
IDEA 中開發第一個Spark 程式
阿新 • • 發佈:2019-01-09
1. 建立一個Maven 專案
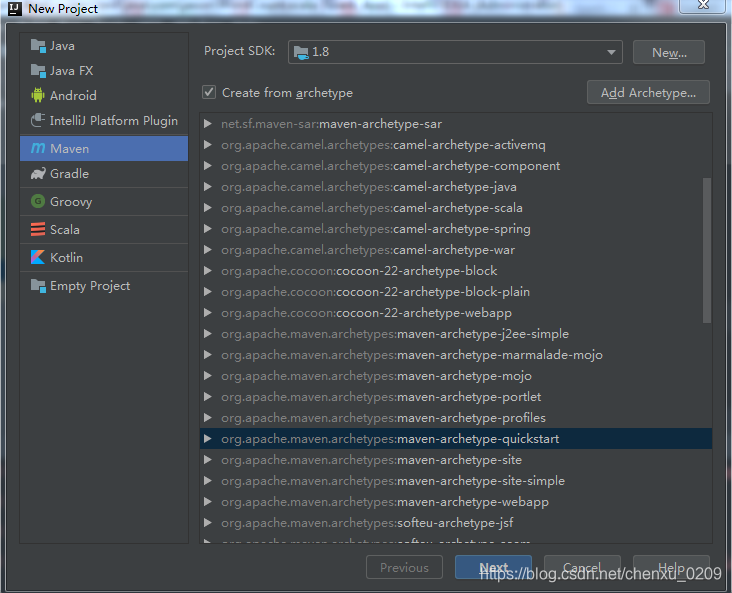
2. 新增SCALA依賴庫
****注意scala 的版本 相對於spark2.4 ,scala 的版本必須是2.11.x
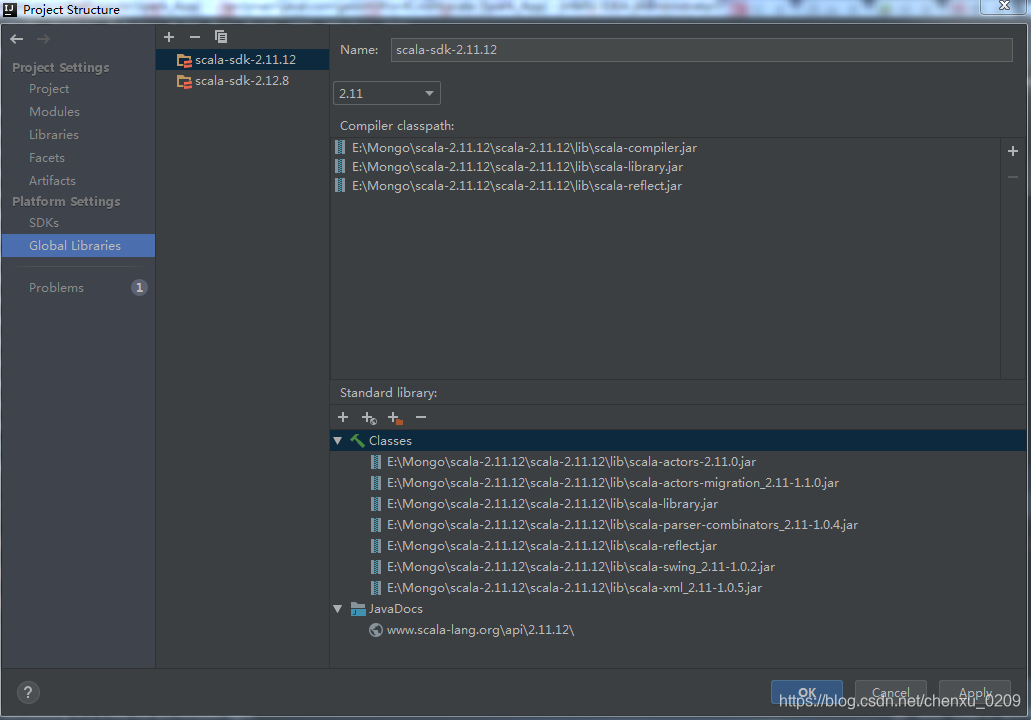
修改POM.xml 檔案
加入 hadoop-client 和spark-core_2.11 的庫依賴
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId 在經過一段漫長的等待之後,可以發現所有依賴的JAR包都下載完畢,並新增到依賴的庫中
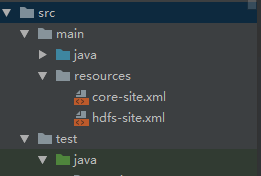
3. HDFS client 的配置
把Hadoop_home下的配置檔案拷貝到專案中
$HADOOP_HOME/etc/hadoop/下的檔案 core-site.xml 和hdfs-site.xml 拷貝到Maven 專案的的resources 的資料夾下
*** 注意resources 資料夾的路徑層級 是在/src/main/resources
本次實驗從HDFS讀取的測試檔案如下
[[email protected] 3. 編寫WorldCount 程式
建立一個 Scala 的 object : WorldCount
package com.jason
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//初始化conf配置
val sparkConf = new SparkConf()
.setAppName("WordCount sample")
// .setMaster("192.168.1.10:4040")
.setMaster("local[2]")
.set("spark.testing.memory", "2147480000");
val sc = new SparkContext(sparkConf);
val rdd = sc.textFile("/user/hadoop/worddir/word.txt");
val tupleRDD = rdd.flatMap(line => {line.split(" ")
.toList.map(word => (word.trim,1))
});
val resultRDD :RDD[(String,Int)] =tupleRDD.reduceByKey((a,b)=> a + b);
resultRDD.foreach(elm => println(elm._1+"="+elm._2));
Thread.sleep(10000);
sc.stop();
}
}
4. 檢視輸出:
18/12/16 16:19:28 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 93 ms
18/12/16 16:19:28 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 94 ms
Jason=2
TJ=2
Bye=3
chen=1
welcome=2
18/12/16 16:19:28 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 1138 bytes result sent to driver
18/12/16 16:19:28 INFO Executor: Finished task 1.0 in stage 1.0 (TID 3). 1138 bytes result sent to driver