
Elasticsearch對Hbase中的資料建索引實現海量資料快速查詢

一、將專案匯入myeclipse中
方法1:
將下載好的檔案(是解壓es_hbase6資料夾而不是Test-master)解壓到你myeclipse的Workspaces目錄中,然後在myeclipse中右鍵點選Import匯入專案
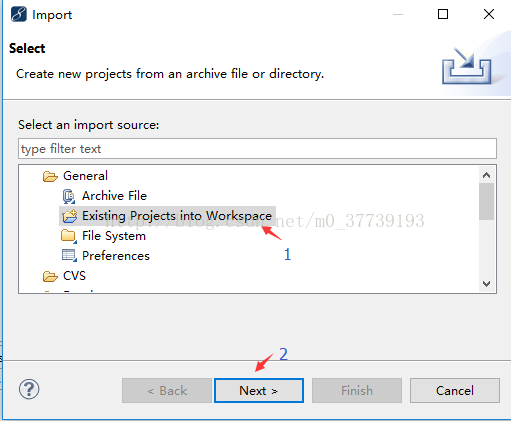
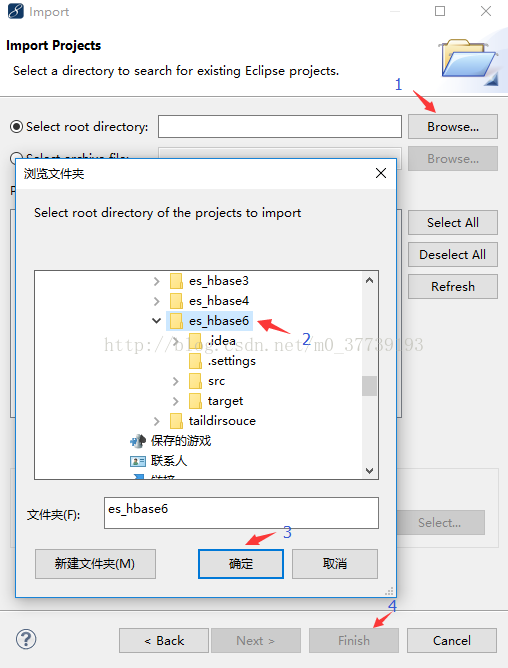
方法2:
將下載好的檔案解壓到你的Windows桌面,然後在myeclipse(我這裡用的是MyEclipse 10.7.1,如果你的版本不同,介面和選項會略有不同)中右鍵點選Import匯入專案
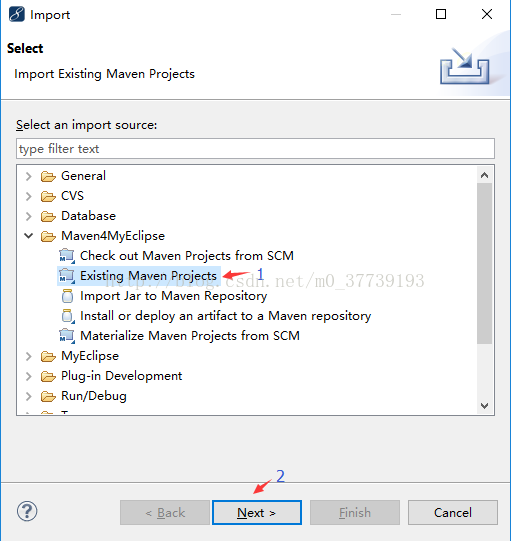
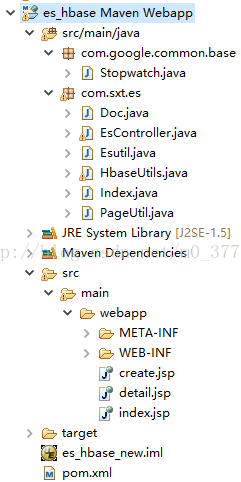
匯入成功
2.安裝Elasticsearch叢集(我的Linux為Centos 7.2)
(1)下載elasticsearch-2.2.0.tar.gz,下載地址:http://download.csdn.net/download/m0_37739193/9985530
[[email protected] ~]$ tar -zxvf elasticsearch-2.0.0.tar.gz
(2)同步到其他兩個節點:
[[email protected] ~]$ scp -r elasticsearch-2.2.0/ [email protected]:/home/hadoop/
[[email protected] ~]$ scp -r elasticsearch-2.2.0/ [email protected]:/home/hadoop/
(3)修改配置檔案config/elasticsearch.yml
[
[[email protected] elasticsearch-2.2.0]$ vi config/elasticsearch.yml新增: cluster.name: my-application node.name: node-1 network.host: 192.168.205.153 新增防腦裂配置: discovery.zen.ping.multicast.enabled: false discovery.zen.ping_timeout: 120s client.transport.ping_timeout: 60s discovery.zen.ping.unicast.hosts: ["192.168.205.153","192.168.205.154","192.168.205.155"]
