
day30 作業系統介紹 程序的建立
理論知識
作業系統(多道系統)
作業系統簡單介紹
#一 作業系統的作用:
1:隱藏醜陋複雜的硬體介面,提供良好的抽象介面
2:管理、排程程序,並且將多個程序對硬體的競爭變得有序
#二 多道技術:
1.產生背景:針對單核,實現併發
ps:
現在的主機一般是多核,那麼每個核都會利用多道技術
有4個cpu,運行於cpu1的某個程式遇到io阻塞,會等到io結束再重新排程,會被排程到4個
cpu中的任意一個,具體由作業系統排程演算法決定。
2.空間上的複用:如記憶體中同時有多道程式
3.時間上的複用:複用一個cpu的時間片
強調:遇到io切,佔用cpu時間過長也切,核心在於切之前將程序的狀態儲存下來,這樣
才能保證下次切換回來時,能基於上次切走的位置繼續執行多道程式系統(重點*****)
多道批處理系統
多道程式設計技術(特點:時空複用-->任務切換,記錄狀態)
所謂多道程式設計技術,就是指允許多個程式同時進入記憶體並執行。即同時把多個程式放入記憶體,並允許它們交替在CPU中執行,它們共享系統中的各種硬、軟體資源。當一道程式因I/O請求而暫停執行時,CPU便立即轉去執行另一道程式。
空間的複用:將記憶體分為幾部分,每個部分放入一個程式,這樣,同一時間記憶體中就有了多道程式。
時間的複用—>遇到io操作就切換任務(巨集觀上(偽)並行,微觀上序列)
分時系統
分時技術(分時間片工作,及時響應,但是效率降低
分時技術(多道技術對時間的複用方式(遇到I/O操作才切換,對於沒有I/O中斷的程式會一直執行,其他的短作業程式也要一直等待著)並不合理,所以出現了分時技術(依照時間來回切換,雨露均沾)
分時技術(概念):把處理機的執行時間分成很短的時間片,按時間片輪流把處理機分配給各聯機作業使用。
分時系統的主要目標:對使用者響應的及時性,即不至於使用者等待每一個命令的處理時間過長。
注意:分時系統的分時間片工作,在沒有遇到IO操作的時候就用完了自己的時間片被切走了,這樣的切換工作其實並沒有提高cpu的效率,反而使得計算機的效率降低了。為什麼下降了呢?因為CPU需要切換,並且記錄每次切換程式執行到了哪裡,以便下次再切換回來的時候能夠繼續之前的程式,雖然我們犧牲了一點效率,但是卻實現了多個程式共同執行的效果,這樣你就可以在計算機上一邊聽音樂一邊聊qq了。
實時系統
雖然多道批處理系統和分時系統能獲得較令人滿意的資源利用率和系統響應時間,但卻不能滿足實時控制與實時資訊處理兩個應用領域的需求。於是就產生了實時系統,即系統能夠及時響應隨機發生的外部事件,並在嚴格的時間範圍內完成對該事件的處理。
現在的應用:
分時——現在流行的PC,伺服器都是採用這種執行模式,即把CPU的執行分成若干時間片分別處理不同的運算請求 linux系統
