
Hadoop學習筆記-Hadoop HDFS環境搭建
資源下載
1、JDK下載: 下載連結
2、hadoop: 下載連結
3、下載完成後驗證一下下載,將計算的MD5值與官網的進行對比已驗證安裝包的準確性:
md5sum ./hadoop-2.6.*.tar.gz | tr "a-z" "A-Z" # 計算md5值,並轉化為大寫,方便比較一、建立Hadoop使用者
建立hadoop使用者,並分配以使用者名稱為家目錄/home/hadoop,並將其加入到sudo使用者組,建立好使用者之後,以hadoop使用者登入:
sudo useradd -m hadoop -s /bin/bash
sudo adduser hadoop sudo 二、安裝JDK、Hadoop及配置環境變數
安裝,解壓JDK到/usr/lib/java/路徑下,Hadoop到/usr/local/etc/hadoop/路徑下:
tar zxf ./hadoop-2.6.*.tar.gz
mv ./hadoop-2.6.* /usr/local/etc/hadoop # 將 /usr/local/etc/hadoop作為Hadoop的安裝路徑解壓完成之後,可驗證hadoop的可用性:
cd /usr/local/etc/hadoop
./bin/hadoop version 若在此處,會出現類似以下的錯誤資訊,則很有可能是該安裝包有問題。
Error: Could not find or load main class org.apache.hadoop.util.VersionInfo配置環境,編輯“/etc/profile”檔案,在其後新增如下資訊:
export HADOOP_HOME=/usr/local/etc/hadoop
export JAVA_HOME=/usr/lib/java/jdk1.8.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME} 使配置的變數生效:
source /etc/profile三、測試一下
在此我們可以執行一個簡單的官方Demo:
cd `echo $HADOOP_HOME` # 到hadoop安裝路徑
mkdir ./input
cp ./etc/hadoop/*.xml ./input
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'輸出的結果應該會是:
1 dfsadmin - 這裡有一點需要注意,該Example程式執行時不能已存在
output目錄,否則或將無法執行!
四、Hadoop的偽分散式環境搭建
什麼是偽分散式?Hadoop 偽分散式模式是在一臺機器上模擬Hadoop分散式,單機上的分散式並不是真正的分散式,而是使用執行緒模擬的分散式。分散式和偽分散式這兩種配置也很相似,唯一不同的地方是偽分散式是在一臺機器上配置,也就是名位元組點(namenode)和資料節點(datanode)均是同一臺機器。
需要配置的檔案有core-site.xml和hdfs-site.xml這兩個檔案他們都位於${HADOOP_HOME}/etc/hadoop/資料夾下。
其中core-site.xml:
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed ...
-->
18
19 <configuration>
20 <property>
21 <name>hadoop.tmp.dir</name>
22 <value>file:/home/hadoop/tmp</value>
23 <description>Abase for other temporary directories.</description>
24 </property>
25 <property>
26 <name>fs.default.name</name>
27 <value>hdfs://master:9000</value>
28 </property>
29 </configuration> 檔案hdfs-site.xml的配置如下:
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed ...
-->
18
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>1</value>
23 </property>
24 <property>
25 <name>dfs.namenode.name.dir</name>
26 <value>file:/home/hadoop/tmp/dfs/name</value>