新增:
cluster.name: my-application
node.name: node-2
network.host: 192.168.205.154
新增防腦裂配置:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["192.168.205.153","192.168.205.154","192.168.205.155"]
[[email protected] elasticsearch-2.2.0]$ vi config/elasticsearch.yml
新增:
cluster.name: my-application
node.name: node-3
network.host: 192.168.205.155
新增防腦裂配置:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["192.168.205.153","192.168.205.154","192.168.205.155"]
注意:如果要配置叢集需要兩個節點上的elasticsearch配置的cluster.name相同,都啟動可以自動組成叢集,nodename隨意取但是叢集內的各節點不能相同
(4)安裝es監控外掛(三臺虛擬機器都裝,後來感覺一臺裝就可以吧,有時間驗證一下)
[[email protected] ~]$ cd elasticsearch-2.2.0/bin/
[[email protected] bin]$ ./plugin install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ...
Downloading ..................................................................................DONE
Verifying https://github.com/mobz/elasticsearch-head/archive/master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /home/hadoop/elasticsearch-2.2.0/plugins/head在已經啟動了hadoop、hbase、zookeeper集群后再啟動es叢集
[[email protected] ~]$ ./elasticsearch-2.2.0/bin/elasticsearch
[[email protected] ~]$ ./elasticsearch-2.2.0/bin/elasticsearch
[[email protected] ~]$ ./elasticsearch-2.2.0/bin/elasticsearch
4.匯入hbase庫中的測試資料存放在你指定的目錄下C:\Users\huiqiang\Desktop\es\doc1.txt(內容以Tab鍵分隔)
1a hbase介紹及安裝 阿里巴巴 hbase的伺服器體系結構遵從簡單的主從服務架 在很多圖片上傳以及檔案下載操作的時候在很多圖片上傳以及檔案上傳下載操作的時候
2b docker的實戰經驗分享 百度 paas從2008年萬眾矚目到2012年遭受質疑 最近十天在做一個部落格系統,因為域名伺服器都閒置已久
3c 實時推薦系統的方式 騰訊 推薦系統介紹,自從1992年施樂的科學家為了解決資訊 這篇文章最要分享的是使用Apache的poi來實現資料匯出到execl的功能,這裡提供三種解決方案
4d hive的優化總結 華為 優化可以分為幾個方面著手 在商品詳情頁處理這裡的時候,因為我愛你
5e hive分割槽 啟明星辰 1、在hive select查詢中一般會掃描整個表內容 我們在使用kafka消費資訊的過程中
6f hdfs原理分析 七牛 儲存超大檔案 在${KAFKA_HOME}/bin下,有很多的指令碼,其中有一個kafka-run-class.sh
5.在hbase中建立相應的表
hbase(main):010:0> create 'doc','cf1'
相對應HbaseUtils.java中的程式碼為
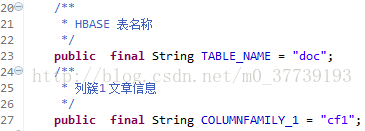
三、執行專案:
1.在EsController.java右擊執行專案
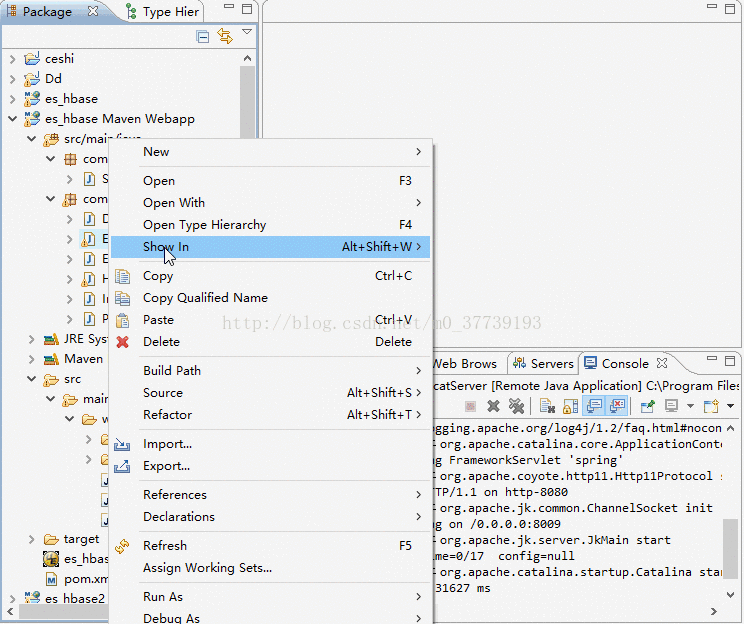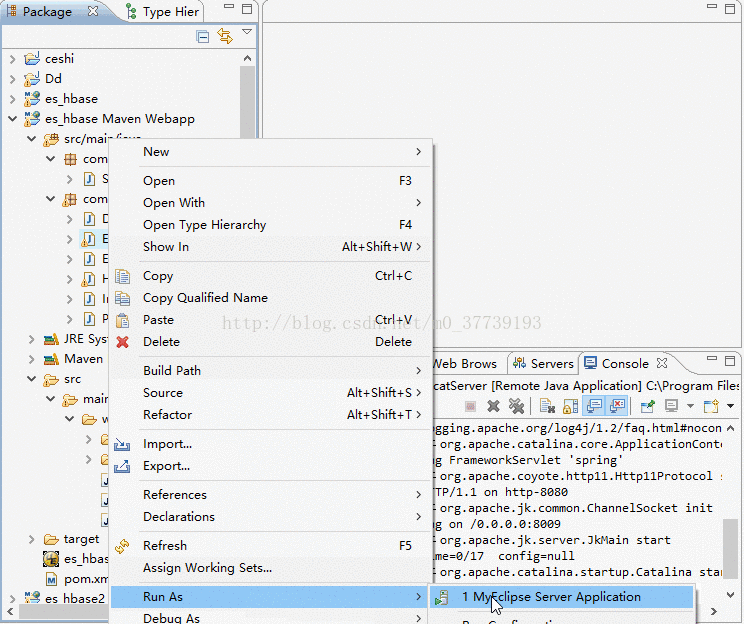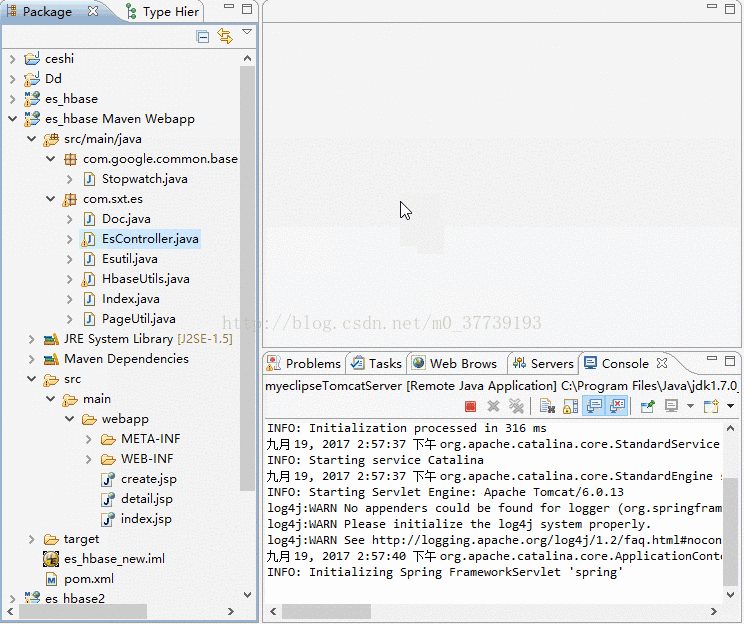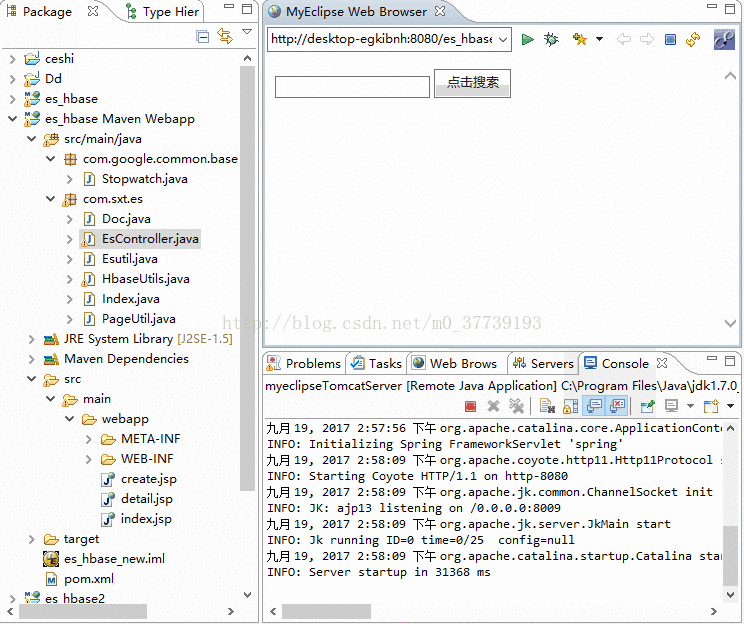
2.登入http://desktop-egkibnh:8080/es_hbase/create.jsp

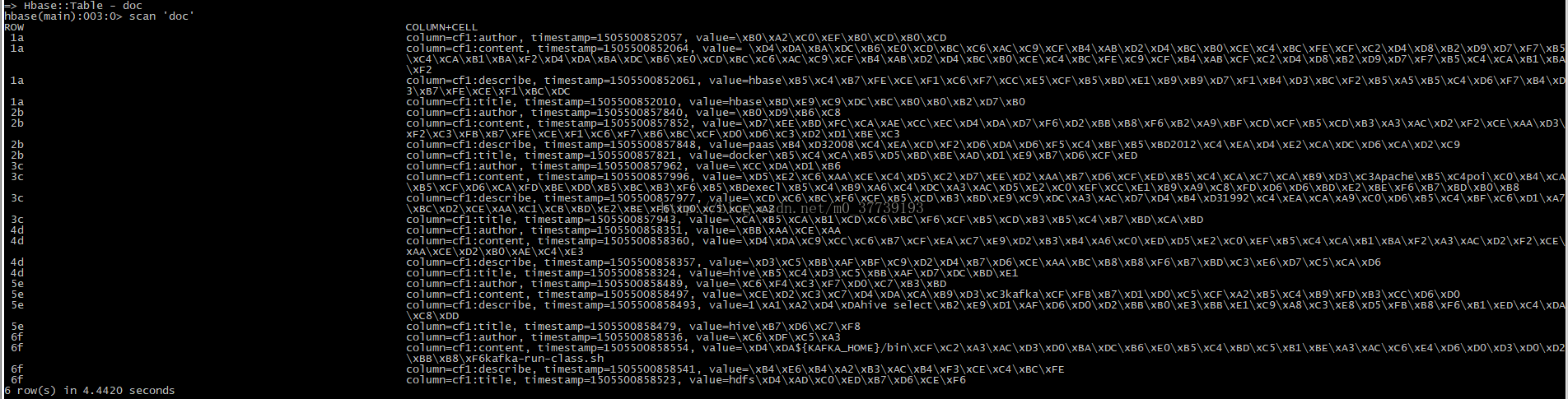
