
使用Flume將MySQL表資料實時抽取到hadoop
在以前搭建HAWQ資料倉庫實驗環境時,我使用Sqoop抽取從MySQL資料庫增量抽取資料到HDFS,然後用HAWQ的外部表進行訪問。這種方式只需要很少量的配置即可完成資料抽取任務,但缺點同樣明顯,那就是實時性。Sqoop使用MapReduce讀寫資料,而MapReduce是為了批處理場景設計的,目標是大吞吐量,並不太關心低延時問題。就像實驗中所做的,每天定時增量抽取資料一次。
Flume是一個海量日誌採集、聚合和傳輸的系統,支援在日誌系統中定製各類資料傳送方,用於收集資料。同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方的能力。Flume以流方式處理資料,可作為代理持續執行。當新的資料可用時,Flume能夠立即獲取資料並輸出至目標,這樣就可以在很大程度上解決實時性問題。
Flume是最初只是一個日誌收集器,但隨著flume-ng-sql-source外掛的出現,使得Flume從關係資料庫採集資料成為可能。下面簡單介紹Flume,並詳細說明如何配置Flume將MySQL表資料準實時抽取到HDFS。
二、Flume簡介
1. Flume的概念
Flume是分散式的日誌收集系統,它將各個伺服器中的資料收集起來並送到指定的地方去,比如說送到HDFS,簡單來說flume就是收集日誌的,其架構如圖1所示。
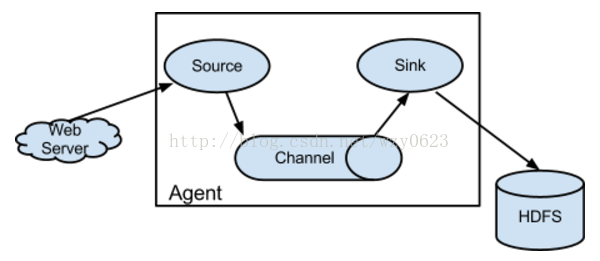
圖1
2. Event的概念
在這裡有必要先介紹一下Flume中event的相關概念:Flume的核心是把資料從資料來源(source)收集過來,在將收集到的資料送到指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,會先快取資料(channel),待資料真正到達目的地(sink)後,Flume再刪除自己快取的資料。
在整個資料的傳輸的過程中,流動的是event,即事務保證是在event級別進行的。那麼什麼是event呢?Event將傳輸的資料進行封裝,是Flume傳輸資料的基本單位,如果是文字檔案,通常是一行記錄。Event也是事務的基本單位。Event從source,流向channel,再到sink,本身為一個位元組陣列,並可攜帶headers(頭資訊)資訊。Event代表著一個數據的最小完整單元,從外部資料來源來,向外部的目的地去。
3. Flume架構介紹
Flume之所以這麼神奇,是源於它自身的一個設計,這個設計就是agent。Agent本身是一個Java程序,執行在日誌收集節點——所謂日誌收集節點就是伺服器節點。 Agent裡面包含3個核心的元件:source、channel和sink,類似生產者、倉庫、消費者的架構。
- Source:source元件是專門用來收集資料的,可以處理各種型別、各種格式的日誌資料,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定義。
- Channel:source元件把資料收集來以後,臨時存放在channel中,即channel元件在agent中是專門用來存放臨時資料的——對採集到的資料進行簡單的快取,可以存放在memory、jdbc、file等等。
-
Sink:sink元件是用於把資料傳送到目的地的元件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、Hbase、solr、自定義。
4. Flume的執行機制
Flume的核心就是一個agent,這個agent對外有兩個進行互動的地方,一個是接受資料輸入的source,一個是資料輸出的sink,sink負責將資料傳送到外部指定的目的地。source接收到資料之後,將資料傳送給channel,chanel作為一個數據緩衝區會臨時存放這些資料,隨後sink會將channel中的資料傳送到指定的地方,例如HDFS等。注意:只有在sink將channel中的資料成功傳送出去之後,channel才會將臨時資料進行刪除,這種機制保證了資料傳輸的可靠性與安全性。
三、安裝Hadoop和Flume
我的實驗在HDP 2.5.0上進行,HDP安裝中包含Flume,只要配置Flume服務即可。HDP的安裝步驟參見“HAWQ技術解析(二) —— 安裝部署”
四、配置與測試
1. 建立MySQL資料庫表
建立測試表並新增資料。
[SQL] 純文字檢視 複製程式碼 ?
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 |
use
test;
create
table
wlslog
(id
int
not
null,
time_stamp
varchar(40),
category
varchar(40),
type
varchar(40),
servername
varchar(40),
code
varchar(40),
msg
varchar(40),
primary
key
( id )
);
insert
into
wlslog(id,time_stamp,category,type,servername,code,msg) values(1,'apr-8-2014-7:06:16-pm-pdt','notice',
|