7.3
lrwxrwxrwx. 1 hyxy hyxy 13 1月 8 11:04 hadoop.soft -> hadoop-2.7.3/
drwxr-xr-x. 8 hyxy hyxy 4096 4月 11 2015 jdk1.7.0_80
lrwxrwxrwx. 1 hyxy hyxy 12 1月 8 10:45 jdk.soft -> jdk1.7.0_80/在~/.bash_profile配置檔案內,配置hadoop的環境變數,然後重新載入配置檔案,並檢測hadoop命令
[[email protected] apps]$ vim ~/.bash_profile
............... #前面的內容省略了
...............
# hadoop environment #追加hadoop環境變數
HADOOP_HOME=/home/hyxy/apps/hadoop.soft #配置HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH #配置path,千萬別忘記拼接$PATH
export PATH HADOOP_HOME
[[email protected] apps]$ source ~/.bash_profile #重新載入配置檔案
[[email protected] apps]$ hadoop version #測試hadoop命令
Hadoop 2.7.3第三步、修改hadoop偽分散式叢集的配置資訊
首先我們進入hadoop的etc/hadoop目錄下:
[[email protected] apps]$ cd hadoop.soft/etc/hadoop/ #檢查你自己的路徑,不要盲目的抄寫
[[email protected] hadoop]$ ls #檢視一下目錄下的配置檔案
capacity-scheduler.xml hadoop-env.cmd hadoop-policy.xml httpfs-signature.secret kms-log4j.properties mapred-env.sh ssl-client.xml.example yarn-site.xml
configuration.xsl hadoop-env.sh hdfs-site.xml httpfs-site.xml kms-site.xml mapred-queues.xml.template ssl-server.xml.example
container-executor.cfg hadoop-metrics2.properties httpfs-env.sh kms-acls.xml log4j.properties mapred-site.xml.template yarn-env.cmd
core-site.xml hadoop-metrics.properties httpfs-log4j.properties kms-env.sh mapred-env.cmd slaves yarn-env.sh
修改core-site.xml
[[email protected] hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> #屬性: 預設的分散式檔案系統
<value>hdfs://localhost:9000</value> #配置本地地址,port:9000
</property>
</configuration>
修改hdfs-site.xml
[[email protected] hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name> #屬性:副本數量
<value>1</value> #給個值 1
</property>
</configuration>
修改hadoop-env.sh,設定JAVA_HOME=/home/hyxy/apps/jdk.soft
[[email protected] hadoop]$ vim hadoop-env.sh
............................... #省略了
# The java implementation to use.
export JAVA_HOME=/home/hyxy/apps/jdk.soft #修改成jdk的安裝路徑
第四步:配置SSH無密登陸
首先檢視一下是否安裝了ssh軟體:rpm -qa | grep ssh。如果沒安裝,就先安裝此軟體。安裝了,就直接進行下面操作。
首先,驗證一下ssh localhost,是否需要密碼:
[[email protected] hadoop]$ ssh localhost
............
