
螞蟻金服風險大腦-支付風險識別天池大賽 —— 賽後總結
週末這幾天都忙著東奔西跑,比賽也在週末結束了,故現來總結一波。這次報名螞蟻金服風險大賽主要是為了做個案例,用商業發行版TDH大資料平臺社群版+可拖拽式快速人工智慧平臺Sophon來完成。
資料預處理(編碼2分鐘+執行5分鐘):
上傳至HDFS,用分散式SQL引擎兼資料倉庫來完成用於分析的海量業務資料儲存。用Java處理資料,得到我們需要的格式。至於替換缺失值等操作完全可以在sophon中實現,極為方便。
建模(拖拽2分鐘+調參執行10分鐘):
隨機森林、梯度提升樹、xgboost、svm。沒有不好的演算法,只有不好的資料和引數。所以在演算法選擇上建議大家不要猶豫,隨機森林或xgboost就夠用了。如果你的特徵工程做得好、模型引數調得好,結果自然就會好。
其中隨機森林在每顆樹的深度和樹的個數較高時具有不錯的效果,但耗時相對較久。而xgboost和梯度提升樹在預設引數下,較短的時間內就能獲得相對較好的結果。具體模型的建立過程大家參考前幾篇部落格:
期間,偶然發現一trick思路:
當你拖完下面的運算元後,你的工作已經完成了90%了,sophon就是這麼強大!
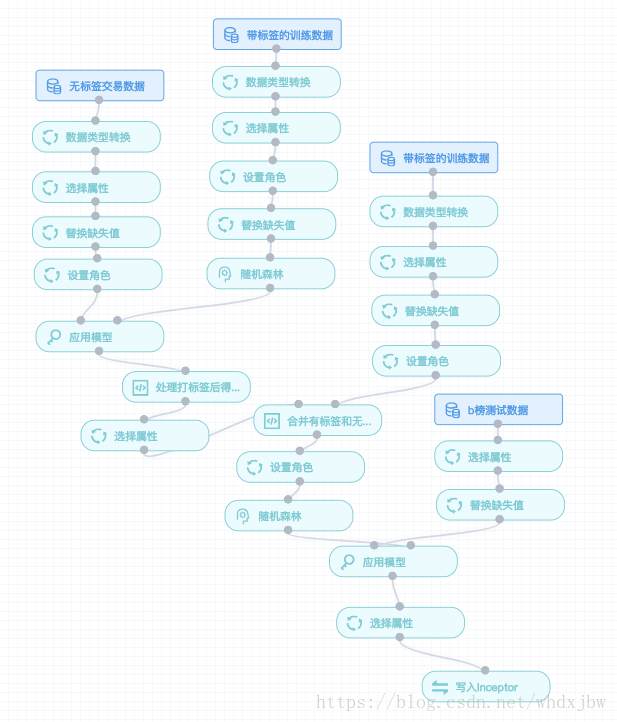
處理輸出資料(編碼2分鐘+執行1分鐘):
這次直接用決定最終成績的B榜資料去測試的,故得到結果直接參與排名。具體模型結果處理參考如下博文:
刷刷刷:
排行榜這種東西是有毒的,會讓你一直想改進自己模型不斷優化,當初本來不是抱著這個目的參賽的,只想做個案例。結果還是中毒了,可能博主比較喜歡剛
結果:

差不多提交了8次,最終成績,看著不錯,其實還沒出線 :
:

可改進的地方:
1、端正參賽動機,不是為了得到第一,就不要去報名!不要認為自己不會中排行榜的毒。
2、無標籤資料其實可以用基於“流形假設”的聚類策略,將高維度支付特徵對映到分佈在流形結構的低維特徵上,這樣能發現風險支付的某些區域性相似特徵。而不是僅僅的用把無標籤資料都當成風險概率為0.65的trick策略(不過這個trick還挺好使)。
3、正常資料與風險資料是100:1,屬於樣本不均衡的情況,我們應當通過隨機欠取樣或隨機過取樣來解決此問題。事實證明,這樣能夠極為明顯地提升模型效果。
4、本次直接把所有特徵資料都送入模型進行了訓練,然而通過觀察資料可以發現實際上有些特徵之間相關度比較高,如缺失都是缺失,不缺失則都大致相近。其實可以PCA計算每個特徵的權重,選擇TopK個權重(根據預先觀察),再將選中的TopK個特徵送入模型訓練,這樣可以大大減少噪聲,由於沒經驗,以為給的資料就是完美的,故沒做此操作,果然還是太年輕。
經過3、4兩步後,模型對風險資料召回率直接飆升至0.735,之前僅有0.56左右,如下圖,感覺應該能進前100了吧:

此時雖然已經知道比賽截止了,但官網上的提交按鈕還能點,故想著用新模型處理得到一波結果,準備提交,然而選中檔案後點擊提交,出現瞭如下彈窗,我果然還是太年輕。。。不過無所謂了,就當把比賽套路都踩了一遍了吧,以後有機會再幹!:

5、模型融合,因為時間原因這次僅僅採用了基於不同模型輸出的結果檔案的平均值策略,其實還可以嘗試其他策略,如stacking、voting、weighting等,其實這次也用了stacking思想,即通過sophon裡的交叉驗證運算元,最終嫌棄跑的太慢就放棄了。
6、學習學習,自己懂得還是太少!通過這次比賽,我發現對資料的敏感度需要建立在基礎理論知識基礎上,否則一切都是假象。這玩意兒就像學物理一樣,需要直觀感受和理論依據以及科學的計算,其實這次賽題隱約感覺和時間序列也有關係,畢竟針對安全的攻擊事件還是會週期性發生的,只是這次沒去做分析。
官方給的建議(比賽結束1個月後才看到這個乾貨)
寫的挺詳細的,我就不在這裡重複了,大家直接移步官方指導就好~
總之,答應大家從頭直播比賽的事情,今天正式圓滿了,大家不要對天池大賽望而生畏啦,各位,加油,英雄榜上風雲四起,怎麼能少了你!!!