
L1 L2正規化的詳解以及Scikit-learn上基於L1 L2正規化正則化的例項
一:L1 L2 正則化介紹
監督機器學習問題無非就是“minimizeyour error while regularizing your parameters”,也就是在規則化引數的同時最小化誤差。最小化誤差是為了讓我們的模型擬合我們的訓練資料,而規則化引數是防止我們的模型過分擬合我們的訓練資料。多麼簡約的哲學啊!因為引數太多,會導致我們的模型複雜度上升,容易過擬合,也就是我們的訓練誤差會很小。但訓練誤差小並不是我們的最終目標,我們的目標是希望模型的測試誤差小,也就是能準確的預測新的樣本。所以,我們需要保證模型“簡單”的基礎上最小化訓練誤差,這樣得到的引數才具有好的泛化效能(也就是測試誤差也小),而模型“簡單”就是通過規則函式來實現的。另外,規則項的使用還可以約束我們的模型的特性。這樣就可以將人對這個模型的先驗知識融入到模型的學習當中,強行地讓學習到的模型具有人想要的特性,例如稀疏、低秩、平滑等等。要知道,有時候人的先驗是非常重要的。前人的經驗會讓你少走很多彎路,這就是為什麼我們平時學習最好找個大牛帶帶的原因。一句點撥可以為我們撥開眼前烏雲,還我們一片晴空萬里,醍醐灌頂。對機器學習也是一樣,如果被我們人稍微點撥一下,它肯定能更快的學習相應的任務。只是由於人和機器的交流目前還沒有那麼直接的方法,目前這個媒介只能由規則項來擔當了。
還有幾種角度來看待規則化的。規則化符合奧卡姆剃刀(Occam's razor)原理。這名字好霸氣,razor!不過它的思想很平易近人:在所有可能選擇的模型中,我們應該選擇能夠很好地解釋已知資料並且十分簡單的模型。從貝葉斯估計的角度來看,規則化項對應於模型的先驗概率。民間還有個說法就是,規則化是結構風險最小化策略的實現,是在經驗風險上加一個正則化項(regularizer)或懲罰項(penalty term)。
一般來說,監督學習可以看做最小化下面的目標函式:
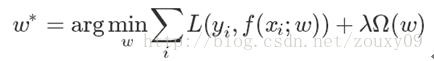
其中,第一項L(yi,f(xi;w)) 衡量我們的模型(分類或者回歸)對第i個樣本的預測值f(xi;w)和真實的標籤yi之前的誤差。因為我們的模型是要擬合我們的訓練樣本的嘛,所以我們要求這一項最小,也就是要求我們的模型儘量的擬合我們的訓練資料。但正如上面說言,我們不僅要保證訓練誤差最小,我們更希望我們的模型測試誤差小,所以我們需要加上第二項,也就是對引數w的規則化函式Ω(w)去約束我們的模型儘量的簡單。
OK,到這裡,如果你在機器學習浴血奮戰多年,你會發現,哎喲喲,機器學習的大部分帶參模型都和這個不但形似,而且神似。是的,其實大部分無非就是變換這兩項而已。對於第一項Loss函式,如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是exp-Loss,那就是牛逼的 Boosting了;如果是log-Loss,那就是Logistic Regression了;還有等等。不同的loss函式,具有不同的擬合特性,這個也得就具體問題具體分析的。但這裡,我們先不究loss函式的問題,我們把目光轉向“規則項Ω(w)”。
規則化函式Ω(w)也有很多種選擇,一般是模型複雜度的單調遞增函式,模型越複雜,規則化值就越大。比如,規則化項可以是模型引數向量的範數。然而,不同的選擇對引數w的約束不同,取得的效果也不同,但我們在論文中常見的都聚集在:零範數、一範數、二範數、跡範數、Frobenius範數和核範數等等。這麼多範數,到底它們表達啥意思?具有啥能力?什麼時候才能用?什麼時候需要用呢?不急不急,下面我們挑幾個常見的娓娓道來。
一、L0範數與L1範數
L0範數是指向量中非0的元素的個數。如果我們用L0範數來規則化一個引數矩陣W的話,就是希望W的大部分元素都是0。這太直觀了,太露骨了吧,換句話說,讓引數W是稀疏的。OK,看到了“稀疏”二字,大家都應該從當下風風火火的“壓縮感知”和“稀疏編碼”中醒悟過來,原來用的漫山遍野的“稀疏”就是通過這玩意來實現的。但你又開始懷疑了,是這樣嗎?看到的papers世界中,稀疏不是都通過L1範數來實現嗎?腦海裡是不是到處都是||W||1影子呀!幾乎是擡頭不見低頭見。沒錯,這就是這節的題目把L0和L1放在一起的原因,因為他們有著某種不尋常的關係。那我們再來看看L1範數是什麼?它為什麼可以實現稀疏?為什麼大家都用L1範數去實現稀疏,而不是L0範數呢?
