
HDFS全面解析涉及基礎、命令、API
HDFS(Hadoop Distributed File System)是Hadoop專案的核心子專案,是分散式計算中資料儲存管理的基礎,是基於流資料模式訪問和處理超大檔案的需求而開發的,可以運行於廉價的商用伺服器上。它所具有的高容錯、高可靠性、高可擴充套件性、高獲得性、高吞吐率等特徵為海量資料提供了不怕故障的儲存,為超大資料集(Large Data Set)的應用處理帶來了很多便利。
Hadoop整合了眾多檔案系統,在其中有一個綜合性的檔案系統抽象,它提供了檔案系統實現的各類介面,HDFS只是這個抽象檔案系統的一個例項。提供了一個高層的檔案系統抽象類org.apache.hadoop.fs.FileSystem,這個抽象類展示了一個分散式檔案系統,並有幾個具體實現,如下表1-1所示。
表1-1 Hadoop的檔案系統
|
檔案系統 |
URI方案 |
Java實現 (org.apache.hadoop) |
定義 |
|
Local |
file |
fs.LocalFileSystem |
支援有客戶端校驗和本地檔案系統。帶有校驗和的本地系統檔案在fs.RawLocalFileSystem中實現。 |
|
HDFS |
hdfs |
hdfs.DistributionFileSystem |
Hadoop的分散式檔案系統。 |
|
HFTP |
hftp |
hdfs.HftpFileSystem |
支援通過HTTP方式以只讀的方式訪問HDFS,distcp經常用在不同的HDFS叢集間複製資料。 |
|
HSFTP |
hsftp |
hdfs.HsftpFileSystem |
支援通過HTTPS方式以只讀的方式訪問HDFS。 |
|
HAR |
har |
fs.HarFileSystem |
構建在Hadoop檔案系統之上,對檔案進行歸檔。Hadoop歸檔檔案主要用來減少NameNode的記憶體使用 |
|
KFS |
kfs |
fs.kfs.KosmosFileSystem |
Cloudstore(其前身是Kosmos檔案系統)檔案系統是類似於HDFS和Google的GFS檔案系統,使用C++編寫。 |
|
FTP |
ftp |
fs.ftp.FtpFileSystem |
由FTP伺服器支援的檔案系統。 |
|
S3(本地) |
s3n |
fs.s3native.NativeS3FileSystem |
基於Amazon S3的檔案系統。 |
|
S3(基於塊) |
s3 |
fs.s3.NativeS3FileSystem |
基於Amazon S3的檔案系統,以塊格式儲存解決了S3的5GB檔案大小的限制。 |
Hadoop提供了許多檔案系統的介面,使用者可以使用URI方案選取合適的檔案系統來實現互動。
2、HDFS基礎概念
2.1 資料塊(block)
- HDFS(Hadoop Distributed File System)預設的最基本的儲存單位是64M的資料塊。
- 和普通檔案系統相同的是,HDFS中的檔案是被分成64M一塊的資料塊儲存的。
- 不同於普通檔案系統的是,HDFS中,如果一個檔案小於一個數據塊的大小,並不佔用整個資料塊儲存空間。
2.2 NameNode和DataNode
HDFS體系結構中有兩類節點,一類是NameNode,又叫"元資料節點";另一類是DataNode,又叫"資料節點"。這兩類節點分別承擔Master和Worker具體任務的執行節點。
1)元資料節點用來管理檔案系統的名稱空間
- 其將所有的檔案和資料夾的元資料儲存在一個檔案系統樹中。