3.點選建立索引,則會往hbase中插入資料並且在es中建立索引(在谷歌瀏覽器輸入http://192.168.205.153:9200/_plugin/head/):
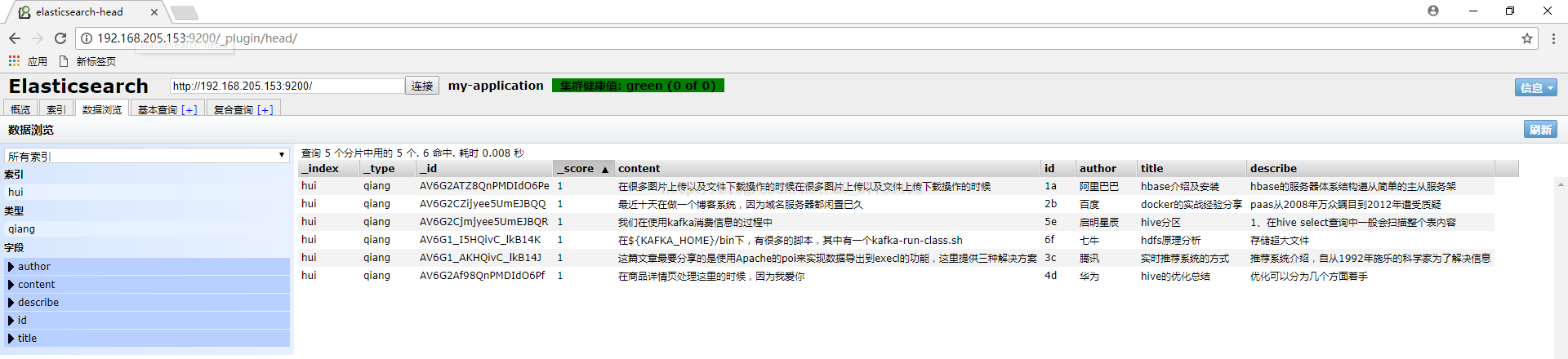
4.在http://desktop-egkibnh:8080/es_hbase/中輸入搜尋的關鍵字後搜尋:

四、思考:
1.後來我想增加對hbase表中的rowkey在es中也建立索引,但卻總是失敗。主要遇到了兩個問題:
(1)對rowkey設定高亮後搜尋rowkey點選無法返回內容。
(2)對rowkey的搜尋只能是全部搜尋,比如rowkey為abcd,那麼只能輸入abcd才能搜尋到,輸入ab則搜尋不到。其實並不只rowkey是這樣,對所有的英文單詞(hive)和數字(2008)都只能全部搜尋而不能部分匹配。
後來想想其實rowkey也沒必要建立索引,你可以把需要搜尋的資訊放在列裡,rowkey可以用UUID生成來保證每條資料的唯一性,UUID就沒必要作為搜尋資訊了吧。但強迫症的我還是想實現也能夠對rowkey建立索引搜尋,如果大家有誰能實現了的話,還希望能告我一下,大家一起探討學習一下哈。
解決問題(2)
解決該問題可使用部分匹配(可參考http://blog.csdn.net/m0_37739193/article/details/78291535),目前我整出了三種類型供大家在不同場景下使用。
注意:在執行專案之前需要先手動用檔案建立索引。
型別一
[[email protected] elasticsearch-2.2.0]$ vi hehe.json
{
"settings": {
"number_of_shards": 1,
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings":{
"qiang":{
"dynamic":"strict",
"properties":{
"id":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"title":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"describe":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"author":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"content":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"}