實時——一般用於微控制器上、PLC等,比如電梯的上下控制中,對於按鍵等動作要求進行實時處理
通用作業系統
作業系統的三種基本型別:多道批處理系統、分時系統、實時系統。
通用作業系統:具有多種型別操作特徵的作業系統。可以同時兼有多道批處理、分時、實時處理的功能,或其中兩種以上的功能。
程序
什麼是程序(動態產生,動態消亡的)
程式是指令、資料及其組織形式的描述,程序是程式的實體、是執行緒的容器。
狹義定義:程序是正在執行的程式的例項(an instance of a computer program that is being executed)。
廣義定義:程序是一個具有一定獨立功能的程式關於某個資料集合的一次執行活動。它是作業系統動態執行的基本單元,在傳統的作業系統中,程序既是基本的分配單元,也是基本的執行單元。

第一,程序是一個實體。每一個程序都有它自己的地址空間,一般情況下,包括文字區域(text region)(python的檔案)、資料區域(data region)(python檔案中定義的一些變數資料)和堆疊(stack region)。文字區域儲存處理器執行的程式碼;資料區域儲存變數和程序執行期間使用的動態分配的記憶體;堆疊區域儲存著活動過程呼叫的指令和本地變數。 第二,程序是一個“執行中的程式”。程式是一個沒有生命的實體,只有處理器賦予程式生命時(作業系統執行之),它才能成為一個活動的實體,我們稱其為程序。[3] 程序是作業系統中最基本、重要的概念。是多道程式系統出現後,為了刻畫系統內部出現的動態情況,描述系統內部各道程式的活動規律引進的一個概念,所有多道程式設計作業系統都建立在程序的基礎上。程序的概念
動態性:程序的實質是程式在多道程式系統中的一次執行過程,程序是動態產生,動態消亡的。
併發性:任何程序都可以同其他程序一起併發執行
獨立性:程序是一個能獨立執行的基本單位,同時也是系統分配資源和排程的獨立單位;
非同步性:由於程序間的相互制約,使程序具有執行的間斷性,即程序按各自獨立的、不可預知的速度向前推進
結構特徵:程序由程式、資料和程序控制塊三部分組成。
多個不同的程序可以包含相同的程式:一個程式在不同的資料集裡就構成不同的程序,能得到不同的結果;但是執行過程中,程式不能發生改變。
程序的特徵
程式是指令和資料的有序集合,其本身沒有任何執行的含義,是一個靜態的概念。
而程序是程式在處理機上的一次執行過程,它是一個動態的概念。
程式可以作為一種軟體資料長期存在,而程序是有一定生命期的。
程式是永久的,程序是暫時的。
舉例:就像qq一樣,qq是我們安裝在自己電腦上的客戶端程式,其實就是一堆的程式碼檔案,我們不執行qq,那麼他就是一堆程式碼程式,當我們執行qq的時候,這些程式碼執行起來,就成為一個程序了。
程序與程式中的區別
程序的排程