- 這些資訊也會在硬碟上儲存成以下檔案:名稱空間映象(namespace image)及修改日誌(edit log)
- 其還儲存了一個檔案包括哪些資料塊,分佈在哪些資料節點上。然而這些資訊並不儲存在硬碟上,而是在系統啟動的時候從資料節點收集而成的。
2)資料節點是檔案系統中真正儲存資料的地方。
- 客戶端(client)或者元資料資訊(namenode)可以向資料節點請求寫入或者讀出資料塊。
- 其週期性的向元資料節點回報其儲存的資料塊資訊。
3)從元資料節點(secondary namenode)
- 從元資料節點並不是元資料節點出現問題時候的備用節點,它和元資料節點負責不同的事情。
- 其主要功能就是週期性將元資料節點的名稱空間映象檔案和修改日誌合併,以防日誌檔案過大。這點在下面會相信敘述。
- 合併過後的名稱空間映象檔案也在從元資料節點儲存了一份,以防元資料節點失敗的時候,可以恢復。
2.3 元資料節點目錄結構
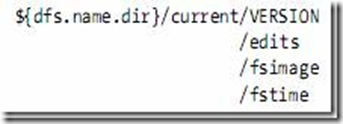
VERSION檔案是java properties檔案,儲存了HDFS的版本號。
- layoutVersion是一個負整數,儲存了HDFS的持續化在硬碟上的資料結構的格式版本號。
- namespaceID是檔案系統的唯一識別符號,是在檔案系統初次格式化時生成的。
- cTime此處為0
- storageType表示此資料夾中儲存的是元資料節點的資料結構。
namespaceID=1232737062
cTime=0
storageType=NAME_NODE
layoutVersion=-18
2.4 資料節點的目錄結構
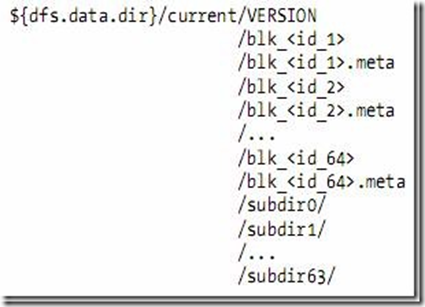
- 資料節點的VERSION檔案格式如下:
namespaceID=1232737062
storageID=DS-1640411682-127.0.1.1-50010-1254997319480
cTime=0
storageType=DATA_NODE
layoutVersion=-18
- blk_<id>儲存的是HDFS的資料塊,其中儲存了具體的二進位制資料。
- blk_<id>.meta儲存的是資料塊的屬性資訊:版本資訊,型別資訊,和checksum
- 當一個目錄中的資料塊到達一定數量的時候,則建立子資料夾來儲存資料塊及資料塊屬性資訊。
2.5 檔案系統名稱空間映像檔案及修改日誌
- 當檔案系統客戶端(client)進行寫操作時,首先把它記錄在修改日誌中(edit log)
- 元資料節點在記憶體中儲存了檔案系統的元資料資訊。在記錄了修改日誌後,元資料節點則修改記憶體中的資料結構。
- 每次的寫操作成功之前,修改日誌都會同步(sync)到檔案系統。
- fsimage檔案,也即名稱空間映像檔案,是記憶體中的元資料在硬碟上的checkpoint,它是一種序列化的格式,並不能夠在硬碟上直接修改。
- 同資料的機制相似,當元資料節點失敗時,則最新checkpoint的元資料資訊從fsimage載入到記憶體中,然後逐一重新執行修改日誌中的操作。
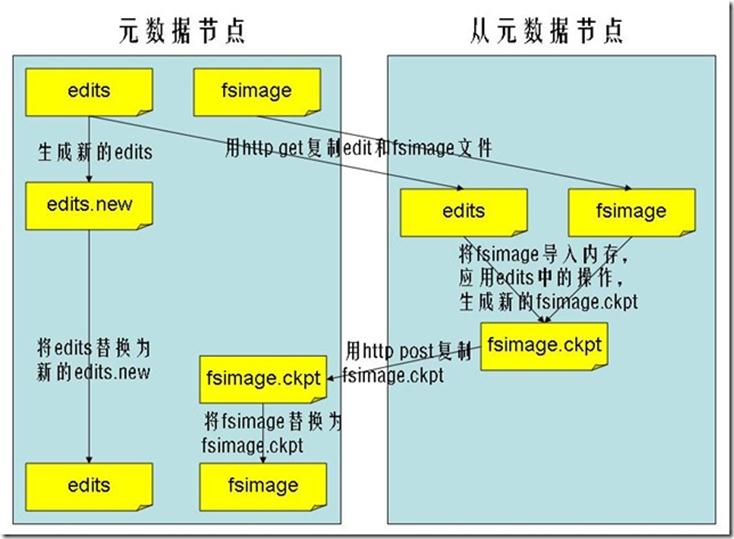
- 從元資料節點就是用來幫助元資料節點將記憶體中的元資料資訊checkpoint到硬碟上的
-
checkpoint的過程如下:
- 從元資料節點通知元資料節點生成新的日誌檔案,以後的日誌都寫到新的日誌檔案中。
- 從元資料節點用http get從元資料節點獲得fsimage檔案及舊的日誌檔案。
- 從元資料節點將fsimage檔案載入到記憶體中,並執行日誌檔案中的操作,然後生成新的fsimage檔案。
