
正則表示式中的貪婪模式和懶惰模式
1,需求:從這段字串的匹配出<h3></h3>中的內容
<h3>abd</h3><h3>bcd</h3><h3>dfsd</h3>
我們可以寫這兩種正則表示式來實現
1,<h3>.{0,}</h3> 2,<h3>.*</h3>
結果我們發現:預設的貪婪模式只匹配了開頭的<h3>和結尾的</h3>,沒有把中間的每一對標籤的內容匹配出來
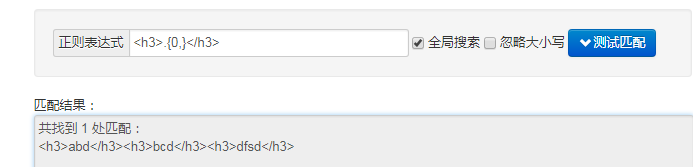
我們在後面加個?引數,就啟用了懶惰模式,找到一對就顯示出來,

總結:正則表示式,表示字串重複個數元字元,'?,+,*,{}' 預設都會選擇貪婪模式,會最大長度匹配字串,而要切換到懶惰模式,就只是在該元字元,後面加多一個”?” 即可切換到非貪婪模式(懶惰模式)。
相關推薦
正則表示式的貪婪匹配與懶惰匹配
今天用到正則表示式的懶惰匹配,由於開始不是很瞭解,所以一個問題糾結了一天,真正瞭解了就不難了。 例:一個字串“abcdakdjd” regex="a.*?d"; 懶惰匹配 regex2="a.*
詳解正則表示式中的\B和\b
對於正則表示式的中\B和\b 有些地方會出現弄不懂的情況 或許你看了下面這篇部落格 你就能夠對\B和\b認識加深了 根據檢視API可以知道 \B和\b都是邊界匹配符 先說說\b這個單詞邊界吧!竟然想了解 首先必須清楚什麼叫單詞邊界!我們可以以\b為分
正則表示式中的貪婪模式和懶惰模式
1,需求:從這段字串的匹配出<h3></h3>中的內容 <h3>abd</h3><h3>bcd</h3><h3>dfsd</h3> 我們可以寫這兩種正則表示式來實現 1,<h3>.{0,}<
js中正則表示式的貪婪模式和非貪婪模式
在講貪婪模式和惰性模式之前,先回顧一下JS正則基礎: 寫法基礎: ①不需要雙引號,直接用//包含 => /wehfwue123123/.test(); ②反斜槓\表示轉義 =>/\.jpg$/ ③用法基礎:.test(str); 語法: ①錨點類 /^a/=&g
Python正則表示式中的貪心模式和非貪心模式
宣告:最近發現有人利用我在百度雲盤裡免費分享的127課Python視訊盈利,並聲稱獲得我的授權。
Python正則表示式的貪婪模式和非貪婪模式
貪婪模式是把所有匹配的獲取到,非貪婪模式只取到第一個匹配到的字串,在python中findall和match的區別。 http://blog.csdn.net/qq_33447462/article/details/51485900 .*與.*?的區別:
Java中正則表示式相關類Pattern和Matcher的使用
在Java中,java.util.regex包定義了正則表示式使用到的相關類,其中最主要的兩個類為:Pattern、Matcher: Pattern 編譯正則表示式後建立一個匹配模式; Matcher 使用Pattern例項提供的正則表示式對目標字串進行匹
正則表示式中Pattern類、Matcher類和matches()方法簡析
1.簡介: java.util.regex是一個用正則表示式所訂製的模式來對字串進行匹配工作的類庫包。 它包括兩個類:Pattern和Matcher 。 Pattern: 一個Pattern是一個正則表示式經編譯後的表現模式。 Matcher: 一個Matcher物件
正則表示式中的模式,函式,及使用規則
一、正則表示式轉義 正則中的特殊符號: . * ? $ [] {} () | \ 正則表示式匹配特殊字元如果需要加 \ 表達轉義,比如: pattern
關於java正則表示式中的 ^和$的使用
java正則表示式的邊界匹配符中,有兩個比較常用的字元:“ ^ ”和“ $ ”,這兩個字元理解起來比較容易混淆。先說下這兩個字元的含義: “ ^ ”:匹配輸入字串開始的位置。如果設定了 RegExp 物件的 Multiline 屬性,^ 還會與”\n”或”\r
正則表示式的貪婪模式與非貪婪模式
貪婪模式:能匹配的最大部分 s = "This is a number 234-235-22-4223" r = re.match(r"(.+)(\d+-\d+-\d+-\d+",s) r.groups() ("This is a number 23"
正則表示式中的貪婪匹配——python學習筆記
貪婪匹配 1.1 概念 正則匹配預設是貪婪匹配,也就是匹配儘可能多的字元。舉例如下,匹配出數字後面的0;以下例子是用python寫的,但是貪婪匹配的概念在其他語言中是一致的。 import re result = re.match(r'^(\d+)(0*)$', '102300
正則表示式中group和groups的區別
第一點,搞清楚它們用在什麼地方? 正則表示式中,group()用來提取分組截獲的字串,()用來分組。 組是通過 "(" 和 ")" 元字元來標識的。 "(" 和 ")" 有很多在數學表示式中相同的意思;它們一起把在它們裡面的表示式組成一組。舉個例子,你可以用重複限制符
正則表示式之貪婪與非貪婪模式(II)
貪婪模式 正則表示式在匹配的時候會盡可能多的匹配,直至匹配失敗 如: '123456789'.replace(/\d{3,7}/g,'X') 結果: "X89" 非貪婪模式 讓正
正則表示式非貪婪模式的應用
貪婪模式又叫匹配優先模式,在整個表示式匹配成功的前提下,儘可能多的匹配,而非貪婪模式恰恰相反,在整個表示式匹配成功的前提下,儘可能少的匹配,針對的量詞包括: {m, n} {m, } ? * + 從書寫正則表示式的差異來看,它們的唯一區別在於非貪婪模式在
正則表示式之--貪婪與非貪婪模式詳解
“.*”取得控制權後,由A後面的位置開始嘗試匹配,由於是貪婪模式,優化嘗試匹配,一直匹配到字串的結束位置,將控制權交給“"”。“"”取得控制權後,由於已經是字串的結束位置,匹配失敗,查詢可供回溯的狀態,將控制權交給“.*”,由“.*”讓出已匹配字元“.”。重複以上過程,直到後面“"”匹配了C處後面的字元“””
【JavaScript】正則表示式--非貪婪模式擷取任意字串的筆記
場景要將下面的字串擷取兩個{title:***,url:***}來。12345<script>{title:'RegExp 物件參考手冊',url:'http://sodino.com/regexp.asp'},{title:'w3cSchool script', url:'http://www.
正則表示式中^/$和i、m、g的使用
<script type="text/javascript"> var p = /[A-Za-z]+$/m; var s = '1a\n2b\n3c\n4d\n5e\n6f'; console.log(p.test(s)); //顯示為true //返回上一次正則表示式搜尋時,被搜尋字串中最後一
正則表示式的貪婪與非貪婪模式
<script> try{ str="<p>abcdefg</p><p>abcdefghijkl</p>"; re1=str.match(/<p>[\W\w]+?<\/p>/ig); al
[深坑]關於groovy正則表示式中的限位符 `^` 和 `$`
問題提出 最近在工作中需要自己寫正則表示式,而且是用 groovy,本以為 groovy 是沿用了 java.util.regex 包,只要 java 中執行沒問題就可以,結果問題就出現了。 java 中程式如下: import java.util.r