L1範數是指向量中各個元素絕對值之和,也有個美稱叫“稀疏規則運算元”(Lasso regularization)。現在我們來分析下這個價值一個億的問題:為什麼L1範數會使權值稀疏?有人可能會這樣給你回答“它是L0範數的最優凸近似”。實際上,還存在一個更美的回答:任何的規則化運算元,如果他在Wi=0的地方不可微,並且可以分解為一個“求和”的形式,那麼這個規則化運算元就可以實現稀疏。這說是這麼說,W的L1範數是絕對值,|w|在w=0處是不可微,但這還是不夠直觀。這裡因為我們需要和L2範數進行對比分析。所以關於L1範數的直觀理解,請待會看看第二節。
對了,上面還有一個問題:既然L0可以實現稀疏,為什麼不用L0,而要用L1呢?個人理解一是因為L0範數很難優化求解(NP難問題),二是L1範數是L0範數的最優凸近似,而且它比L0範數要容易優化求解。所以大家才把目光和萬千寵愛轉於L1範數。

OK,來個一句話總結:L1範數和L0範數可以實現稀疏,L1因具有比L0更好的優化求解特性而被廣泛應用。
好,到這裡,我們大概知道了L1可以實現稀疏,但我們會想呀,為什麼要稀疏?讓我們的引數稀疏有什麼好處呢?這裡扯兩點:
1)特徵選擇(Feature Selection):
大家對稀疏規則化趨之若鶩的一個關鍵原因在於它能實現特徵的自動選擇。一般來說,xi的大部分元素(也就是特徵)都是和最終的輸出yi沒有關係或者不提供任何資訊的,在最小化目標函式的時候考慮xi這些額外的特徵,雖然可以獲得更小的訓練誤差,但在預測新的樣本時,這些沒用的資訊反而會被考慮,從而干擾了對正確yi的預測。稀疏規則化運算元的引入就是為了完成特徵自動選擇的光榮使命,它會學習地去掉這些沒有資訊的特徵,也就是把這些特徵對應的權重置為0。
2)可解釋性(Interpretability):
另一個青睞於稀疏的理由是,模型更容易解釋。例如患某種病的概率是y,然後我們收集到的資料x是1000維的,也就是我們需要尋找這1000種因素到底是怎麼影響患上這種病的概率的。假設我們這個是個迴歸模型:y=w1*x1+w2*x2+…+w1000*x1000+b(當然了,為了讓y限定在[0,1]的範圍,一般還得加個Logistic函式)。通過學習,如果最後學習到的w*就只有很少的非零元素,例如只有5個非零的wi,那麼我們就有理由相信,這些對應的特徵在患病分析上面提供的資訊是巨大的,決策性的。也就是說,患不患這種病只和這5個因素有關,那醫生就好分析多了。但如果1000個wi都非0,醫生面對這1000種因素,累覺不愛。
二、L2範數
除了L1範數,還有一種更受寵幸的規則化範數是L2範數: ||W||2。它也不遜於L1範數,它有兩個美稱,在迴歸裡面,有人把有它的迴歸叫“嶺迴歸”(Ridge Regression),有人也叫它“權值衰減weight decay”。這用的很多吧,因為它的強大功效是改善機器學習裡面一個非常重要的問題:過擬合。至於過擬合是什麼,上面也解釋了,就是模型訓練時候的誤差很小,但在測試的時候誤差很大,也就是我們的模型複雜到可以擬合到我們的所有訓練樣本了,但在實際預測新的樣本的時候,糟糕的一塌糊塗。通俗的講就是應試能力很強,實際應用能力很差。擅長背誦知識,卻不懂得靈活利用知識。例如下圖所示(來自Ng的course):
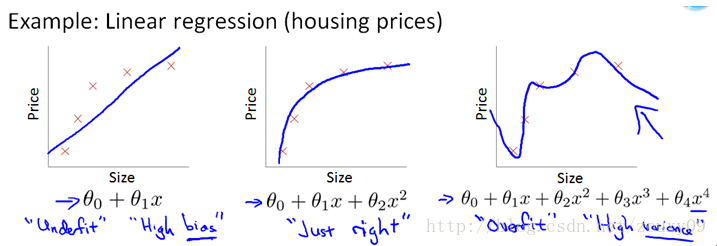
上面的圖是線性迴歸,下面的圖是Logistic迴歸,也可以說是分類的情況。從左到右分別是欠擬合(underfitting,也稱High-bias)、合適的擬合和過擬合(overfitting,也稱High variance)三種情況。可以看到,如果模型複雜(可以擬合任意的複雜函式),它可以讓我們的模型擬合所有的資料點,也就是基本上沒有誤差。對於迴歸來說,就是我們的函式曲線通過了所有的資料點,如上圖右。對分類來說,就是我們的函式曲線要把所有的資料點都分類正確,如下圖右。這兩種情況很明顯過擬合了。