- 從元資料節點獎新的fsimage檔案用http post傳回元資料節點
- 元資料節點可以將舊的fsimage檔案及舊的日誌檔案,換為新的fsimage檔案和新的日誌檔案(第一步生成的),然後更新fstime檔案,寫入此次checkpoint的時間。
- 這樣元資料節點中的fsimage檔案儲存了最新的checkpoint的元資料資訊,日誌檔案也重新開始,不會變的很大了。
3、HDFS體系結構
HDFS是一個主/從(Mater/Slave)體系結構,從終端使用者的角度來看,它就像傳統的檔案系統一樣,可以通過目錄路徑對檔案執行CRUD(Create、Read、Update和Delete)操作。但由於分散式儲存的性質,HDFS叢集擁有一個NameNode和一些DataNode。NameNode管理檔案系統的元資料,DataNode儲存實際的資料。客戶端通過同NameNode和DataNodes的互動訪問檔案系統。客戶端聯絡NameNode以獲取檔案的元資料,而真正的檔案I/O操作是直接和DataNode進行互動的。
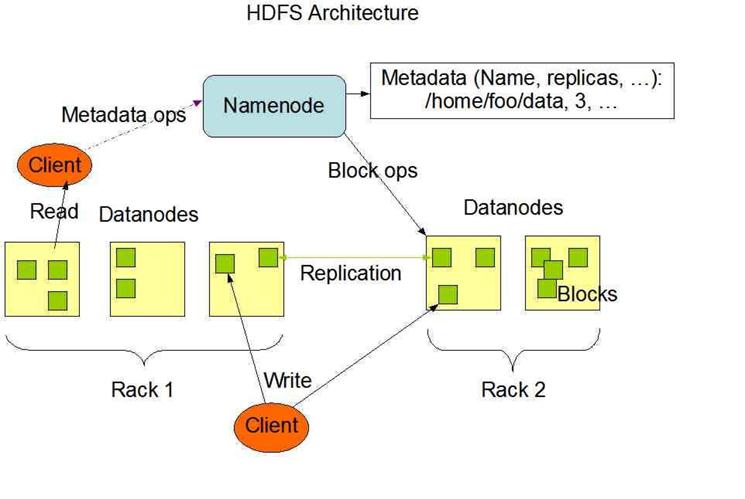
圖3.1 HDFS總體結構示意圖
1)NameNode、DataNode和Client
- NameNode可以看作是分散式檔案系統中的管理者,主要負責管理檔案系統的名稱空間、叢集配置資訊和儲存塊的複製等。NameNode會將檔案系統的Meta-data儲存在記憶體中,這些資訊主要包括了檔案資訊、每一個檔案對應的檔案塊的資訊和每一個檔案塊在DataNode的資訊等。
- DataNode是檔案儲存的基本單元,它將Block儲存在本地檔案系統中,儲存了Block的Meta-data,同時週期性地將所有存在的Block資訊傳送給NameNode。
- Client就是需要獲取分散式檔案系統檔案的應用程式。
2)檔案寫入
- Client向NameNode發起檔案寫入的請求。
- NameNode根據檔案大小和檔案塊配置情況,返回給Client它所管理部分DataNode的資訊。
- Client將檔案劃分為多個Block,根據DataNode的地址資訊,按順序寫入到每一個DataNode塊中。
3)檔案讀取
- Client向NameNode發起檔案讀取的請求。
- NameNode返回檔案儲存的DataNode的資訊。
- Client讀取檔案資訊。
HDFS典型的部署是在一個專門的機器上執行NameNode,叢集中的其他機器各執行一個DataNode;也可以在執行NameNode的機器上同時執行DataNode,或者一臺機器上執行多個DataNode。一個叢集只有一個NameNode的設計大大簡化了系統架構。
4、HDFS的優缺點
4.1 HDFS的優點
1)處理超大檔案
這裡的超大檔案通常是指百MB、設定數百TB大小的檔案。目前在實際應用中,HDFS已經能用來儲存管理PB級的資料了。
2)流式的訪問資料
HDFS的設計建立在更多地響應"一次寫入、多次讀寫"任務的基礎上。這意味著一個數據集一旦由資料來源生成,就會被複製分發到不同的儲存節點中,然後響應各種各樣的資料分析任務請求。在多數情況下,分析任務都會涉及資料集中的大部分資料,也就是說,對HDFS來說,請求讀取整個資料集要比讀取一條記錄更加高效。
3)運行於廉價的商用機器叢集上
Hadoop設計對硬體需求比較低,只須執行在低廉的商用硬體叢集上,而無需昂貴的高可用性機器上。廉價的商用機也就意味著大型叢集中出現節點故障情況的概率非常高。這就要求設計HDFS時要充分考慮資料的可靠性,安全性及高可用性。
4.2 HDFS的缺點
1)不適合低延遲資料訪問