要想多個程序交替執行,作業系統必須對這些程序進行排程,這個排程也不是隨即進行的,而是需要遵循一定的法則,由此就有了程序的排程演算法。
先來先服務排程演算法
短作業優先排程演算法
時間片輪轉法
多級反饋佇列
程序的併發與並行
無論是並行還是併發,在使用者看來都是'同時'執行的,不管是程序還是執行緒,都只是一個任務而已,真正幹活的是cpu,cpu來做這些任務,而一個cpu同一時刻只能執行一個任務
併發:偽並行(並行也屬於併發),看著像同時執行,其實是任務之間的切換(遇到io切換的會提高程式碼效率) ,單個cpu+多道技術(多道技術是針對單核而言的)就可以實現併發-->任務切換+儲存狀態(儲存現場)
並行:真正的同時在執行,應用的是多核技術(多個cpu)-->同時執行,只有具備多個cpu才能實現並行
同步\非同步\阻塞\非阻塞(重點)
程序狀態介紹
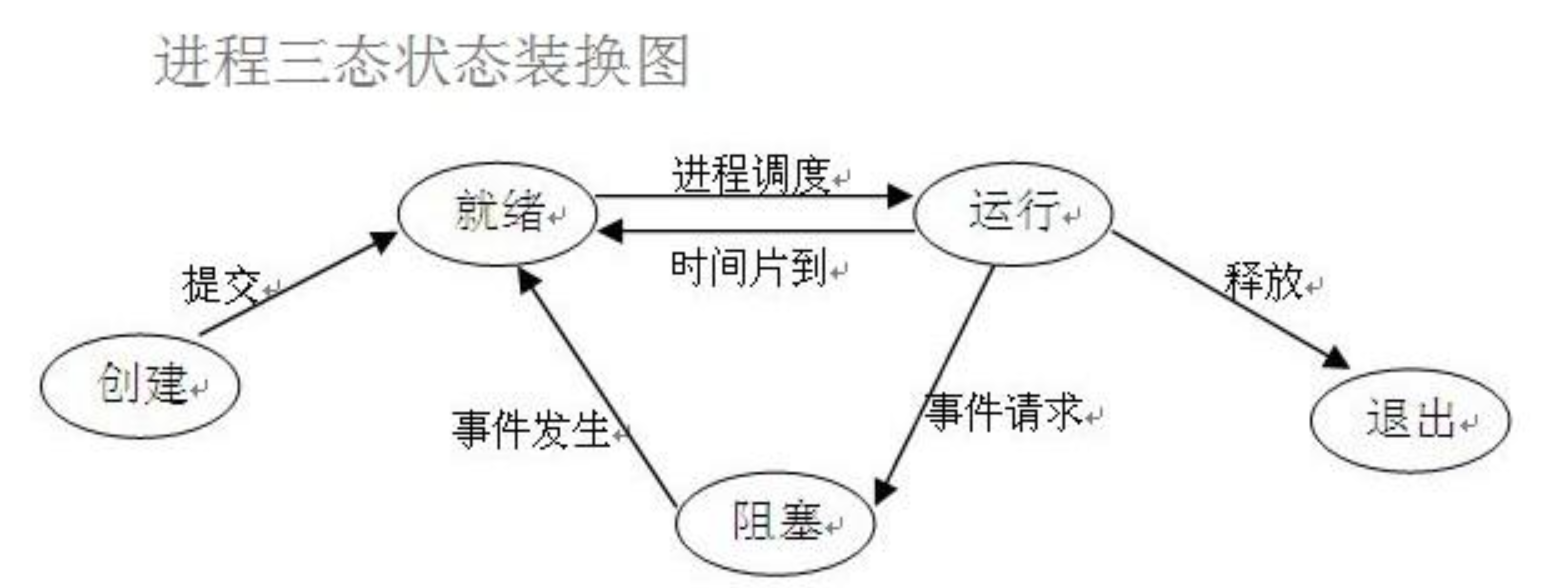
程序三狀態:就緒(等待作業系統排程去cpu裡面執行) 執行 阻塞
(1)就緒(Ready)狀態 當程序已分配到除CPU以外的所有必要的資源,只要獲得處理機便可立即執行,這時的程序狀態稱為就緒狀態。 (2)執行/執行(Running)狀態當程序已獲得處理機,其程式正在處理機上執行,此時的程序狀態稱為執行狀態。 (3)阻塞(Blocked)狀態正在執行的程序,由於等待某個事件發生而無法執行時,便放棄處理機而處於阻塞狀態。引起程序阻塞的事件可有多種,例如,等待I/O完成、申請緩衝區不能滿足、等待信件(訊號)等。 事件請求:input、sleep、檔案輸入輸出、recv、accept等 事件發生:sleep、input等完成了 時間片到了之後有回到就緒狀態,這三個狀態不斷的在轉換。程序的三狀態
同步和非同步(同步==>序列 非同步==>並行)(同步和非同步是提交任務的方式)
所謂同步就是一個任務的完成需要依賴另外一個任務時,只有等待被依賴的任務完成後,依賴的任務才能算完成,這是一種可靠的任務序列。要麼成功都成功,失敗都失敗,兩個任務的狀態可以保持一致。其實就是一個程式結束才執行另外一個程式,序列的,不一定兩個程式就有依賴關係。
所謂非同步是不需要等待被依賴的任務完成,只是通知被依賴的任務要完成什麼工作,依賴的任務也立即執行,只要自己完成了整個任務就算完成了。至於被依賴的任務最終是否真正完成,依賴它的任務無法確定,所以它是不可靠的任務序列。
阻塞和非阻塞(阻塞非阻塞是任務的執行狀態)
阻塞和非阻塞這兩個概念與程式(執行緒)等待訊息通知(無所謂同步或者非同步)時的狀態有關。也就是說阻塞與非阻塞主要是程式(執行緒)等待訊息通知時的狀態角度來說的
同步\非同步 與 阻塞\非阻塞
同步阻塞形式
非同步阻塞形式
同步非阻塞形式
非同步非阻塞形式
程序的建立、結束與併發的實現(瞭解)
不重要,省略了...