27 </property>
28 <property>
29 <name>dfs.datanode.data.dir</name>
30 <value>file:/home/hadoop/tmp/dfs/data</value>
31 </property>
32 </configuration>配置完成後,執行格式化命令,使HDFS將制定的目錄進行格式化:
hdfs namenode -format若格式化成功,在臨近輸出的結尾部分可看到如下資訊:

五、啟動HDFS
啟動HDFS的指令碼位於Hadoop目錄下的sbin資料夾中,即:
cd `echo $HADOOP_HOME`
./sbin/start-dfs.sh # 啟動HDFS指令碼在執行start-dfs.sh指令碼啟動HDFS時,可能出現類似如下的報錯內容:
localhost: Error: JAVA_HOME is not set and could not be found.很明顯,是JAVA_HOME沒找到,這是因為在hadoop-env.sh指令碼中有個JAVA_HOME=${JAVA_HOME},所以只需將${JAVA_HOME}替換成你的JDK的路徑即可解決:
echo $JAVA_HOME # /usr/lib/java/jdk1.*.*_**
vim ./etc/hadoop/hadoop-env.sh # 將‘export JAVA_HOME=${JAVA_HOME}’欄位替換成‘export JAVA_HOME=/usr/lib/java/jdk1.*.*_**’即可再次執行
`echo $HADOOP_HOME`/sbin/start-all.sh如果成功,應該會有如下輸出:

也可以執行以下命令判斷是否啟動:
jps若已成功執行起來了,會有類似如下輸出:
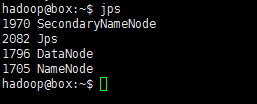
對了,初次執行貌似還有兩次確認,輸入“yes”即是。對應的啟動,自然也有關閉咯:
`echo $HADOOP_HOME`/sbin/stop-dfs.sh六、執行偽分散式例項
以上的“四、測試一下”只是使用的是本機的源生檔案執行的測試Demo例項。既然搭建好了偽分散式的環境,那就使用分散式上儲存(HDFS)的資料來進行一次Demo測試:
- 先將資料來源搞定,也就是仿照“四”中的Demo一樣,新建一個資料夾作為資料來源目錄,並新增一些資料:
hdfs dfs -mkdir /input # 這裡的檔名必須要以‘/’開頭,暫時只瞭解是hdfs是以絕對路徑為基礎,因為沒有 ‘-cd’這樣的命令支援
hdfs dfs -put `echo $HADOOP_HOME`/etc/hadoop/*.xml /input也可以檢視此時新建的input目錄裡面有什麼:
hdfs dfs -ls /
hdfs dfs -ls /input 再次執行如之前執行的那個Demo
hadoop jar /usr/local/etc/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+'可看見如下輸出:
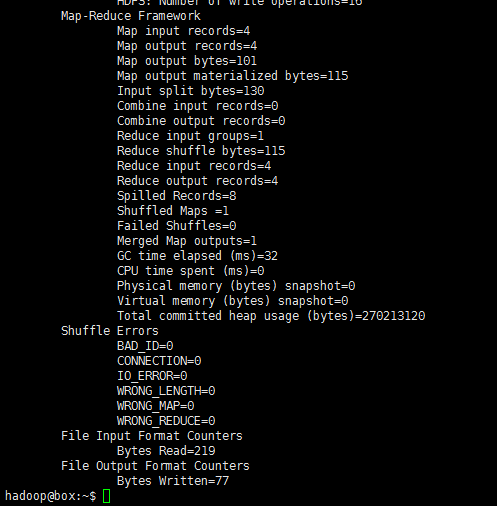
再次檢視HDFS中的目錄:
hdfs dfs -ls /
hdfs dfs -cat /output*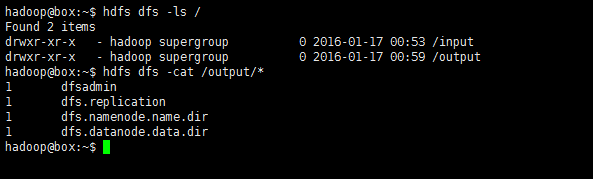
如此,該測試算式通過了。HDFS支援的操作hdfs dfs -command中的‘command’也可通過只鍵入hdfs dfs即可檢視:
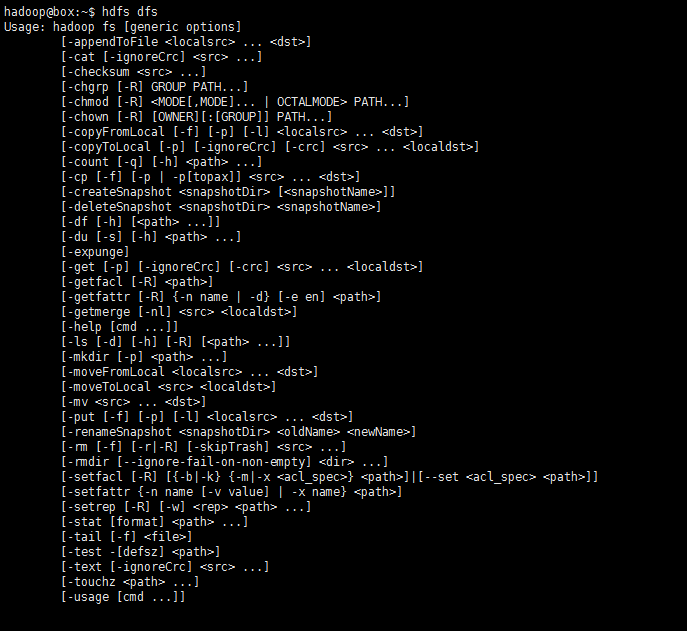
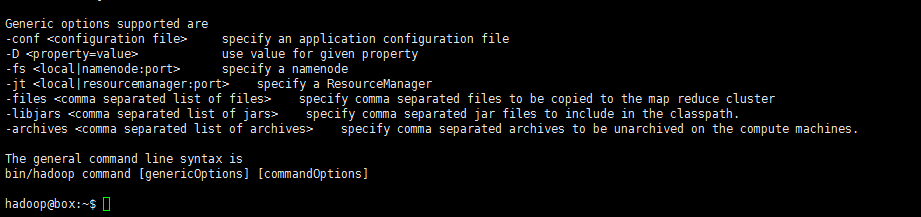
七、Hadoop叢集安裝
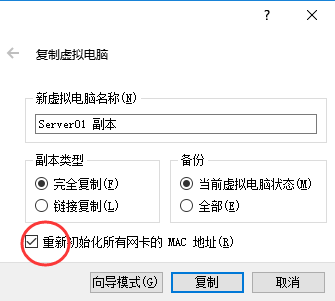
關乎叢集,必然需要各太機器間能夠通訊,所以需配置使每臺虛擬機器的網絡卡連線方式為“橋接網絡卡”,並且他們的MAC地址一定不能有相同。配置叢集所需的三臺Linux虛擬機器都執行在VirtualBox虛擬機器上,既然已經配置好了一臺的環境,可以使用virtualbox的複製功能,直接複製兩臺出來。
先關閉虛擬機器,右鍵點選已配置好的那臺Linux虛擬機器,選擇“複製”,在複製選項中一定要確認“初始化MAC地址“:
- 配置master
為便於區別master和slave,將作為master的主機名改為”master“,修改/etc/hostname檔案,將裡面以前的名稱替換成‘master’:
sudo vim /etc/hostname修改master以及所有slave主機上的IP地址對映關係,新增master機器的IP以及slave機器的IP及對應的機器名稱:
sudo vim /etc/hosts
#vim:
8 192.168.2.109 master
9 192.168.2.119 slave01 # 對應的第一個slav主機的名稱
10 192.168.2.129 slave02 # 對應的第二個slav主機的名稱修改完成之後重啟一下虛擬機器,重啟之後驗證一下是否能互相ping通:
master主機上ping所有:

slave01主機上ping所有:

- @ 這裡所使用的IP地址,最好配置成靜態的IP,配置靜態IP可參考配置靜態IP地址
master配置SSH無密碼登陸slave節點
這個操作是要讓master節點可以無需密碼通過SSH登陸到各個slave節點上
安裝openssh-server,生成金鑰,配置無密碼登入:
sudo apt-get install openssh-server
cd ~ # 進入hadoop使用者目錄下
mkdir .ssh & cd ./.ssh # keygen存放的位置
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys # 加入授權然後將生成的金鑰複製到其他的slave主機上,期間需要輸入‘yes’確認傳輸和輸入密碼以認證身份:
scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop
scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop接著在各個slave節點上將ssh公鑰加入授權:
cd ~
mkdir .ssh # 若是已經存在了,就先把它刪掉
cat id_rsa.pub >> ./.ssh/authorized_keys
rm id_rsa.pub # 已使用執行完以上操作,便可測試一下在master上無密碼ssh連線slave節點的主機了:
ssh slave01
配置叢集/分散式環境
配置分散式叢集環境需對一下幾個檔案進行配置:
slaves: 檔案 slaves,配置datanode的主機名,每行一個,預設為 localhost,所以在偽分散式配置時,節點即作為namenode也作為datanode。分散式配置可以保留localhost,也可以刪掉,讓master節點僅作為namenode使用。現配置兩個slave則在該檔案中編輯如下欄位:
slave01 slave02core-site.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed ... --> 18 19 <configuration> 20 <property> 21 <name>hadoop.tmp.dir</name> <!-- Hadoop的預設臨時檔案存放路徑 --> 22 <value>file:/home/hadoop/tmp</value> 23 <description>Abase for other temporary directories.</description> 24 </property> 25 <property> 26 <name>fs.defaultFS</name> <!-- namenode的URI --> 27 <value>hdfs://master:9000</value> 28 </property> 29 </configuration>hdfs-site.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed ... --> 18 19 <configuration> 20 <property> 21 <name>dfs.replication</name> <!-- 資料節點個數 --> 22 <value>2</value> 23 </property> 24 <property> 25 <name>dfs.namenode.name.dir</name> <!--namenode節點的namenode儲存URL --> 26 <value>file:/home/hadoop/tmp/dfs/name</value> 27 </property> 28 <property> 29 <name>dfs.datanode.data.dir</name> 30 <value>file:/home/hadoop/tmp/dfs/data</value> 31 </property> 32 <property> 33 <name>dfs.namenode.secondary.http-address</name> 34 <value>master:50090</value> 35 </property> 36 </configuration>mapred-site.xml,該檔案一開始為一個模版,所以先拷貝並重命名一份:
