【集體智慧程式設計】第三章、發現群組
一、前言
本章中,我們將學習到如下內容:從各種不同的來源中構造演算法所需的資料;兩種不同的聚類演算法;更多有關距離度量(distance metrics)的知識;簡單的圖形視覺化程式碼,用以觀察所生成的群組;最後,我們還會學習如何將異常複雜的資料集投影到二維空間中。
聚類時常被用於資料量很大(data-intensive)的應用中。跟蹤消費者購買行為的零售商們,除了利用常規的消費者統計訊息外,還可以利用這些資訊自動檢測出具有相似購買模式的消費者群體。年齡和收入都相仿的人也許會有迥然不同的著裝風格,但是通過使用聚類演算法,我們就可以找到“時裝島嶼”,並據此開發出相應的零售或市場策略。聚類在計量生物學領域裡也有大量的運用,我們用它來尋找具有相似行為的基因組,相應的研究結果可以表明,這些基因組中的基因會以同樣的方式響應外界的活動,或者表明它們是相同生化通路中的一部分。
二、監督學習和無監督學習
(1)監督學習
利用樣本輸入和期望輸出來學習如何預測的技術被稱為監督學習法(supervised learning methods)。常用的監督學習法包括:神經網路、決策樹、向量支援機以及貝葉斯過濾。採用這些方法的應用程式,會通過檢查一組輸入和期望的輸出來進行“學習”。當我們想要利用這些方法中的任何一種來提取資訊時,我們可以傳入一組輸入,然後期望應用程式能夠根據其此前學到的知識來產生一個輸出。
(2)無監督學習
聚類是無監督學習(unsupervised learning)的一個例子。與神經網路或決策樹不同,無監督學習演算法不是利用帶有正確答案的樣本資料進行“訓練”。它們的目的是要在一組資料中找尋某種結構,而這些資料本身並不是我們要找的答案。在前面提到的時裝的例子中,聚類的結果不會告訴零售商每一位顧客可能會買什麼,也不會預測新來的顧客適合哪種時尚。聚類演算法的目標是採集資料,然後從中找出不同的群組。其他無監督學習的例子還包括非負矩陣因式分解(non-negative matrix factorization)和自組織對映(self-organizing maps)。
三、對訂閱源中的單詞進行計數
幾乎所有的部落格都可以線上閱讀,或者通過RSS訂閱源進行閱讀。RSS訂閱源是一個包含部落格及其所有文章條目資訊的簡單的XML文件。為了給每個部落格中的單詞計數,首先第一步就是要解析這些訂閱源。所幸的是,有一個非常不錯的程式能夠完成這項工作,它就是Universal Feed Parser。從python的包或者使用pip安裝feedparser包即可。
有了Universal Feed Parser,我們就可以很輕鬆地從任何RSS或Atom訂閱源中得到標題、連結和文章的條目了。下一步,我們來編寫一個從訂閱源中提取所有單詞的函式。新建一個feedvector.py,將下列程式碼加入。
import feedparser
import re
# 返回一個RSS訂閱源的標題和包含單詞計數情況的字典
def getwordcounts(url):
# 解析訂閱源
d = feedparser.parse(url)
wc = {}
# 迴圈遍歷所有的文章條目
for e in d.entries:
if 'summary' in e:
summary = e.summary
else:
summary = e.description
# 提取一個單詞列表
words = getwords(e.title+''+summary)
for word in words:
wc.setdefault(word, 0)
wc[word] += 1
return d.feed.title, wc每個RSS和Atom訂閱源都會包含一個標題和一組文章條目。通常,每個文章條目都有一段摘要,或者是包含了條目中實際文字的描述性標籤。函式getwordcounts將摘要傳給函式getwords,後者會將其中所有的HTML標記剝離掉,並以非字母字元作為分隔符拆分出單詞,再將給過以列表的形式加以返回。
def getwords(html):
# 去除所有HTML標記
txt = re.compile(r'<[^>]+>').sub('', html)
# 利用所有非字母字元拆分出單詞
words = re.compile(r'[^A-Z^a-z]+').split(txt)