在python程式中的程序操作
multiprocessing模組
仔細說來,multiprocess不是一個模組而是python中一個操作、管理程序的包。 之所以叫multi是取自multiple的多功能的意思,在這個包中幾乎包含了和程序有關的所有子模組。由於提供的子模組非常多,為了方便大家歸類記憶,我將這部分大致分為四個部分:建立程序部分,程序同步部分,程序池部分,程序之間資料共享。重點強調:程序沒有任何共享狀態,程序修改的資料,改動僅限於該程序內,但是通過一些特殊的方法,可以實現程序之間資料的共享。
process模組介紹
process模組是一個建立程序的模組,藉助這個模組,就可以完成程序的建立。
Process([group [, target [, name [, args [, kwargs]]]]]),由該類例項化得到的物件,表示一個子程序中的任務(尚未啟動) 引數介紹: 1 group引數未使用,值始終為None 2 target表示呼叫物件,即子程序要執行的任務 3 args表示呼叫物件的位置引數元組,args=(1,2,'egon',) 4 kwargs表示呼叫物件的字典,kwargs={'name':'egon','age':18} 5 name為子程序的名稱 強調: 1. 需要使用關鍵字的方式來指定引數 2. args指定的為傳給target函式的位置引數,是一個元組形式,必須有逗號,Process(target=f1,args=(4,)) kwargs]指定的為傳給target函式的關鍵字引數,是一個字典形式,Process(target=f1,kwargs={'n':4}) -->{'target的形參n作為key':值}
建立程序的兩種方式
方式一:multiprocessing.Process
栗子:
#當前檔名稱為test.py
from multiprocessing import Process
def func():
print(12345)
#windows 下才需要寫這個,這和系統建立程序的機制有關係,不用深究,記著windows下要寫就好啦
#首先我運行當前這個test.py檔案,執行這個檔案的程式,那麼就產生了程序,這個程序我們稱為主程序
if __name__ == '__main__':
#將函式註冊到一個程序中,p是一個程序物件,此時還沒有啟動程序,只是建立了一個程序物件。並且func是不加括號的,因為加上括號這個函式就直接運行了對吧。
p = Process(target=func,)
#告訴作業系統,給我開啟一個程序,func這個函式就被我們新開的這個程序執行了,而這個程序是我主程序執行過程中創建出來的,所以稱這個新建立的程序為主程序的子程序,而主程序又可以稱為這個新程序的父程序。
#而這個子程序中執行的程式,相當於將現在這個test.py檔案中的程式copy到一個你看不到的python檔案中去執行了,就相當於當前這個檔案,被另外一個py檔案import過去並執行了。
#start並不是直接就去執行了,我們知道程序有三個狀態,程序會進入程序的三個狀態,就緒,(被排程,也就是時間片切換到它的時候)執行,阻塞,並且在這個三個狀態之間不斷的轉換,等待cpu執行時間片到了。
p.start()
#這是主程序的程式,上面開啟的子程序的程式是和主程序的程式同時執行的,我們稱為非同步
print('*' * 10)
import time
from multiprocessing import Process
def f1():
time.sleep(3)
print('xxxx')
def f2():
time.sleep(3)
print('ssss')
# f1()
# f2()
#windows系統下必須寫main,因為windows系統建立子程序的方式決定的,開啟一個子程序,這個子程序 會copy一份主程序的所有程式碼,並且機制類似於import引入,這樣就容易導致引入程式碼的時候,被引入的程式碼中的可執行程式被執行,導致遞迴開始程序,會報錯
if __name__ == '__main__': #
p1 = Process(target=f1,)
p2 = Process(target=f2,)
p1.start()
p2.start()
if __name__ == '__main__':
看一個問題,說明linux和windows兩個不同的作業系統建立程序的不同機制導致的不同結果:
#其實是因為windows開起程序的機制決定的,在linux下是不存在這個效果的,因為windows使用的是process方法來開啟程序,他就會拿到主程序中的所有程式,而linux下只是去執行我子程序中註冊的那個函式,不會執行別的程式,這也是為什麼在windows下要加上執行程式的時候,要加上if __name__ == '__main__':,否則會出現子程序中執行的時候還開啟子程序,那就出現無限迴圈的建立程序了,就報錯了
類比
# file1.py 檔案中的程式碼
def f1():
print('xxxx')
# f1() -->被import的時候會執行
if __name__ == '__main__':
f1() -->被import的時候不會執行
# file2.py 檔案中的程式碼
import file1
同理
# file1.py 檔案中的程式碼
def f1():
print('xxxx')
# p1 = Process(target=f1,) -->被建立(相當於被import)的時候會執行
# p1.start()
if __name__ == '__main__':
p1 = Process(target=f1,) -->被建立(相當於被import)的時候不會執行
p1.start()
# file2.py 檔案中的程式碼
import file1
注意:在windows中Process()必須放到# if __name__ == '__main__':下(Linux可以不用)
Since Windows has no fork, the multiprocessing module starts a new Python process and imports the calling module. If Process() gets called upon import, then this sets off an infinite succession of new processes (or until your machine runs out of resources). This is the reason for hiding calls to Process() inside if __name__ == "__main__" since statements inside this if-statement will not get called upon import. 由於Windows沒有fork,多處理模組啟動一個新的Python程序並匯入呼叫模組。 如果在匯入時呼叫Process(),那麼這將啟動無限繼承的新程序(或直到機器耗盡資源)。 這是隱藏對Process()內部呼叫的原,使用if __name__ == “__main __”,這個if語句中的語句將不會在匯入時被呼叫。官方解釋
join方法的例子:
讓主程序加上join的地方等待(也就是阻塞住),等待子程序執行完之後,再繼續往下執行我的主程序,好多時候,我們主程序需要子程序的執行結果,所以必須要等待。join感覺就像是將子程序和主程序拼接起來一樣,將非同步改為同步執行。
import time
from multiprocessing import Process
def f1(n):
time.sleep(2)
print('xxxx')
def f2(m):
time.sleep(2)
print('ssss')
# 情景1
if __name__ == '__main__':
p1 = Process(target=f1,args=(4,)) # args是元組,必須帶逗號
p2 = Process(target=f2,kwargs={'m':4}) # kwargs這裡的鍵必須寫成目標函式f2的形參(字串),否則報錯
p1.start()
p2.start()
print('我是主程序!!!')