如果要處理一些使用者要求時間比較短的低延遲應用請求,則HDFS不適合。HDFS是為了處理大型資料集分析任務的,主要是為達到高的資料吞吐量而設計的,這就可能要求以高延遲作為代價。
改進策略:對於那些有低延時要求的應用程式,HBase是一個更好的選擇。通過上層資料管理專案來儘可能地彌補這個不足。在效能上有了很大的提升,它的口號就是goes real time。使用快取或多master設計可以降低client的資料請求壓力,以減少延時。還有就是對HDFS系統內部的修改,這就得權衡大吞吐量與低延時了,HDFS不是萬能的銀彈。
2)無法高效儲存大量小檔案
因為Namenode把檔案系統的元資料放置在記憶體中,所以檔案系統所能容納的檔案數目是由Namenode的記憶體大小來決定。一般來說,每一個檔案、資料夾和Block需要佔據150位元組左右的空間,所以,如果你有100萬個檔案,每一個佔據一個Block,你就至少需要300MB記憶體。當前來說,數百萬的檔案還是可行的,當擴充套件到數十億時,對於當前的硬體水平來說就沒法實現了。還有一個問題就是,因為Map task的數量是由splits來決定的,所以用MR處理大量的小檔案時,就會產生過多的Maptask,執行緒管理開銷將會增加作業時間。舉個例子,處理10000M的檔案,若每個split為1M,那就會有10000個Maptasks,會有很大的執行緒開銷;若每個split為100M,則只有100個Maptasks,每個Maptask將會有更多的事情做,而執行緒的管理開銷也將減小很多。
改進策略:要想讓HDFS能處理好小檔案,有不少方法。
- 利用SequenceFile、MapFile、Har等方式歸檔小檔案,這個方法的原理就是把小檔案歸檔起來管理,HBase就是基於此的。對於這種方法,如果想找回原來的小檔案內容,那就必須得知道與歸檔檔案的對映關係。
- 橫向擴充套件,一個Hadoop叢集能管理的小檔案有限,那就把幾個Hadoop叢集拖在一個虛擬伺服器後面,形成一個大的Hadoop叢集。google也是這麼幹過的。
- 多Master設計,這個作用顯而易見了。正在研發中的GFS II也要改為分散式多Master設計,還支援Master的Failover,而且Block大小改為1M,有意要調優處理小檔案啊。
- 附帶個Alibaba DFS的設計,也是多Master設計,它把Metadata的對映儲存和管理分開了,由多個Metadata儲存節點和一個查詢Master節點組成。
3)不支援多使用者寫入及任意修改檔案
在HDFS的一個檔案中只有一個寫入者,而且寫操作只能在檔案末尾完成,即只能執行追加操作。目前HDFS還不支援多個使用者對同一檔案的寫操作,以及在檔案任意位置進行修改。
5、HDFS常用操作
先說一下"hadoop fs 和hadoop dfs的區別",看兩本Hadoop書上各有用到,但效果一樣,求證與網路發現下面一解釋比較中肯。
粗略的講,fs是個比較抽象的層面,在分散式環境中,fs就是dfs,但在本地環境中,fs是local file system,這個時候dfs就不能用。
5.1 檔案操作
1)列出HDFS檔案
此處為你展示如何通過"-ls"命令列出HDFS下的檔案:
hadoop fs -ls
執行結果如圖5-1-1所示。在這裡需要注意:在HDFS中未帶引數的"-ls"命名沒有返回任何值,它預設返回HDFS的"home"目錄下的內容。在HDFS中,沒有當前目錄這樣一個概念,也沒有cd這個命令。

相關推薦
HDFS全面解析涉及基礎、命令、API