# 轉化成小寫形式
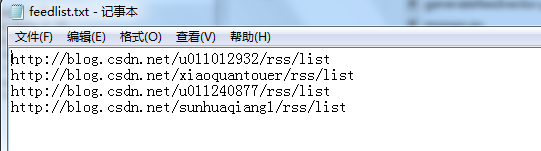
return [word.lower() for word in words if word != '']為了開始下一步工作,我們現在需要一個訂閱源的列表。這裡我手動將一些部落格的RSS訂閱地址放在了一個叫feedlist.txt 的檔案中,每一行對應一個URL。如果我們擁有自己的部落格,或者有一些部落格是我們特別喜歡的,同時很想看看它們和某些熱門部落格的對比情況如何,那麼我們也可以將這些部落格的URL加入到檔案中。
將下列程式碼加入到feedvector.py 檔案的末尾
apcount = {}
wordcounts = {}
feedlist=[line for line in file('feedlist.txt')]
for feedurl in feedlist:
title, wc = getwordcounts(feedurl)
wordcounts[title] = wc
for word, count in wc.items():
apcount.setdefault(word, 0)
if count>1:
apcount[word] += 1下一步,我們來建立一個單詞列表,將其實際用於針對每個部落格的單詞計數。因為像“the”這樣的單詞幾乎到處都是,而像“film-flam”這樣的單詞則有可能只出現在個別部落格中,所以通過只選擇介於某個百分比範圍內的單詞,我們可以減少需要考查的單詞總量。在本例中,我們可以將10%定為下屆,將50%定為上界,不過加入你發現有過多常見或鮮見的單詞出現,不妨嘗試一下不同的邊界值。
wordlist = []
for w,bc in apcount.items():
frac = float(bc)/len(feedlist)
if frac > 0.1 and frac < 0.5:
wordlist.append(w)最後,我們利用上述單詞列表和部落格列表來建立一個文字檔案,其中包含一個大的矩陣,記錄著針對每個部落格的所有單詞的統計情況:
out = file('blogdata.txt', 'w')
out.write('Blog')
for word in wordlist:
out.write('\t%s' % word)
out.write('\n')
for blog, wc in wordcounts.items():
out.write(blog)
for word in wordlist:
if word in wc:
out.write('\t%d' % wc[word])
else:
out.write('\t0')
out.write('\n')這一過程最終將會生成一個名為blogdata.txt 的輸出檔案。如下所示:

驗證一下,是否包含一個以製表符分割的表格,其中的每一列對應一個單詞,每一行對應一個部落格。本章中出現的函式都將統一採用這一檔案格式,日後我們還可以據此來構造新的資料集,我們甚至還可以將一個電子表格另存為如此格式的文字檔案,並沿用本章中的演算法對其實施聚類。
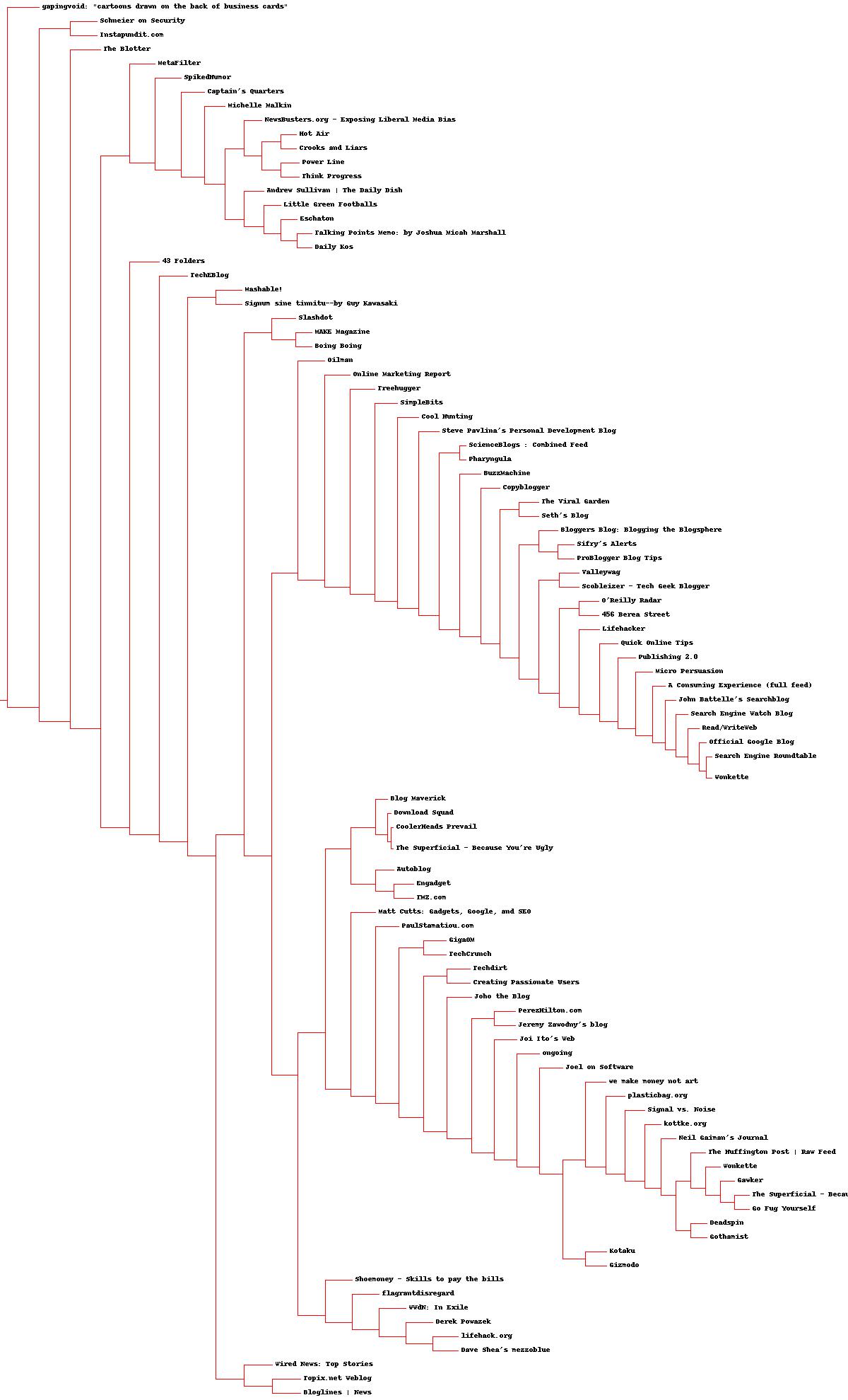
四、分級聚類
分級聚類通過連續不斷地將最為相似的群組兩兩合併,來構造出一個群組的層級結構。其中的每個群組都是從單一元素開始的,在本章的例子中,這個單一元素就是部落格。在每次迭代的過程中,分級聚類演算法會計算每兩個群組間的距離,並將距離最近的兩個群組合併成一個新的群組。這一過程會一直重複下去,直到只剩一個群組為止。如下圖所示:
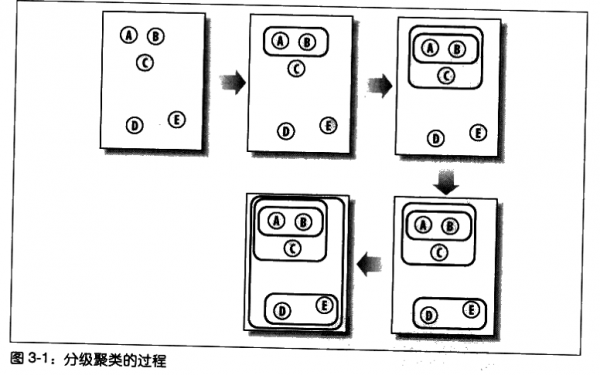
在上圖中,元素的相似程度是通過它們的相對位置來體現的---兩個元素距離越近,它們就越相似。開始時,群組還只有一個元素。在第二步中,我們可以看到A和B,這兩個緊靠在一起的元素,已經合併成了一個新的群組,新群組所在的位置位於這兩個元素的中間。在第三步中,新群組又與C進行了合併。因為D和E現在是距離最近的兩個元素,所以它們共同構成了一個新的群組。最後一步將剩下的兩個群組合併到了一起。
通常,待分級聚類完成之後,我們可以採用一種圖形化的方式來展現所得的結果,這種圖被稱為樹狀圖,圖中顯示了按層級排列的節點。上述例子中的樹狀圖如下圖所示:
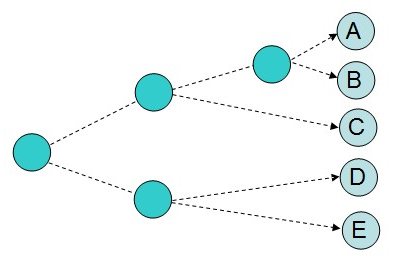
樹狀圖是分級聚類的一種視覺化形式
樹狀圖不僅可以利用連線來表達每個聚類的構成情況,而且還可以利用距離來體現構成聚類的各元素間相隔的遠近。在圖中,聚類AB與A和B之間的距離要比聚類DE與D和E之間的距離更加接近。這種圖形繪製方式能夠幫助我們有效地確定一個聚類中各元素間的相似程度,並以此來指示聚類的緊密程度。
本節我們將示範如何對部落格資料集進行聚類,以構造部落格的層級結構;如果構造成功,我們將實現將主題對部落格進行分組。首先,我們需要一個方法來載入資料檔案。請新建一個名為clusters.py的檔案,將下列函式加入其中:
def readfile(filename):
lines = [line for line in file(filename)]
# 第一行是列標題
colnames = lines[0].strip().split('\t')[1:]
rownames = []
data = []
for line in lines[1:]:
p = line.strip().split('\t')
# 每行的第一列是行名
rownames.append(p[0])
# 剩餘部分就是該行對應的資料
data.append([float(x) for x in p[1:]])
return rownames, colnames, data上述函式將資料集中的頭一行資料讀入了一個代表列名的列表,並將最左邊一列讀入了一個代表行名的列表,最後它又將剩下的所有資料都放入了一個大列表,其中的每一項對應於資料集中的一行資料。資料集中任一單元格內的計數值,都可以由一個行號和列號來唯一定位,此行號和列號同時還對應於列表rownames和colnames中的索引。
下一步我們來定義緊密度。我們曾在第二章討論過這個問題,那一章中我們以歐幾里德距離和皮爾遜相關度為例對兩位影評者的相似程度進行了評論。在本章的例子中,一些部落格比其他部落格包含更多的文章條目,或者文章條目的長度比其他部落格的更長,這樣會導致這些部落格在總體上比其他部落格包含更多的詞彙。皮爾遜相關度可以糾正這一問題,因為它判斷的其實是兩組資料與某條直線的擬合程度。此處,皮爾遜相關度的計算程式碼將接受兩個數字列表作為引數,並返回這兩個列表的相關度分值:
def pearson(v1, v2):
# 簡單求和
sum1 = sum(v1)
sum2 = sum(v2)
# 求平方和
sum1Sq = sum([pow(v, 2) for v in v1])
sum2Sq = sum([pow(v, 2) for v in v2])
# 求乘積之和
pSum = sum([v1[i]*v2[i] for i in range(len(v1))])
# 計算 r (Pearson score)
num = pSum-(sum1*sum2/len(v1))
den = sqrt((sum1Sq-pow(sum1, 2)/len(v1))*(sum2Sq-pow(sum2, 2)/len(v1)))
if den == 0:
return 0
return 1.0-num/den請記住皮爾遜相關度的計算結構在兩者完全匹配的情況下為1.0, 而在兩者毫無關係的情況下則為0.0。上述程式碼的最後一行,返回的是以1.0 減去皮爾遜相關度之後的結果,這樣做的目的是為了讓相似度越大的兩個元素之間的距離變得更小。
分級聚類演算法中的每一個聚類,可以是樹種的枝節點,也可以是與資料集中實際資料行相對應的葉節點(在本例中,即為一個部落格)。每一個聚類還包含了指示其位置的資訊,這一資訊可以是來自葉節點的行資料,也可以是來自枝節點的經合併後的資料。我們可以新建一個bicluster類,將所有這些屬性存放其中,並以此來描述這棵層級樹。在cluster.py中新建一個類,以代表“聚類”這一型別
class bicluster:
def __init__(self, vec, left=None, right=None, distance=0.0, id=None):
self.left = left
self.right = right
self.vec = vec
self.id = id
