
非同步機制(Asynchronous) -- (二)非同步訊息機制兼談Hadoop RPC
上篇說了半天,卻迴避了一個重要的問題:為什麼要用非同步呢,它有什麼樣的好處?坦率的說,我對這點的認識不是太深刻(套句俗語,只可意會,不可言傳)。還是舉個例子吧:
比如Client向Server傳送一個request,Server收到後需要100ms的處理時間,為了方便起見,我們忽略掉網路的延遲,並且,我們認為Server端的處理能力是無窮大的。在這個use case下,如果採用同步機制,即Client傳送request -> 等待結果 -> 繼續傳送,那麼,一個執行緒一秒鐘之內只能夠傳送10個request,如果希望達到10000 request/s的傳送壓力,那麼Client端就需要建立1000個執行緒,而這麼多執行緒的context switch就成為client的負擔了。而採用非同步機制,就不存在這個問題了。Client將request傳送出去後,立即傳送下一個request,理論上,它能夠達到網絡卡傳送資料的極限。當然,同時需要有機制不斷的接收來自Server端的response。
以上的例子其實就是這篇的主題,非同步的訊息機制,基本的流程是這樣的:
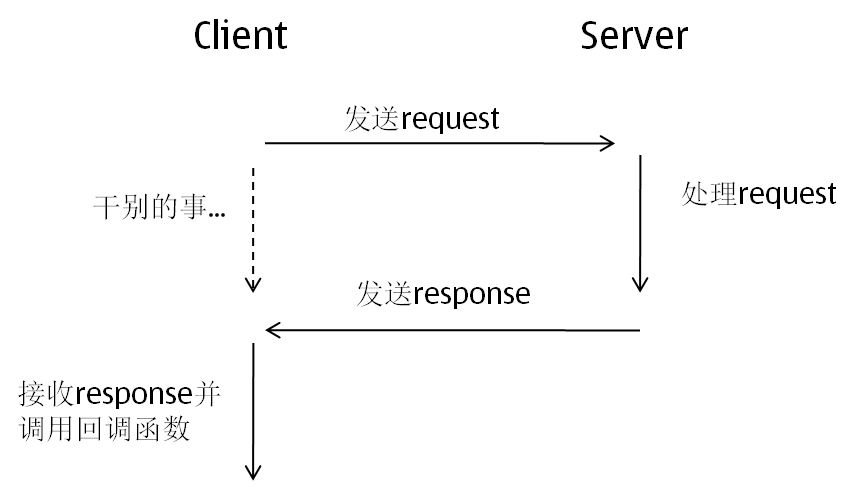
如果仔細琢磨的話,會發現這個流程中有兩個很重要的問題需要解決:
1. 當client接收到response後,怎樣確認它到底是之前哪個request的response呢?
2. 如果傳送一個request後,這個request對應的response由於種種原因(比如server端出問題了)一直沒有返回。client怎麼能夠發現類似這樣長時間沒有收到response的request呢?