[email protected]'s password: #是需要密碼的然後配置無密登入。(再次強調,使用普通使用者,不要使用root使用者)
1、生成私鑰和公鑰一對金鑰。輸入命令: ssh-keygen -t rsa 。然後一路回車即可。
[[email protected] ~]$ cd
[[email protected] ~]$ ssh-keygen -t rsa #執行這個指令串 生成金鑰
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hyxy/.ssh/id_rsa): #回車
Enter passphrase (empty for no passphrase): #回車
Enter same passphrase again: #回車
Your identification has been saved in /home/hyxy/.ssh/id_rsa. #私鑰檔案
Your public key has been saved in /home/hyxy/.ssh/id_rsa.pub. #公鑰檔案
The key fingerprint is:
85:b7:6b:04:fe:cd:da:85:47:72:5e:ff:1f:6b:92:74 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| |
| . |
| o o |
| . + . |
| S o . o .|
| o + B E.|
| + = *..|
| . o = .+|
| . . o.+|
+-----------------+
[[email protected] ~]$
2、進入.ssh目錄,將公鑰檔案更名為authorized_keys檔案,即可實現ssh連線自己不再需要密碼。確保authorized_keys的許可權為600。
[[email protected] ~]$ cd ~/.ssh #進入.ssh目錄
[[email protected] .ssh]$ ll
-rw-------. 1 hyxy hyxy 1675 1月 8 14:54 id_rsa
-rw-r--r--. 1 hyxy hyxy 393 1月 8 14:54 id_rsa.pub
[[email protected] .ssh]$ mv id_rsa.pub authorized_keys #更名操作
[[email protected] .ssh]$ chmod 600 authorized_keys #更改許可權3、結果驗證:
[[email protected] ~]$ ssh localhost #驗證localhost
Last login: Tue Jan 8 14:57:02 2019 from localhost
[[email protected] ~]$ ssh master #驗證主機名登入,前提得在/etc/hosts繫結主機名和ip
Last login: Tue Jan 8 14:57:16 2019 from localhost
第五步:格式化分散式檔案系統
使用hdfs namenode -format 來格式化分散式檔案系統
[[email protected] ~]$ hdfs namenode -format
第六步:啟動HDFS
開啟namenode執行緒和datanode執行緒等