OK,那現在到我們非常關鍵的問題了,為什麼L2範數可以防止過擬合?回答這個問題之前,我們得先看看L2範數是個什麼東西。
L2範數是指向量各元素的平方和然後求平方根。我們讓L2範數的規則項||W||2最小,可以使得W的每個元素都很小,都接近於0,但與L1範數不同,它不會讓它等於0,而是接近於0,這裡是有很大的區別的哦。而越小的引數說明模型越簡單,越簡單的模型則越不容易產生過擬合現象。為什麼越小的引數說明模型越簡單?我也不懂,我的理解是:限制了引數很小,實際上就限制了多項式某些分量的影響很小(看上面線性迴歸的模型的那個擬合的圖),這樣就相當於減少引數個數。其實我也不太懂,希望大家可以指點下。
這裡也一句話總結下:通過L2範數,我們可以實現了對模型空間的限制,從而在一定程度上避免了過擬合。
L2範數的好處是什麼呢?這裡也扯上兩點:
1)學習理論的角度:
從學習理論的角度來說,L2範數可以防止過擬合,提升模型的泛化能力。
2)優化計算的角度:
從優化或者數值計算的角度來說,L2範數有助於處理 condition number不好的情況下矩陣求逆很困難的問題。哎,等等,這condition number是啥?我先google一下哈。
這裡我們也故作高雅的來聊聊優化問題。優化有兩大難題,一是:區域性最小值,二是:ill-condition病態問題。前者俺就不說了,大家都懂吧,我們要找的是全域性最小值,如果區域性最小值太多,那我們的優化演算法就很容易陷入區域性最小而不能自拔,這很明顯不是觀眾願意看到的劇情。那下面我們來聊聊ill-condition。ill-condition對應的是well-condition。那他們分別代表什麼?假設我們有個方程組AX=b,我們需要求解X。如果A或者b稍微的改變,會使得X的解發生很大的改變,那麼這個方程組系統就是ill-condition的,反之就是well-condition的。我們具體舉個例子吧:
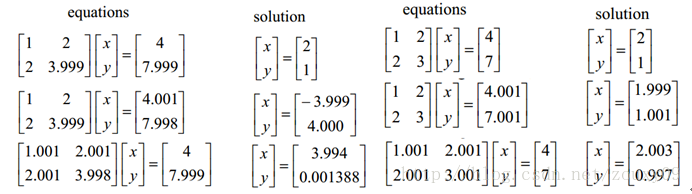
咱們先看左邊的那個。第一行假設是我們的AX=b,第二行我們稍微改變下b,得到的x和沒改變前的差別很大,看到吧。第三行我們稍微改變下係數矩陣A,可以看到結果的變化也很大。換句話來說,這個系統的解對係數矩陣A或者b太敏感了。又因為一般我們的係數矩陣A和b是從實驗資料裡面估計得到的,所以它是存在誤差的,如果我們的系統對這個誤差是可以容忍的就還好,但系統對這個誤差太敏感了,以至於我們的解的誤差更大,那這個解就太不靠譜了。所以這個方程組系統就是ill-conditioned病態的,不正常的,不穩定的,有問題的,哈哈。這清楚了吧。右邊那個就叫well-condition的系統了。
還是再囉嗦一下吧,對於一個ill-condition的系統,我的輸入稍微改變下,輸出就發生很大的改變,這不好啊,這表明我們的系統不能實用啊。你想想看,例如對於一個迴歸問題y=f(x),我們是用訓練樣本x去訓練模型f,使得y儘量輸出我們期待的值,例如0。那假如我們遇到一個樣本x’,這個樣本和訓練樣本x差別很小,面對他,系統本應該輸出和上面的y差不多的值的,例如0.00001,最後卻給我輸出了一個0.9999,這很明顯不對呀。就好像,你很熟悉的一個人臉上長了個青春痘,你就不認識他了,那你大腦就太差勁了,哈哈。所以如果一個系統是ill-conditioned病態的,我們就會對它的結果產生懷疑。那到底要相信它多少呢?我們得找個標準來衡量吧,因為有些系統的病沒那麼重,它的結果還是可以相信的,不能一刀切吧。終於回來了,上面的condition number就是拿來衡量ill-condition系統的可信度的。condition number衡量的是輸入發生微小變化的時候,輸出會發生多大的變化。也就是系統對微小變化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。