對於第一個問題,一般會嘗試給每個request分配一個獨一無二的ID,返回的Response會同時攜帶這個ID,這樣就能夠將request和response對應上了。
對於第二個問題,需要有一個timeout機制,對於每一個request都有一個定時器,如果到指定時間仍然沒有返回結果,那麼會觸發timeout操作。多說一句,timeout機制其實對於涉及網路的同步機制也是非常有必要的,因為有可能client與server之間的連結壞了,在極端情況下,client會被一直阻塞住。
紙上談兵了這麼久,還是看一個實際的例子。我在這裡用Hadoop的RPC程式碼舉例。這裡需要事先說明的是,Hadoop的RPC對外的介面其實是同步的,但是,RPC的內部實現其實是非同步訊息機制。多說無益,直接看程式碼吧(討論的所有程式碼都在org.apache.hadoop.ipc.Client.java
這就是Client.java對外提供的介面。一共有兩個引數,param是希望傳送的request,remoteId是指遠端server對應的Id。函式的返回就是response(也是繼承自writable)。所以說,這是一個同步呼叫,一旦call函式返回,那麼response也就拿到了。
call函式的具體實現一會再看,先介紹Client中兩個重要的內部類:
call這個類對應的就是一次非同步請求。它的幾個成員變數:
id: 這個就是之前提過的,對於每一個request都需要分配一個唯一標示符,這樣接收到response後才能知道到底對應哪個request;
param: 需要傳送到server的request;
value: 從server傳送過來的response;
error: 可能發生的異常(比如網路讀寫錯誤,server掛了,等等);
done: 表示這個call是否成功完成了,即是否接收到了response;
Connection這個類要比之前的Call複雜得多,所以我省略了很多這裡不會被討論的程式碼。
Connection對應於一個連線,即一個socket。但同時,它又繼承自Thread,所有它本身又對應於一個執行緒。可以看出,在Hadoop的RPC中,一個連線對應於一個執行緒。先看他的成員變數:
server: 這是遠端server的地址;
socket: 對應的socket;
in / out: socket的輸入流和輸出流;
calls: 重要的成員變數。它是一個hash表, 維護了這個connection正在進行的所有call和它們對應的id之間的關係。當讀取到一個response後,就通過id在這張表中找到對應的call;
再看看它的run()函式。這是Connection這個執行緒的啟動函式,我貼的程式碼中這個函式沒做任何的刪減,你可以發現,刨除一些冗餘程式碼,這個函式其實就只做了一件事:receiveResponse,即等待接收response。
OK。回到call()這個函式,看看它到底做了什麼:
首先,它建立了一個新的call(這個call是Call類的實體,注意和call()函式的區分),然後根據remoteId找到對應的connection(Client類中維護了一個connection pool),然後呼叫connection.sendParam()。從前面找到這個函式,你會發現它就是將request寫入到socket,傳送出去。
但值得一提的是,它使用的write是最普通的blocking IO,也是同步IO(後面會看到,它讀取response也是用的blcoking IO,所以,hadoop RPC雖然是非同步機制,但是採用的是同步blocking IO,所以,非同步訊息機制還採用什麼樣的IO機制是沒有關係的)。
接下來,呼叫了call.wait(),將執行緒阻塞在這裡。直到在某個地方呼叫了call.notify(),它才重新執行起來,然後一通判斷後返回call.value,即接收到的response。
所以,剩下的問題是,到底是哪呼叫了call.notify()?
回到connection的receiveResponse函式:
首先,它從socket的輸入流中讀到一個id,然後根據這個id找到對應的call,呼叫call.setValue將從socket中讀取的response放入到call的value中,然後呼叫calls.remove(id)將這個call從佇列中移除。這裡要注意的是call.setValue,這個函式將value設定好之後,呼叫了call.notify()!
好了,讓我們再重頭將流程捋一遍:
這裡其實有兩個執行緒,一個執行緒是呼叫Client.call(),希望向遠端server傳送請求的執行緒,另外一個執行緒就是connection對應的那個執行緒。當然,雖然有兩個執行緒,但server對應的只有一個socket。第一個執行緒建立call,然後呼叫call.sendParam將request通過這個socket傳送出去;而第二個執行緒不斷的從socket中讀取response。因此,request的傳送和response的接收被分隔到不同的執行緒中執行,而且這兩個執行緒之間關於socket的讀寫並沒有任何的同步機制,因此我認為這個RPC是非同步訊息機制實現的,只不過通過call.wait()/call.notify()使得對外的介面看上去像是同步。
好了,Hadoop的RPC介紹完了(雖然我略掉了很多內容,比如timeout機制我這裡就沒寫),說說我個人的評價吧。我認為,Hadoop的這個設計還是挺巧妙的,底層採用的是非同步機制,但對外的介面提供的又是一般人比較習慣的同步方式。但是,我覺著缺點不是沒有,一個問題是一個連結就要產生一個執行緒,這個如果是在幾千臺的cluster中,仍然會帶來巨大的執行緒context switch的開銷;另一個問題是對於同一個remote server只有一個socket來進行資料的傳送和接收,這樣的設計網路的吞吐量很有可能上不去。(一家之言,歡迎指正)
未完待續~