[[email protected] ~]$ start-dfs.sh
第七步:檢視執行緒
正常應該至少有四個執行緒,就對了
[[email protected] ~]$ jps
30591 Jps
30194 NameNode
30481 SecondaryNameNode
30288 DataNode
第八步:使用瀏覽器進行訪問hadoop偽分佈叢集
使用linux虛擬機器上的火狐瀏覽器,訪問地址:http://localhost:50070
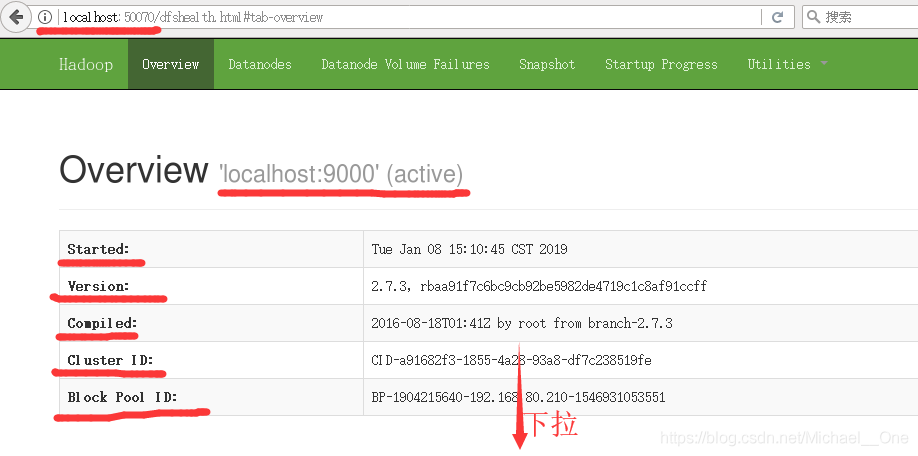

能看到上述資訊,1個Live Nodes,就保沒錯了。偽分佈搭建完畢。如果還想配置YARN環境的,可以參考官網:https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html,這個連結的最下面就是YARN no a Single node的配置了。
三、程式測試
偽分散式叢集搭建好了,我們來執行一個mapreduce程式試試。
第一步:在分散式檔案系統上建立多級目錄/hyxy/input
[[email protected] ~]$ hdfs dfs -mkdir -p /hyxy/input
第二步:在本地建立一個檔案file,內容如下:
[[email protected] ~]$ echo hello world hello kitty you are good >> file
第三步:將file 上傳到分散式檔案系統/hyxy/input目錄下,然後檢視一下
[[email protected] ~]$ hdfs dfs -put file /hyxy/input
[[email protected] ~]$ hdfs dfs -ls /hyxy/input/
Found 1 items
-rw-r--r-- 1 hyxy supergroup 37 2019-01-08 15:46 /hyxy/input/file第四步:在分散式檔案系統上建立目錄output。用於儲存輸出資料。
[[email protected] ~]$ hdfs dfs -mkdir /hyxy/output第五步:使用hadoop自帶的單詞統計mapreduce程式,統計file檔案的單詞
[[email protected] ~]$ hadoop jar ./apps/hadoop.soft/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /hyxy/input /hyxy/output/count
第六步:檢視統計結果
[[email protected] ~]$ hdfs dfs -cat /hyxy/output/count/*
are 1
good 1
hello 2
kitty 1
world 1
you 1可以在瀏覽器上檢視分散式檔案系統
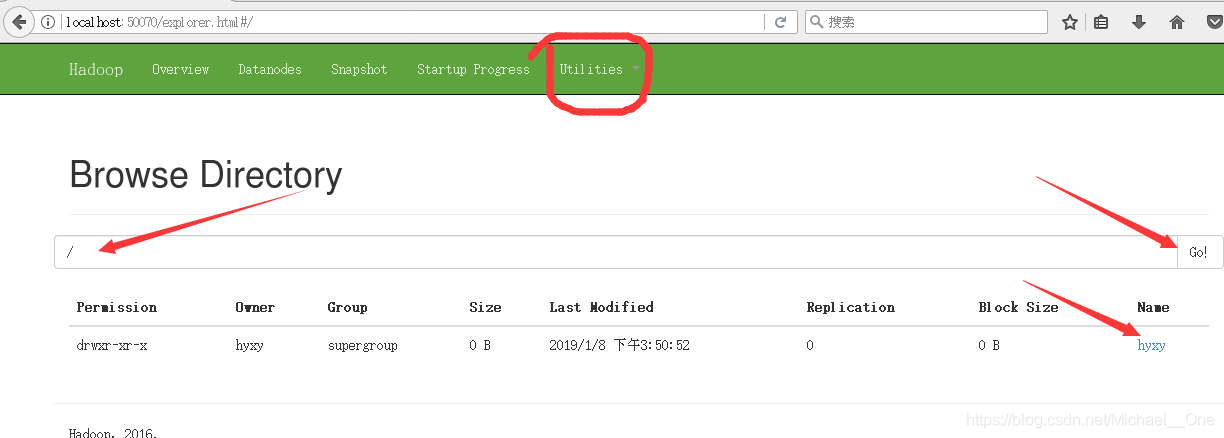
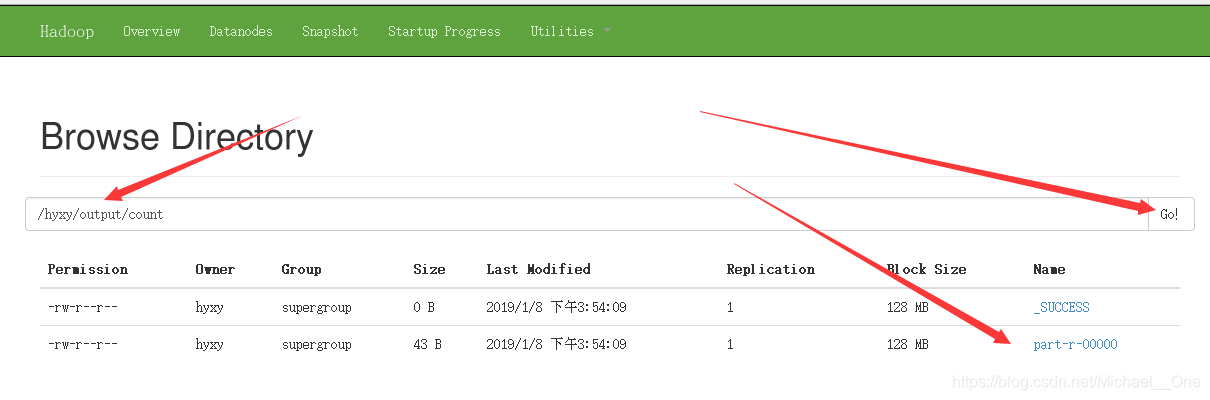
ok。到此為止,偽分散式搭建和案例測試,都完美收官,吼吼吼
-------------------------------如有疑問,敬請留言吧--------------------------------------------------------------------