如果方陣A是非奇異的,那麼A的conditionnumber定義為:
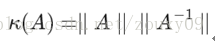
也就是矩陣A的norm乘以它的逆的norm。所以具體的值是多少,就要看你選擇的norm是什麼了。如果方陣A是奇異的,那麼A的condition number就是正無窮大了。實際上,每一個可逆方陣都存在一個condition number。但如果要計算它,我們需要先知道這個方陣的norm(範數)和Machine Epsilon(機器的精度)。為什麼要範數?範數就相當於衡量一個矩陣的大小,我們知道矩陣是沒有大小的,當上面不是要衡量一個矩陣A或者向量b變化的時候,我們的解x變化的大小嗎?所以肯定得要有一個東西來度量矩陣和向量的大小吧?對了,他就是範數,表示矩陣大小或者向量長度。OK,經過比較簡單的證明,對於AX=b,我們可以得到以下的結論:
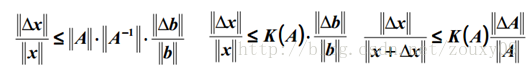
也就是我們的解x的相對變化和A或者b的相對變化是有像上面那樣的關係的,其中k(A)的值就相當於倍率,看到了嗎?相當於x變化的界。
對condition number來個一句話總結:conditionnumber是一個矩陣(或者它所描述的線性系統)的穩定性或者敏感度的度量,如果一個矩陣的condition number在1附近,那麼它就是well-conditioned的,如果遠大於1,那麼它就是ill-conditioned的,如果一個系統是ill-conditioned的,它的輸出結果就不要太相信了。
好了,對這麼一個東西,已經說了好多了。對了,我們為什麼聊到這個的了?回到第一句話:從優化或者數值計算的角度來說,L2範數有助於處理 condition number不好的情況下矩陣求逆很困難的問題。因為目標函式如果是二次的,對於線性迴歸來說,那實際上是有解析解的,求導並令導數等於零即可得到最優解為:
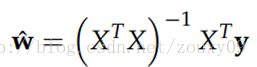
然而,如果當我們的樣本X的數目比每個樣本的維度還要小的時候,矩陣XTX將會不是滿秩的,也就是XTX會變得不可逆,所以w*就沒辦法直接計算出來了。或者更確切地說,將會有無窮多個解(因為我們方程組的個數小於未知數的個數)。也就是說,我們的資料不足以確定一個解,如果我們從所有可行解裡隨機選一個的話,很可能並不是真正好的解,總而言之,我們過擬合了。
但如果加上L2規則項,就變成了下面這種情況,就可以直接求逆了:
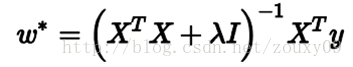
這裡面,專業點的描述是:要得到這個解,我們通常並不直接求矩陣的逆,而是通過解線性方程組的方式(例如高斯消元法)來計算。考慮沒有規則項的時候,也就是λ=0的情況,如果矩陣XTX的 condition number 很大的話,解線性方程組就會在數值上相當不穩定,而這個規則項的引入則可以改善condition number。
另外,如果使用迭代優化的演算法,condition number 太大仍然會導致問題:它會拖慢迭代的收斂速度,而規則項從優化的角度來看,實際上是將目標函式變成λ-strongly convex(λ強凸)的了。哎喲喲,這裡又出現個λ強凸,啥叫λ強凸呢?
