
optimizer優化演算法總結
優化方法總結
參考
目錄
1. SGD
3種不同的梯度下降方法,區別在於每次引數更新時計算的樣本資料量不同。
1.1 Batch gradient descent
每進行1次引數更新,需要計算整個資料樣本集:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad1.2 Stochastic gradient descent
每進行1次引數更新,只需要計算1個數據樣本:
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad1.3 Mini-batch gradient descent
每進行1次引數更新,需要計算1個mini-batch資料樣本
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad【三種gradient descent對比】
Batch gradient descent
Stochastic gradient descent雖然大大加速了收斂速度,但是它的梯度下降的波動非常大(high variance)。
Mini-batch gradient descent中和了2者的優缺點,所以SGD演算法通常也預設是Mini-batch gradient descent。
【Mini-batch gradient descent的缺點】
然而Mini-batch gradient descent也不能保證很好地收斂。主要有以下缺點:
選擇一個合適的learning rate是非常困難的
學習率太低會收斂緩慢,學習率過高會使收斂時的波動過大。
所有引數都是用同樣的learning rate
對於稀疏資料或特徵,有時我們希望對於不經常出現的特徵的引數更新快一些,對於常出現的特徵更新慢一些。這個時候SGD就不能滿足要求了。
sgd容易收斂到區域性最優解,並且在某些情況可能被困在鞍點
在合適的初始化和step size的情況下,鞍點的影響沒那麼大。
正是因為SGD這些缺點,才有後續提出的各種演算法。
2. Momentum
momentum利用了物理學中動量的思想,通過積累之前的動量(
其中,
【特點】
- 引數下降初期,加上前一次引數更新值;如果前後2次下降方向一致,乘上較大的
μ 能夠很好的加速。 - 引數下降中後期,在區域性最小值附近來回震盪時,
gradient→0 ,μ 使得更新幅度增大,跳出陷阱。 - 在梯度方向改變時,momentum能夠降低引數更新速度,從而減少震盪;在梯度方向相同時,momentum可以加速引數更新, 從而加速收斂。
- 總而言之,momentum能夠加速SGD收斂,抑制震盪。
3. Nesterov
Nesterov在梯度更新時做一個矯正,避免前進太快,同時提高靈敏度。
Momentum並沒有直接影響當前的梯度
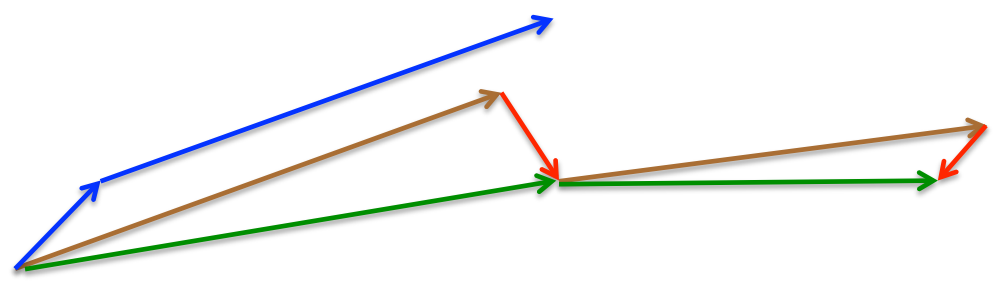
Momentum與Nexterov的對比,如下圖:
Momentum:藍色向量
Momentum首先計算當前的梯度值(短的藍色向量),然後加上之前累計的梯度/動量(長的藍色向量)。
Nexterov:綠色向量
Nexterov首先先計算之前累計的梯度/動量(長的棕色向量),然後加上當前梯度值進行矯正後(
−μ∗mt−1 )的梯度值(紅色向量),得到的就是最終Nexterov的更新值(綠色向量)。
Momentum和Nexterov都是為了使梯度更新更靈活。但是人工設計的學習率總是有些生硬,下面介紹幾種自適應學習率的方法。
4. Adagrad
Adagrad是對學習率進行了一個約束。
這個