# 結果:瞬間列印 '我是主程序!!!',停頓2秒,再同時列印'xxxx'和'ssss'
# 情景2
if __name__ == '__main__':
p1 = Process(target=f1, args=(4,))
p2 = Process(target=f2,kwargs={'m': 4}) # kwargs這裡的鍵必須寫成目標函式f2的形參(字串),否則報錯
p1.start()
p2.start()
time.sleep(2)
print('我是主程序!!!')
# 結果:執行程式大概2秒後,幾乎一起打印出三個的值
# xxxx
# ssss
# 我是主程序!!!
# 情景3
if __name__ == '__main__':
p1 = Process(target=f1, args=(4,))
p2 = Process(target=f2,kwargs={'m': 4}) # kwargs這裡的鍵必須寫成目標函式f2的形參(字串),否則報錯
p1.start()
p2.start()
p1.join() # 主程序等待子程序執行完才繼續執行
p2.join()
print('我要等了...等我的子程序...')
print('我是主程序!!!')
# 結果:執行程式大概2秒後,幾乎一起打印出所有的值(因為呼叫start就已經執行完拿到結果了)
# ssss
# xxxx
# 我要等了...等我的子程序...
# 我是主程序!!!
# 情景4
if __name__ == '__main__':
p1 = Process(target=f1,args=(4,))
p1.start()
p1.join() # 主程序等待子程序執行完才繼續執行
print('開始p2拉')
p2 = Process(target=f2,kwargs={'m':4}) # kwargs這裡的鍵必須寫成目標函式f2的形參(字串),否則報錯
p2.start()
p2.join()
print('我要等了...等我的子程序...')
print('我是主程序!!!')
# 結果:等待2秒,前兩個一起打印出來,再等待2秒,後3個一起打印出來
# xxxx
# 開始p2拉
# ssss
# 我要等了...等我的子程序...
# 我是主程序!!!
綜上,join感覺就像是將子程序和(離他最近的)主程序拼接起來一樣,將非同步改為同步執行。
for迴圈開啟多個程序
栗子
import time
from multiprocessing import Process
def f1(i):
# time.sleep(3)
print(i)
if __name__ == '__main__':
for i in range(20):
p1 = Process(target=f1,args=(i,))
p1.start()
結果:列印20個(0~19)數字,是亂序的.這是因為程式碼是CPU執行的,執行速度很快,瞬間就將程式碼執行完了,告訴作業系統我要建立20個程序,作業系統來決定誰先被建立(就緒),誰先被執行(時間片輪轉,IO切換,都是作業系統來決定順序的,告訴CPU去執行)
需求:使用for迴圈開啟多個子程序,並且所有的子程序非同步執行,然後所有的子程序全部執行完之後,我再執行主程序,怎麼搞?看程式碼(按照編號去看註釋)
#下面的註釋按照編號去看,別忘啦!
import time
import os
from multiprocessing import Process
def func(x,y):
print(x)
# time.sleep(1) #程序切換:如果沒有這個時間間隔,那麼你會發現func執行結果是列印一個x然後一個y,再列印一個x一個y,不會出現列印多個x然後列印y的情況,因為兩個列印距離太近了而且執行的也非常快,但是如果你這段程式執行慢的話,你就會發現程序之間的切換了。
print(y)
if __name__ == '__main__':
p_list= []
for i in range(10):
p = Process(target=func,args=('姑娘%s'%i,'來玩啊!'))