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlvim:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed --> 18 19 <configuration> 20 <property> 21 <name>mapreduce.framework.name</name> 22 <value>yarn</value> 23 </property> 24 <property> 25 <name>mapreduce.jobhistory.address</name> 26 <value>master:10020</value> 27 </property> 28 <property> 29 <name>mapreduce.jobhistory.webapp.address</name> 30 <value>master:19888</value> 31 </property> 32 </configuration>yarn-site.xml:
1 <?xml version="1.0"?> 2 <!-- 3 Licensed ... --> 15 <configuration> 16 <!-- Site specific YARN configuration properties --> 17 <property> 18 <name>yarn.resourcemanager.hostname</name> 19 <value>master</value> 20 </property> 21 <property> 22 <name>yarn.nodemanager.aux-services</name> 23 <value>mapreduce_shuffle</value> 24 </property> 25 </configuration>這些配置檔案其他的相關配置可參考官方文件。配置好後,因為之前有跑過偽分散式模式,建議在切換到叢集模式前先刪除之前的臨時檔案:
cd `echo $HADOOP_HOME`
rm -rf ./tmp/
rm -rf ./logs再將配置好的master上的/usr/local/etc/hadoop資料夾複製到各個節點上(也就是覆蓋原來的slave節點上安裝的hadoop)。
以上步驟完畢後,首次啟動需要先在master節點執行namenode的格式化:
hdfs namenode -format # 首次執行需要執行初始化,之後並不需要接著可以啟動hadoop了,啟動需要在master節點上進行:
cd `echo $HADOOP_HOME/etc/hadoop`
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver執行結果:
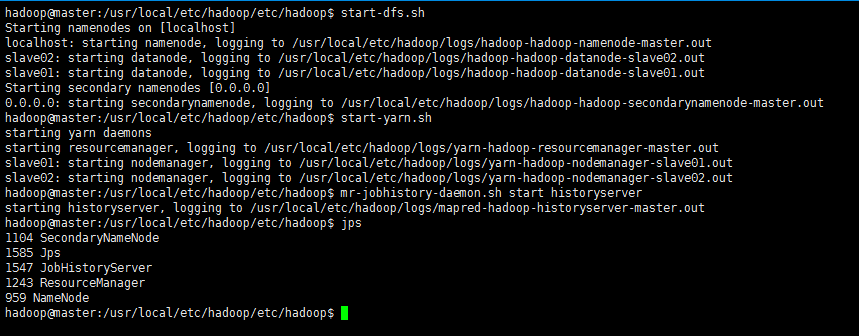
再使用jps檢視啟動之後的狀態:
jps
此時,到slave主機上檢視(jps)狀態,會發現:
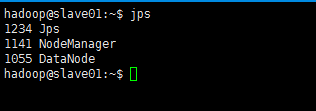
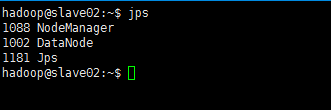
- 缺少任一程序都表示出錯。另外還需要在 master 節點上通過命令
hdfs dfsadmin -report -live檢視 datanode 是否正常啟動,如果 Live datanodes 不為 0 ,則說明叢集啟動成功。例如在此配置了兩個datanode,則這邊一共有 2 個 datanodes:
hdfs dfsadmin -refreshNodes八、HDFS叢集例項測試
依然是之前的那個示例,首先,建立一個數據原始檔夾,並新增資料:
hdfs dfs -mkdir /input
hdfs dfs -put /usr/local/etc/hadoop/etc/hadoop/*.xml /input執行mapreduce示例:
hadoop jar /usr/local/etc/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+'holding…