【特點】
- 前期
nt 較小的時候,regularizer較大,能夠放大梯度 - 後期
nt 較大的時候,regularizer較小,能夠縮小梯度 - 中後期,分母上梯度平方的累加會越來越大,使
gradie 相關推薦
optimizer優化演算法總結
優化方法總結 參考 目錄 1. SGD 3種不同的梯度下降方法,區別在於每次引數更新時計算的樣本資料量不同。 1.1 Batch gradient descent 每進行1次引數更新,需要計算整個資料樣本集: θ=θ−
深度學習除錯網路時常用的優化演算法總結
自己的小專案在實際除錯中出現過的優化模型的演算法,這裡做一個總結。 1、 學習率調整(避免欠擬合) 2、 正則化(避免過擬合) 3、 Dropout(避免過擬合) 4、 提前終止(避免過擬合) 學習率調整: 在訓練網路的時候,已不變的學習率學習往往不能找到最優解,從而使loss值
常用非線性優化演算法總結
非線性最小二乘 定義:簡單的非線性最小二乘問題可以定義為 \[ \min_{x} \frac{1}{2}||f(x)||^2_2 \] 其中自變數\(x \in R^n\),\(f(x)\)是任意的非線性函式,並設它的維度為\(m\),即\(f(x) \in R^m\). 對於一些最小二乘問題,我們可以利
智慧優化演算法總結
優化演算法有很多,經典演算法包括:有線性規劃,動態規劃等;改進型區域性搜尋演算法包括爬山法,最速下降法等,模擬退火、遺傳演算法以及禁忌搜尋稱作指導性搜尋法。而神經網路,混沌搜尋則屬於系統動態演化方法。 梯度為基礎的傳統優化演算法具有較高的計算效率、較強的可靠性
機器學習中優化演算法總結以及Python實現
機器學習演算法最終總是能轉化為最優化問題,習慣上會轉化為最小化問題。 個人總結迭代優化演算法關鍵就兩點: (1) 找到下降方向 (2) 確定下降步長 最速梯度下降演算法 梯度下降演算法是以最優化函式的梯度為下降方向,學習率η\etaη乘以梯度的模即為下降步長。更
深度學習優化演算法總結
深度學習優化演算法最耳熟能詳的就是GD(Gradient Descend)梯度下降,然後又有一個所謂的SGD(Stochastic Gradient Descend)隨機梯度下降,其實還是梯度下降,只不過每次更新梯度不用整個訓練集而是訓練集中的隨機樣本。梯度下降的好處就是用到了當前迭代的一些性質,以至於總
深度學習優化演算法總結與實驗
深度學習優化演算法最耳熟能詳的就是GD(Gradient Descend)梯度下降,然後又有一個所謂的SGD(Stochastic Gradient Descend)隨機梯度下降,其實還是梯度下降,只不過每次更新梯度不用整個訓練集而是訓練集中的隨機樣本。梯度下降的好處就是用到了當前迭代的一些性質,以至於總
最優化演算法——常見優化演算法分類及總結
之前做特徵選擇,實現過基於群智慧演算法進行最優化的搜尋,看過一些群智慧優化演算法的論文,在此做一下總結。 最優化問題 在生活或者工作中存在各種各樣的最優化問題,比如每個企業和個人都要考慮的一個問題“在一定成本下,如何使利潤最大化”等。最優化方法是一種數學方法,它是研究
機器學習之優化演算法學習總結
優化演算法演化歷程 機器學習和深度學習中使用到的優化演算法的演化歷程如下: SGD –> Momentum –> Nesterov –> Adagrad –> Adadelta –> Adam –> Nadam 表1優化
深度學習總結(一)各種優化演算法
一.優化演算法介紹 1.批量梯度下降(Batch gradient descent,BGD) θ=θ−η⋅∇θJ(θ) 每迭代一步,都要用到訓練集的所有資料,每次計算出來的梯度求平均 η代表學習率LR 2.隨機梯度下降(Stochas
經驗之談:優化演算法兩句話精煉總結
之前,我的部落格中寫了幾種經典的優化演算法和機器學習領域的方法: 學習完畢這麼多優化演算法後,我們可以發現它們的思路無外乎兩個: Exploration,群優化,全域性搜尋,避免陷入區域性最優。 Exploitation,區域
機器學習各優化演算法的簡單總結
1 梯度下降 1.1 SGD 演算法介紹 SGD(Stochasitic Gradient Descent)很簡單,就是沿著梯度的反方向更新引數,優化目標函式。優化公式如下: di=g(θi−1)di=g(θi−1) θi=θi
KMP演算法總結(純演算法,為優化,沒有學應用)
KMP 演算法,俗稱“看毛片”演算法,是字串匹配中的很強大的一個演算法,不過,對於初學者來說,要弄懂它確實不易。整個寒假,因為家裡沒有網,為了理解這個演算法,那可是花了九牛二虎之力!不過,現在我基本上對這個演算法理解算是比較透徹了!特寫此文與大家分享分享! 我個人總結了, KMP 演算法之所以難懂,很大
深度學習總結(五)——各優化演算法
一、各優化演算法簡介 1. 批量梯度下降(Batch gradient descent,BGD) θ=θ−η⋅∇θJ(θ) 每迭代一步,都要用到訓練集所有的資料。 2. 隨機梯度下降(Stochastic Gradient Descent,S
[最全演算法總結]我是如何將遞迴演算法的複雜度優化到O(1)的
相信提到斐波那契數列,大家都不陌生,這個是在我們學習 C/C++ 的過程中必然會接觸到的一個問題,而作為一個經典的求解模型,我們怎麼能少的了去研究這個模型呢?筆者在不斷地學習和思考過程中,發現了這類經典模型竟然有如此多的有意思的求解演算法,能讓這個經典問題的時間複雜度降低到 \(O(1)\) ,下面我想對這個
Unity+NGUI性能優化方法總結
自己 開關 知識 hierarchy .com 最終 需要 監控 com 1 資源分離打包與加載 遊戲中會有很多地方使用同一份資源。比如,有些界面會共用同一份字體、同一張圖集,有些場景會共用同一張貼圖,有些會怪物使用同一個Animator,等等。可以在制作遊戲安裝包
Java集合類操作優化經驗總結
設置 mar ise long 初始化 實際類型 線性表 core 不一定 在實際的項目開發中會有非常多的對象,怎樣高效、方便地管理對象,成為影響程序性能與可維護性的重要環節。Java 提供了集合框架來解決此類問題。線性表、鏈表、哈希表等是經常使用的數據結構,在
Oracle_sql優化基礎——優化器總結
oracle 優化器 cbo 優化器的基礎:1、Oracle裏的優化器: 優化器是Oracle數據庫中內置的一個核心子系統,優化器的目的就是按照一定的判斷原則來得到它認為目標sql在當前情形下最高效的執行路徑,也就是說是為了得到目標sql的執行計劃。 Oracle數據庫的優化器分為:RBO
搜索引擎應用優化技能總結
技能 站點地圖 最好 重定向 收錄 動態 心得 時間 ace 搜索引擎優化是個專業活兒,但大體總結起來分為例如以下幾個方面:平臺的結構優化:1、平臺URL設計整站最好為靜態或偽靜態形式,而非動態形式。(註明:URL為動態結構應盡量鏈接結構參數)是而且全部頁面URL層次均
數據庫SQL優化大總結之 百萬級數據庫優化方案
存儲過程 語句 數字 運行 eat 小型 明顯 where 不能 1.對查詢進行優化,要盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 2.應盡量避免在 where 子句中對字段進行 null 值判斷,否則將導致引擎放棄使用索引而