p_list.append(p)
p.start()
[ap.join() for ap in p_list] #4、這是解決辦法,前提是我們的子程序全部都已經去執行了,那麼我在一次給所有正在執行的子程序加上join,那麼主程序就需要等著所有子程序執行結束才會繼續執行自己的程式了,並且保障了所有子程序是非同步執行的。
# p.join() #1、如果加到for迴圈裡面,那麼所有子程序包括父程序就全部變為同步了,因為for迴圈也是主程序的,迴圈第一次的時候,一個程序去執行了,然後這個程序就join住了,那麼for迴圈就不會繼續執行了,等著第一個子程序執行結束才會繼續執行for迴圈去建立第二個子程序。
#2、如果我不想這樣的,也就是我想所有的子程序是非同步的,然後所有的子程序執行完了再執行主程序
#p.join() #3、如果這樣寫的話,多次執行之後,你會發現會出現主程序的程式比一些子程序先執行完,因為我們p.join()是對最後一個子程序進行了join,也就是說如果這最後一個子程序先於其他子程序執行完,那麼主程序就會去執行,而此時如果還有一些子程序沒有執行完,而主程序執行
#完了,那麼就會先列印主程序的內容了,這個cpu排程程序的機制有關係,因為我們的電腦可能只有4個cpu,我的子程序加上住程序有11個,雖然我for迴圈是按順序起程序的,但是作業系統一定會按照順序給你執行你的程序嗎,答案是不會的,作業系統會按照自己的演算法來分配進
#程給cpu去執行,這裡也解釋了我們打印出來的子程序中的內容也是沒有固定順序的原因,因為列印結果也需要呼叫cpu,可以理解成程序在爭搶cpu,如果同學你想問這是什麼演算法,這就要去研究作業系統啦。那我們的想所有子程序非同步執行,然後再執行主程序的這個需求怎麼解決啊
print('不要錢~~~~~~~~~~~~~~~~!')
方式二:自定義類,繼承Process
栗子:
from multiprocessing import Process
class MyProcess(Process):# 自定義類,繼承Process
def __init__(self,n): # 傳參
super().__init__() #別忘了執行父類的init,等價於在__init__的括號中列出父類中的例項變數並繫結到自己的物件
self.n = n
def run(self): # 必須要重寫的
print('寶寶and%s不可告人的事情'%self.n)
if __name__ == '__main__':
p1 = MyProcess('高望')
p1.start()
class MyProcess(Process): #自己寫一個類,繼承Process類
#我們通過init方法可以傳引數,如果只寫一個run方法,那麼沒法傳引數,因為建立物件的是傳參就是在init方法裡面,面向物件的時候,我們是不是學過
def __init__(self,person):
super().__init__()
self.person=person
def run(self):
print(os.getpid())
print(self.pid)
print(self.pid)
print('%s 正在和女主播聊天' %self.person)
# def start(self):
# #如果你非要寫一個start方法,可以這樣寫,並且在run方法前後,可以寫一些其他的邏輯
# self.run()
if __name__ == '__main__':
p1=MyProcess('Jedan')
p2=MyProcess('太白')
p3=MyProcess('alexDSB')
p1.start() #start內部會自動呼叫run方法
p2.start()
# p2.run()
p3.start()
p1.join()
p2.join()
p3.join()
兩種傳參方式
程序的建立方式有兩種,相對應的傳參方式也是兩種.
演示兩種傳參方式(對應著程序的兩種建立方式)
# 演示兩種傳參方式(對應著程序的兩種建立方式)
# 程序的建立方式1,傳參方式1
from multiprocessing import Process
def f1(n): # 通過目標函式傳參
print(n)
if __name__ == '__main__':
# p1 = Process(target=f1,args=('大力與奇蹟',)) #建立程序物件,並傳參
p1 = Process(target=f1,kwargs={'n':'大力'}) #建立程序物件,並傳參
p1.start() #給作業系統傳送了一個建立程序的訊號,後續程序的建立都是作業系統的事兒了
# 程序的建立方式2,傳參方式2
from multiprocessing import Process
class MyProcess(Process):
def __init__(self,n): # 通過自定義類的__init__傳參
super().__init__() #別忘了執行父類的init
self.n = n
def run(self):
print('寶寶and%s不可告人的事情'%self.n)
if __name__ == '__main__':
p1 = MyProcess('高望')
p1.start()