1、HDFS簡介 HDFS(Hadoop Distributed File System)是Hadoop專案的核心子專案,是分散式計算中資料儲存管理的基礎,是基於流資料模式訪問和處理超大檔案的需求而開發的,可以運行於廉價的商用伺服器上。它所具有的高容錯、高可靠性
Android WebView使用全面解析(載入網路資源、本地HTML,JS互動)
簡述: WebView是什麼?有什麼用途?我們先來看一下官方介紹: A View that displays web pages. This class is the basis upon which you can roll your own web b
全面解析HTTP/2:歷史、特性、除錯、效能
寫在前面 超文字傳輸協議(英文:HyperText Transfer Protocol,縮寫:HTTP)是網際網路上應用最為廣泛的一種網路協議。設計 HTTP 最初的目的是為了提供一種釋出和接收 HTML 頁面的方法。通過 HTTP 或者 HTTPS 協議請求的資源由統一資源識別符號(URI)來標識。
Nginxa安裝、命令、配置以及核心模組
寫在前面: 負載均衡:請求分發(轉發)–一次請求 反向代理:代理伺服器重新發起請求(重定向)–兩次請求 一、nginx的安裝 1、下載 http://nginx.org/download/ –> ./configure 執行nginx配置檔案
mongoDB學習之路,安裝、配置、啟動、命令、應用(一)
mongoDB初學 mongoDB學習了一段時間,今天整理一下,以便自己回顧,加深印象,同時讓更多mongo初學者有個好的資料。真好 在學習mongoDB之前,我們先了解什麼是mongoDB,以及相關概念 MongoDB 是一個基於分散式檔案儲存的資料庫。由 C++
mongoDB學習之路,安裝、配置、啟動、命令、應用(五)-
上篇說了java連線mongo,並進行增刪改查 這篇說一下spring整合mongo github上也有小demo,很簡單,適合初學者,地址:點選跳轉 1、首先建立maven專案,新增依賴 <!-- mongo驅動 --> <dependen
事件、命令、信號、函數、方法
播放 接下來 dna 撤銷 載體 點擊 rec data- 生產者 搞了這麽多年的技術,一直對 事件與命令、函數與方法的概念模糊不清。今天詳細記錄一下。 函數與方法 第一門語言學習的c語言,老師常說寫一個函數或者庫函數。 其實編程和數學密不可分,以數學為基礎的一門科學。
Kafka體系架構、命令、Go案例
原文地址:https://github.com/WilburXu/blog/blob/master/kafka/Kafka基本架構和命令.md ## Kafka體系架構  :Qt項目建立、編譯、運行和發布過程解析
qt 5 對話 讓我 進度 qmake ctr deploy 設定 設置 轉載請註明出處:CN_Simo。 題解: 本篇內容主講Qt應用從創建到發布的整個過程,旨在幫助讀者能夠快速走進Qt的世界。 本來計劃是講解Qt源碼靜態編譯,如此的話讀者可能並不能清楚地知
Linux基礎命令、快捷鍵、命令操作
linux基礎 Linux基礎操作、快捷鍵、命令Linux命令的執行過程 命令----shell(命令解釋器)-----內核(kernel); 根據命令是否是shell的一部分,將命令分為內部命令和外部命令;內部是shell的一部分,外部命令是由安
1、kvm基礎常用命令操作
dir 命名 刪除 roo works suspend 備份目錄 xml文件 文件 KVM 虛擬機默認的配置文件在 /etc/libvirt/qemu 目錄下,默認是以虛擬機名稱命名的.xml文件,如下: root@xuedianhu:~# ls /etc/libvirt