}
}
}
}[[email protected] elasticsearch-2.2.0]$ curl -XPOST '192.168.205.153:9200/hui' -d @hehe.json
最終搜尋效果:

侷限性:
1.對於一個英文單詞只能從前面往後而不能任意輸入,比如hive這個單詞輸入hiv能命中,而輸入ive則不可以。
2.只能高亮顯示整個英文單詞,而不能高亮顯示搜尋的內容,比如hive這個單詞只能這樣顯示hive,而不能這樣顯示hive。
3.對特殊字元無能為力,如”_“、”}“、”/“
型別二
[[email protected] elasticsearch-2.2.0]$ vi hehe.json
{
"settings": {
"analysis": {
"filter": {
"trigrams_filter": {
"type": "ngram",
"min_gram": 1,
"max_gram": 5
}
},
"analyzer": {
"trigrams": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"trigrams_filter"
]
}
}
}
},
"mappings":{
"qiang":{
"dynamic":"strict",
"properties":{
"id":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"title":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"describe":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"author":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"content":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"}
}
}
}
}最終搜尋效果:

侷限性:
1.這個也不應該較侷限性,是出了我也不知道咋解決的問題,如果一個術語長這樣0123223003_0e72262cc4264b27b0ffc0f8cb137d12,那麼在輸_前半部分的時候能搜尋到該術語並且高亮顯示,但輸_後半部分的時候雖然也能搜尋到,但卻不高亮顯示,一開始我以為是特殊符號“_”的原因,但結果換成012_cc4後卻正常,我也是醉了。。。