self.distance = distance分級聚類演算法以一組對應於原始資料項的聚類開始。函式的主迴圈部分會嘗試每一組可能的配對並計算它們的相關度,以此來找出最佳配對。最佳配對的兩個聚類會被合併成一個新的聚類。新生成的聚類中所包含的資料,等於將兩個舊聚類的資料求均值之後得到的結果。這一過程會一直重複下去,直到只剩下一個聚類為止。由於整個計算過程可能會非常耗時,所以不妨將每個配對的相關度計算結果儲存起來,因為這樣的計算會反覆發生,直到配對中的某一項被合併到另一個聚類中為止。
將hcluster演算法加入clusters.py 檔案中:
def hcluster(rows, distance=pearson):
distances={}
currentclustid=1
# 最開始的聚類就是資料集中的行
clust=[bicluster(rows[i], id=i) for i in range(len(rows))]
while len(clust) > 1:
lowestpair = (0,1)
closest = distance(clust[0].vec, clust[1].vec)
# 遍歷每一個配對,尋找最小距離
for i in range(len(clust)):
for j in range(i+1, len(clust)):
# 用distances來快取距離的計算值
if (clust[i].id, clust[j].id) not in distances:
distances[(clust[i].id, clust[j].id)] = distance(clust[i].vec, clust[j].vec)
d = distances[(clust[i].id, clust[j].id)]
if d < closest:
closest = d
lowestpair = (i, j)
# 計算兩個聚類的平均值
mergevec=[
(clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0
for i in range(len(clust[0].vec))]
# 建立新的聚類
newcluster = bicluster(mergevec, left=clust[lowestpair[0]],
right=clust[lowestpair[1]],
distance=closest, id=currentclustid)
# 不在原始集合中的聚類,其id為負數
currentclustid -= 1
del clust[lowestpair[1]]
del clust[lowestpair[0]]
clust.append(newcluster)
return clust[0]因為每個聚類都指向構造該聚類時被合併的另兩個聚類,所以我們可以遞迴搜尋由該函式最終返回的聚類,以重建所有的聚類及葉節點。執行分級聚類演算法:
blognames, words, data = readfile('blogdata.txt')
clust = hcluster(data)執行過程也許會花費一些時間。將距離值儲存起來可以極大地加快執行速度,但是對於演算法而言,計算每一對部落格的相關度仍然是必要的。為了加快這一過程,我們可藉助外部庫來計算距離值。為了檢視執行的結果,我們可以編寫一個簡單的函式,遞迴遍歷聚類樹,並將其以類似檔案系統層級結果的形式打印出來。將printclust函式新增到clusters.py 中:
def printclust(clust, labels=None, n=0):
# 利用縮排去來建立層級佈局
for i in range(n):
print ' ',
if clust.id < 0:
# 負數標記代表這是一個分支
print '-'
else:
# 正數標記代表這是一個葉節點
if labels==None:
print clust.id
else:
print labels[clust.id]
# 現在開始列印右側分支和左側分支
if clust.left != None:
printclust(clust.left, labels=labels, n=n+1)
if clust.right != None:
printclust(clust.right, labels=labels, n=n+1)這樣的輸出結果看起來不是非常的美觀,並且對於讀取部落格列表這樣的大資料集而言,這樣做法會比較困難,不過它確實為我們提供了一個有關聚類演算法是否工作良好的大體感覺。在下一節,我們將會看到如何建立一個圖形版本的聚類樹,這棵樹更容易閱讀,而且能夠按比例縮放,從而可以顯示出每個聚類的整體佈局。
呼叫上述函式:
printclust(clust, labels=blognames)輸出如下圖所示:

因為我這裡部落格列表中的部落格數量太少,所以畫出來的樹不是很明顯。可以在一開始的feedlist 中多新增些部落格的url。
五、繪製樹狀圖
使用本書給的blogdata.txt來繪製樹狀圖,程式碼如下:
def getheight(clust):
# 這是一個葉節點嗎?若是,則高度為1
if clust.left==None and clust.right==None:
return 1
# 否則,高度為每個分支的高度之和
return getheight(clust.left)+getheight(clust.right)
def getdepth(clust):
# 一個葉節點的距離是0.0
if clust.left==None and clust.right==None:
return 0
# 一個枝節點的距離等於左右兩側分支中距離較大者
# 加上該枝節點自身的距離
return max(getdepth(clust.left), getdepth(clust.right))+clust.distance
def drawdendrogram(clust, labels, jpeg='clusters.jpg'):
# 高度和寬度
h = getheight(clust)*20
w = 1200
depth = getdepth(clust)
# 由於寬度是固定的,因此我們需要對距離值做相應的調整
scaling = float(w-150)/depth
# 新建一個白色背景的圖片
img = Image.new('RGB', (w, h), (255, 255, 255))
draw = ImageDraw.Draw(img)
draw.line((0, h/2, 10, h/2), fill=(255, 0, 0))
# 畫第一個節點
drawnode(draw, clust, 10, (h/2), scaling, labels)
img.save(jpeg, 'JPEG')
def drawnode(draw, clust, x, y, scaling, labels):
if clust.id<0:
h1 = getheight(clust.left)*20
h2 = getheight(clust.right)*20
top = y-(h1+h2)/2
bottom = y+(h1+h2)/2
# 線的長度
l1 = clust.distance*scaling
# 聚類到其子節點的垂直線
draw.line((x, top+h1/2, x, bottom-h2/2), fill=(255, 0, 0))
# 連線左側節點的水平線
draw.line((x, top+h1/2, x+l1, top+h1/2), fill=(255, 0, 0))
# 連線右側節點的水平線
draw.line((x, bottom-h2/2, x+l1, bottom-h2/2), fill=(255, 0, 0))
# 呼叫函式繪製左右節點
drawnode(draw, clust.left, x+l1, top+h1/2, scaling, labels)
drawnode(draw, clust.right, x+l1, bottom-h2/2, scaling, labels)
else:
# 如果這是一個葉節點,則繪製節點的標籤
draw.text((x+5, y-7), labels[clust.id], (0, 0, 0))
blognames, words, data = readfile('blogdata.txt')
clust = hcluster(data)
# printclust(clust, labels=blognames)
drawdendrogram(clust, blognames, jpeg='blogclust.jpg')畫出來的圖如下所示: