
OpenCV2.4.13 文字分割(水平垂直,直方圖投影)
進行文字分割時,有多種方法,對與不同情況可以分別處理。
問題1:如何進行文字分割?
答:對於文字是一般正規(不同行的文字一樣高,每一行內部文字大致一樣寬)的文字的情況。
這裡給出了一種方法。
1)對影象二值化
2)對二值化之後的影象進行水平方向投影(找到不同行)
3)利用2)得到的結果對二值化影象切割,然後對每一行進行垂直方向的投影(找到每一行內的不同文字)
4)利用 2)和3)得到的結果畫出方框。
本文是與這裡的方法對應的C++實現,在這裡使用C#實現的。
本文儘量對所使用到的程式碼進行相近的解釋。
- 先讀取圖片
Mat img = imread(IMG_PATH);
if 顯示結果:
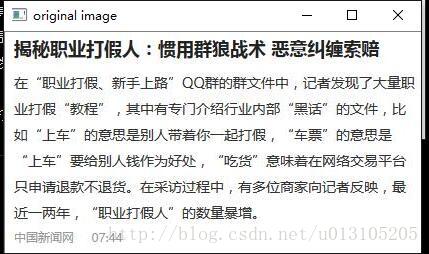
- 第一步:1)對影象二值化
// step 1) 對影象二值化,這裡因為使用 otsu 必須是單通道,
//所以先將影象變成 單通道的影象
Mat gray_img;
cvtColor(img,gray_img,CV_BGR2GRAY,1);
Mat binary_img;
threshold(gray_img,binary_img,90 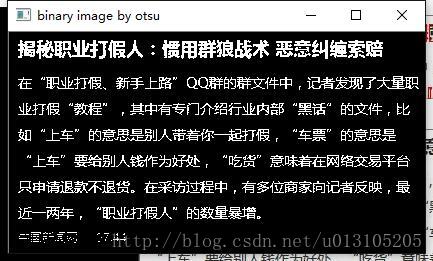
- 第二步:step 2) 對二值化之後的影象進行水平方向投影(找到不同行)
Mat hist_ver;
reduce(binary_img/255,hist_ver,1,CV_REDUCE_SUM,CV_32S);
int width = 5;
int totaln = max(hist_ver.rows,hist_ver.cols);
Mat locations = Mat::zeros(3 問題:reduce()是什麼意思呢?
答:reduce()是,將影象,沿著某個方向,做某種“降維”
這裡的意思是,將影象沿著橫軸做“求和”運算,最後得到的是一個一維向量。
問題:Find_begin_end_len()是什麼鬼呢?
答:自己定義的一個函式,找到直方圖中相連區域的開始與結束部分的位置。
問題:這個函式的想法是什麼呢?
答:輸入:一個表示直方圖的向量h_vec;
輸出:矩陣locations
| 第一行 | 第二行 | 第三行 |
|---|---|---|
| 開始的位置 | 結束的位置 | 這一段不為零的直方圖的長度 |
| begin | end | len |
程式碼如下:
void Find_begin_end_len(Mat h_vec,Mat& locations,int& count, int width){
// locations 為 3*N 大小的 全零的 Mat,
// 經過這個函式處理之後,變成 3*count 大小的矩陣
if (locations.type() != 4 || h_vec.type() != 4)
cout <<"locations and h_vec must be type of CV_32S"<<endl;
// 將 h_vec 變成一個 一行多列 的矩陣,便於處理
if (h_vec.rows != 1)
transpose(h_vec,h_vec);
int N = h_vec.cols;
int begin, end, len;
count = 0;
int n = 0; // number of pixels in h_vec[i]
for (int i = 0; i < N; i++)
{
//cout <<" i is: "<< i<<endl;
n = h_vec.at<int>(0,i);
if (n != 0)
{
begin = i;
for (int j = i; j < N; j++)
{
n = h_vec.at<int>(0,j);
if (n == 0)
{
end = j-1;
len = end - begin;
if (len >= width)
{
locations.at<int>(0,count) = begin;
locations.at<int>(1,count) = end;
locations.at<int>(2,count) = len;
count = count + 1;
//// test if the code is right
//cout <<" begin is: "<< begin<<endl;
//cout <<" end is: "<< end<<endl;
//cout <<" len is: "<< len<<endl;
//cout <<" count is: "<< count<<endl;
}
i = j;
break;
}
}
}
}
}問題:為什麼locations and h_vec must be type of CV_32S?
答:因為直方圖向量是通過對影象進行的操作是 “求和”,因此新得到的直方圖向量中分量的數值可能超出影象畫素型別的範圍。
這裡記錄位置的locations 與 直方圖向量類似是一致的,因此要用CV_32S了。
問題:為什麼一定要是 CV_32S呢?
答:這個,我也不太清楚噢。
不過,CV_32S對應的是 int 型。
- 第三步: step 3)利用2)得到的結果對二值化影象切割,
然後對每一行進行垂直方向的投影(找到每一行內的不同文字)
Mat line;
int x,y,height;
x = 0;
Mat hist_hor;
Mat locations2 = Mat::zeros(3,totaln,CV_32S);
list<Rect> blocks; // 定義一個連結串列
list<Rect>::iterator p_list; // 定義一個連結串列中的迭代器
int count2 = 0;
Rect r1;
int bx,by,bwid,bhei;
width = 2;
for (int i = 0; i < count; i++)
{
y = locations.at<int>(0,i);
height = locations.at<int>(2,i);
line = binary_img(Rect(x , y , binary_img.cols,height));
reduce(line/255,hist_hor,0,CV_REDUCE_SUM,CV_32S);
Find_begin_end_len(hist_hor,locations2,count2,width);
// 利用連結串列儲存 Rect 區域
for (int j = 0; j < count2; j++)
{
bx = locations2.at<int>(0,j);
by = locations.at<int>(0,i);
bwid = locations2.at<int>(2,j);
bhei = locations.at<int>(2,i);
r1 = Rect(bx,by,bwid,bhei);
blocks.push_back(r1);
}
}問題:Rect r1是什麼意思?
答:1)Rect 是一種型別,與 int 類似
2)Rect 是一個函式,Rect(x,y, width,height):指定長方形區域,左上角位於(x,y),矩形大小為,常用來指定roi
這裡是用來記錄,每一個字元所在的位置的。
- 第四步: step 4) 利用 2)和3)得到的結果畫出方框。
Scalar color = Scalar(0, 0, 255);
for (p_list = blocks.begin(); p_list != blocks.end(); p_list++)
rectangle(img,*p_list,color );
imshow("image with box", img);問題:Scalar color 表示什麼意思?
答:Scalar 與 Rect類似,有兩重意義。
不過,Scalar 有更多的含義,這裡只使用到了最簡單的一種。
最終結果:
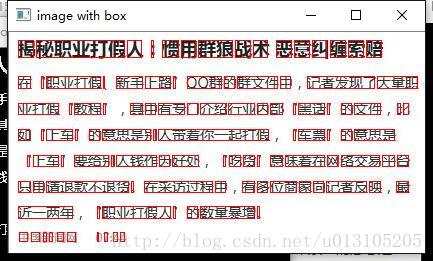
問題:有些字連在了一起,這個要怎麼處理?
答:法一:可以在第一步閾值處理之前或者之後利用形態學濾波做預處理。
不過這樣的話,需要引入更多引數。
法二:可以對最終分在一起的一串數字進行後處理。
不過,這樣的話,本來錯誤分在一起的就不能再分開了。
放大招:整體程式碼如下:
// csdn_code.cpp : 定義控制檯應用程式的入口點。
//
#include "stdafx.h"
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
#define IMG_PATH "..//figures//111.jpg"
void Find_begin_end_len(Mat h_vec,Mat& locations,int& count, int width);
void Find_begin_end_len(Mat h_vec,Mat& locations,int& count, int width){
// locations 為 3*N 大小的 全零的 Mat,
// 經過這個函式處理之後,變成 3*count 大小的矩陣
if (locations.type() != 4 || h_vec.type() != 4)
cout <<"locations and h_vec must be type of CV_32S"<<endl;
// 將 h_vec 變成一個 一行多列 的矩陣,便於處理
if (h_vec.rows != 1)
transpose(h_vec,h_vec);
int N = h_vec.cols;
int begin, end, len;
count = 0;
int n = 0; // number of pixels in h_vec[i]
for (int i = 0; i < N; i++)
{
//cout <<" i is: "<< i<<endl;
n = h_vec.at<int>(0,i);
if (n != 0)
{
begin = i;
for (int j = i; j < N; j++)
{
n = h_vec.at<int>(0,j);
if (n == 0)
{
end = j-1;
len = end - begin;
if (len >= width)
{
locations.at<int>(0,count) = begin;
locations.at<int>(1,count) = end;
locations.at<int>(2,count) = len;
count = count + 1;
//// test if the code is right
//cout <<" begin is: "<< begin<<endl;
//cout <<" end is: "<< end<<endl;
//cout <<" len is: "<< len<<endl;
//cout <<" count is: "<< count<<endl;
}
i = j;
break;
}
}
}
}
}
int main()
{
Mat img = imread(IMG_PATH);
if (img.empty())
{
cerr<<"can not read image"<<endl;
}
imshow("original image", img);
// step 1) 對影象二值化,這裡因為使用 otsu 必須是單通道,
//所以先將影象變成 單通道的影象
Mat gray_img;
cvtColor(img,gray_img,CV_BGR2GRAY,1);
Mat binary_img;
threshold(gray_img,binary_img,90,255,THRESH_OTSU);
binary_img = 255 - binary_img;
imshow("binary image by otsu", binary_img);
// step 2) 對二值化之後的影象進行水平方向投影(找到不同行)
Mat hist_ver;
reduce(binary_img/255,hist_ver,1,CV_REDUCE_SUM,CV_32S);
int width = 5;
int totaln = max(hist_ver.rows,hist_ver.cols);
Mat locations = Mat::zeros(3,totaln,CV_32S);
int count = 0;
Find_begin_end_len(hist_ver,locations,count,width);
// step 3)利用2)得到的結果對二值化影象切割,
// 然後對每一行進行垂直方向的投影(找到每一行內的不同文字)
Mat line;
int x,y,height;
x = 0;
Mat hist_hor;
Mat locations2 = Mat::zeros(3,totaln,CV_32S);
list<Rect> blocks; // 定義一個連結串列
list<Rect>::iterator p_list; // 定義一個連結串列中的迭代器
int count2 = 0;
Rect r1;
int bx,by,bwid,bhei;
width = 2;
for (int i = 0; i < count; i++)
{
y = locations.at<int>(0,i);
height = locations.at<int>(2,i);
line = binary_img(Rect(x , y , binary_img.cols,height));
reduce(line/255,hist_hor,0,CV_REDUCE_SUM,CV_32S);
Find_begin_end_len(hist_hor,locations2,count2,width);
// 利用連結串列儲存 Rect 區域
for (int j = 0; j < count2; j++)
{
bx = locations2.at<int>(0,j);
by = locations.at<int>(0,i);
bwid = locations2.at<int>(2,j);
bhei = locations.at<int>(2,i);
r1 = Rect(bx,by,bwid,bhei);
blocks.push_back(r1);
}
}
// step 4) 利用 2)和3)得到的結果畫出方框。
Scalar color = Scalar(0, 0, 255);
for (p_list = blocks.begin(); p_list != blocks.end(); p_list++)
rectangle(img,*p_list,color );
imshow("image with box", img);
waitKey();
system("pause");
return 0;
}問題:如果有大小不一樣的文字怎麼辦呢?
比如這種:

利用大招中的方法得到的結果是如下:

答:利用這裡的方法。