2.只能高亮顯示整個英文單詞,而不能高亮顯示搜尋的內容,比如hive這個單詞只能這樣顯示hive,而不能這樣顯示hive。
3.對特殊字元無能為力,如”_“、”}“、”/“
型別三
[[email protected] elasticsearch-2.2.0]$ vi hehe.json
{
"settings": {
"analysis": {
"analyzer": {
"charSplit": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "nGram",
"min_gram": "1",
"max_gram": "1",
"token_chars": [
"letter",
"digit",
"punctuation"
]
}
}
}
},
"mappings":{
"qiang":{
"dynamic":"strict",
"properties":{
"id":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"title":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"describe":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"author":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"content":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"}
}
}
}
}最終搜尋效果:
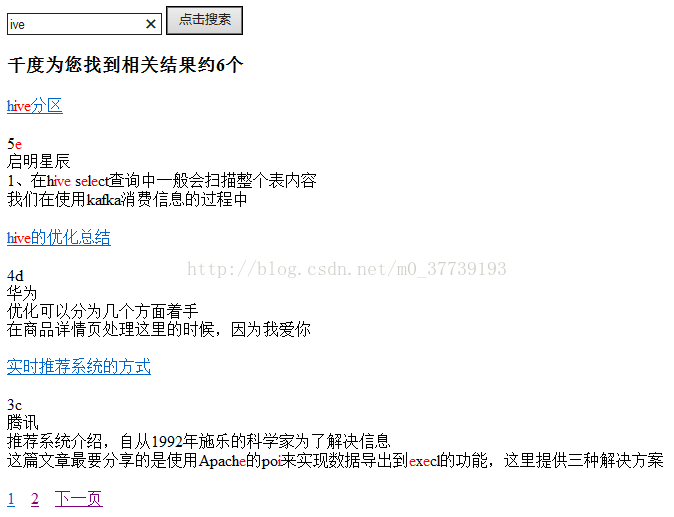
侷限性:
1.雖然能這樣顯示hive,但是卻將其他不想要的也搜尋出來,目前我並沒有想出很好的解決方法(本來想在程式碼中搜索的api中加入模糊匹配的程式碼,如搜尋關鍵詞key的時候就自動搜尋*key*,但我沒有成功。即使對英文能成功但是對中文卻無能為力)
2.發現了個奇怪的現象,當把max_gram設定成大於1的值時,搜尋“提”字能搜尋到卻不高亮顯示,並且搜尋中間隔一個字的兩個字三個都高亮顯示,比如搜尋“提供種”,搜尋結果為“提供三種”,並且搜“}”和“/”這兩個特殊字元能搜到卻不高亮顯示。