當f滿足:
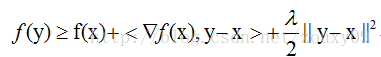
時,我們稱f為λ-stronglyconvex函式,其中引數λ>0。當λ=0時退回到普通convex 函式的定義。
在直觀的說明強凸之前,我們先看看普通的凸是怎樣的。假設我們讓f在x的地方做一階泰勒近似(一階泰勒展開忘了嗎?f(x)=f(a)+f'(a)(x-a)+o(||x-a||).):
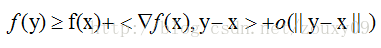
直觀來講,convex 性質是指函式曲線位於該點處的切線,也就是線性近似之上,而 strongly convex 則進一步要求位於該處的一個二次函式上方,也就是說要求函式不要太“平坦”而是可以保證有一定的“向上彎曲”的趨勢。專業點說,就是convex 可以保證函式在任意一點都處於它的一階泰勒函式之上,而strongly convex可以保證函式在任意一點都存在一個非常漂亮的二次下界quadratic lower bound。當然這是一個很強的假設,但是同時也是非常重要的假設。可能還不好理解,那我們畫個圖來形象的理解下。
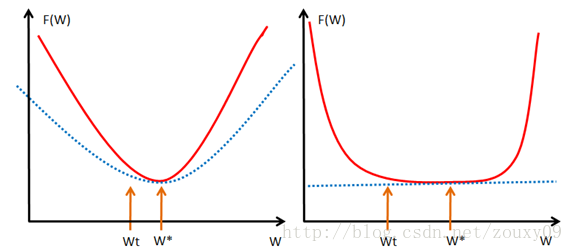
大家一看到上面這個圖就全明白了吧。不用我囉嗦了吧。還是囉嗦一下吧。我們取我們的最優解w*的地方。如果我們的函式f(w),見左圖,也就是紅色那個函式,都會位於藍色虛線的那根二次函式之上,這樣就算wt和w*離的比較近的時候,f(wt)和f(w*)的值差別還是挺大的,也就是會保證在我們的最優解w*附近的時候,還存在較大的梯度值,這樣我們才可以在比較少的迭代次數內達到w*。但對於右圖,紅色的函式f(w)只約束在一個線性的藍色虛線之上,假設是如右圖的很不幸的情況(非常平坦),那在wt還離我們的最優點w*很遠的時候,我們的近似梯度(f(wt)-f(w*))/(wt-w*)就已經非常小了,在wt處的近似梯度∂f/∂w就更小了,這樣通過梯度下降wt+1=wt-α*(∂f/∂w),我們得到的結果就是w的變化非常緩慢,像蝸牛一樣,非常緩慢的向我們的最優點w*爬動,那在有限的迭代時間內,它離我們的最優點還是很遠。
所以僅僅靠convex 性質並不能保證在梯度下降和有限的迭代次數的情況下得到的點w會是一個比較好的全域性最小點w*的近似點(插個話,有地方說,實際上讓迭代在接近最優的地方停止,也是一種規則化或者提高泛化效能的方法)。正如上面分析的那樣,如果f(w)在全域性最小點w*周圍是非常平坦的情況的話,我們有可能會找到一個很遠的點。但如果我們有“強凸”的話,就能對情況做一些控制,我們就可以得到一個更好的近似解。至於有多好嘛,這裡面有一個bound,這個 bound 的好壞也要取決於strongly convex性質中的常數α的大小。看到這裡,不知道大家學聰明瞭沒有。如果要獲得strongly convex怎麼做?最簡單的就是往裡面加入一項(α/2)*||w||2。
呃,講個strongly convex花了那麼多的篇幅。實際上,在梯度下降中,目標函式收斂速率的上界實際上是和矩陣XTX的 condition number有關,XTX的 condition number 越小,上界就越小,也就是收斂速度會越快。
這一個優化說了那麼多的東西。還是來個一句話總結吧:L2範數不但可以防止過擬合,還可以讓我們的優化求解變得穩定和快速。
好了,這裡兌現上面的承諾,來直觀的聊聊L1和L2的差別,為什麼一個讓絕對值最小,一個讓平方最小,會有那麼大的差別呢?我看到的有兩種幾何上直觀的解析:
1)下降速度:
我們知道,L1和L2都是規則化的方式,我們將權值引數以L1或者L2的方式放到代價函式裡面去。然後模型就會嘗試去最小化這些權值引數。而這個最小化就像一個下坡的過程,L1和L2的差別就在於這個“坡”不同,如下圖:L1就是按絕對值函式的“坡”下降的,而L2是按二次函式的“坡”下降。所以實際上在0附近,L1的下降速度比L2的下降速度要快。所以會非常快得降到0。不過我覺得這裡解釋的不太中肯,當然了也不知道是不是自己理解的問題。
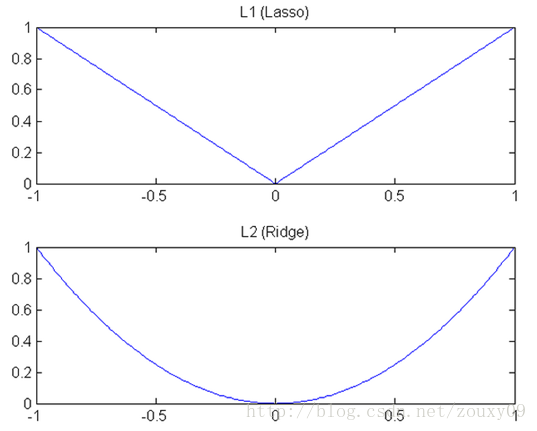
L1在江湖上人稱Lasso,L2人稱Ridge。不過這兩個名字還挺讓人迷糊的,看上面的圖片,Lasso的圖看起來就像ridge,而ridge的圖看起來就像lasso。
2)模型空間的限制:
實際上,對於L1和L2規則化的代價函式來說,我們可以寫成以下形式:
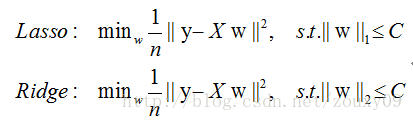
也就是說,我們將模型空間限制在w的一個L1-ball 中。為了便於視覺化,我們考慮兩維的情況,在(w1, w2)平面上可以畫出目標函式的等高線,而約束條件則成為平面上半徑為C的一個 norm ball 。等高線與 norm ball 首次相交的地方就是最優解:
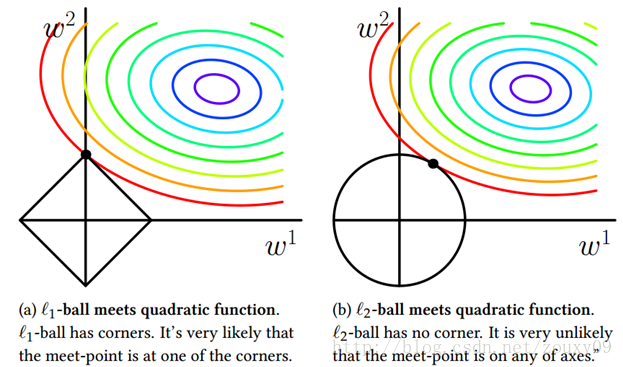
可以看到,L1-ball 與L2-ball 的不同就在於L1在和每個座標軸相交的地方都有“角”出現,而目標函式的測地線除非位置擺得非常好,大部分時候都會在角的地方相交。注意到在角的位置就會產生稀疏性,例如圖中的相交點就有w1=0,而更高維的時候(想象一下三維的L1-ball 是什麼樣的?)除了角點以外,還有很多邊的輪廓也是既有很大的概率成為第一次相交的地方,又會產生稀疏性。
相比之下,L2-ball 就沒有這樣的性質,因為沒有角,所以第一次相交的地方出現在具有稀疏性的位置的概率就變得非常小了。這就從直觀上來解釋了為什麼L1-regularization 能產生稀疏性,而L2-regularization 不行的原因了。
因此,一句話總結就是:L1會趨向於產生少量的特徵,而其他的特徵都是0,而L2會選擇更多的特徵,這些特徵都會接近於0。Lasso在特徵選擇時候非常有用,而Ridge就只是一種規則化而已。
二 scikit-learn上L1 L2正則化的簡單實現:
L1正則化/Lasso
L1正則化將係數w的l1範數作為懲罰項加到損失函式上,由於正則項非零,這就迫使那些弱的特徵所對應的係數變成0。因此L1正則化往往會使學到的模型很稀疏(係數w經常為0),這個特性使得L1正則化成為一種很好的特徵選擇方法。
Scikit-learn為線性迴歸提供了Lasso,為分類提供了L1邏輯迴歸。
下面的例子在波士頓房價資料上運行了Lasso,其中引數alpha是通過grid search進行優化的。
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
boston = load_boston()
scaler = StandardScaler()
X = scaler.fit_transform(boston["data"])
Y = boston["target"]
names = boston["feature_names"]
lasso = Lasso(alpha=.3)
lasso.fit(X, Y)
print "Lasso model: ", pretty_print_linear(lasso.coef_, names, sort = True)Lasso model: -3.707 * LSTAT + 2.992 * RM + -1.757 * PTRATIO + -1.081 * DIS + -0.7 * NOX + 0.631 * B + 0.54 * CHAS + -0.236 * CRIM + 0.081 * ZN + -0.0 * INDUS + -0.0 * AGE + 0.0 * RAD + -0.0 * TAX