Shell基礎:介紹、歷史命令、命令不全和別名、通配符、輸入輸入重定向、管道發和作業控制
基礎 一個 直接 1.5 寫到 否則 shel attr tle Shell的介紹 zsh、ksh(yum list |grep zsh 進行查看,然後可以相應的進行安裝) 命令歷史1. /root/.b
Linux發行版介紹、Linux系統基礎使用入門、Linux命令幫助、Linux基礎命令
系統運維 Linux 計算機打的基礎知識:CPU(運算器、控制器)、memory、I/O(輸入設備、輸出設備) 程序運行模式: 用戶空間:user space,us (可執行普通指令) 內核空間:system space (可執行特權指令) POS:Postable Operatin
Linux的文件系統、系統管理類命令、bash基礎特性
系統 Linux Linux的文件系統根文件系統(rootfs) root fileysystem LSB,FHS(Filesystem Heirache Standard)文件系統層級結構標準,如:/etc、/usr、/var、/root、/home、/dev /boot:引導文件存放目錄,內核文
Linux基礎命令、及獲取命令幫助信息
linux基礎命令格式:COMMAND [OPTIONS...] [ARGUMENTS...] COMMAND: 發起一命令:請求內核將某個二進制程序運行為一個進程; 程序 --> 進程 靜態 --> 動態(有生命周期)實例以centos6.5為例。1、ifconfig:查看
Python命令行解析庫——argarse、docopt、click、invoke
argarse、docopt、click命令行示例:基本用法$ python [file].py hello Kyle Hello, Kyle! $ python [file].py goodbye Kyle Goodbye, Kyle!W/選項用法(標誌)$ python [file].py hello -
sqoop命令,mysql導入到hdfs、hbase、hive
tar 新增 對數 lec 規約 協議 系列 聯系 ont 1.測試MySQL連接 bin/sqoop list-databases --connect jdbc:mysql://192.168.1.187:3306/trade_dev --username ‘mysq
Linux命令之bash的基礎特性(1)(命令歷史、命令補全、路徑補全、命令行展開。)
red gin histsize 歷史 管理 滿足 some 補全 條件 命令歷史 history: 環境變量: HISTSIZE:命令歷史記錄的條數 HISTFILE:~/.bash_history HISTFILESIZE:命令歷史文件記錄歷史的條數 h
關於Class物件、類載入機制、虛擬機器執行時記憶體佈局的全面解析和推測
簡介: 本文是對Java的類載入機制,Class物件,反射原理等相關概念的理解、驗證和Java虛擬機器中記憶體佈局的一些推測。本文重點講述瞭如何理解Class物件以及Class物件的作用。 歡迎探討,如有錯誤敬請指正 如需轉載,請註明出處 http://www.cnblogs.com/nul
Python程式設計:使用sys、argparse、click、fire實現命令列解析
python實現指令碼命令列的庫有: 內建庫sys 內建庫argparse 第三方庫click 第三方庫fire 內建庫sys sys.argv 包含命令列引數列表,第一個引數是檔名 sys_demo.py import sys d