可以看到,很多特徵的係數都是0。如果繼續增加alpha的值,得到的模型就會越來越稀疏,即越來越多的特徵係數會變成0。
然而,L1正則化像非正則化線性模型一樣也是不穩定的,如果特徵集合中具有相關聯的特徵,當資料發生細微變化時也有可能導致很大的模型差異。
L2正則化/Ridge regression
L2正則化將係數向量的L2範數新增到了損失函式中。由於L2懲罰項中係數是二次方的,這使得L2和L1有著諸多差異,最明顯的一點就是,L2正則化會讓係數的取值變得平均。對於關聯特徵,這意味著他們能夠獲得更相近的對應係數。還是以Y=X1+X2為例,假設X1和X2具有很強的關聯,如果用L1正則化,不論學到的模型是Y=X1+X2還是Y=2X1,懲罰都是一樣的,都是2alpha。但是對於L2來說,第一個模型的懲罰項是2 alpha,但第二個模型的是4*alpha。可以看出,係數之和為常數時,各系數相等時懲罰是最小的,所以才有了L2會讓各個係數趨於相同的特點。
可以看出,L2正則化對於特徵選擇來說一種穩定的模型,不像L1正則化那樣,係數會因為細微的資料變化而波動。所以L2正則化和L1正則化提供的價值是不同的,L2正則化對於特徵理解來說更加有用:表示能力強的特徵對應的係數是非零。
回過頭來看看3個互相關聯的特徵的例子,分別以10個不同的種子隨機初始化執行10次,來觀察L1和L2正則化的穩定性。
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score
size = 100
#We run the method 10 times with different random seeds
for i in range(10):
print "Random seed %s" % i
np.random.seed(seed=i)
X_seed = np.random.normal(0, 1, size)
X1 = X_seed + np.random.normal(0, .1, size)
X2 = X_seed + np.random.normal(0, .1, size)
X3 = X_seed + np.random.normal(0, .1, size)
Y = X1 + X2 + X3 + np.random.normal(0, 1, size)
X = np.array([X1, X2, X3]).T
lr = LinearRegression()
lr.fit(X,Y)
print "Linear model:", pretty_print_linear(lr.coef_)
ridge = Ridge(alpha=10)
ridge.fit(X,Y)
print "Ridge model:", pretty_print_linear(ridge.coef_)
print
Random seed 0 Linear model: 0.728 * X0 + 2.309 * X1 + -0.082 * X2 Ridge model: 0.938 * X0 + 1.059 * X1 + 0.877 * X2
Random seed 1 Linear model: 1.152 * X0 + 2.366 * X1 + -0.599 * X2 Ridge model: 0.984 * X0 + 1.068 * X1 + 0.759 * X2
Random seed 2 Linear model: 0.697 * X0 + 0.322 * X1 + 2.086 * X2 Ridge model: 0.972 * X0 + 0.943 * X1 + 1.085 * X2
Random seed 3 Linear model: 0.287 * X0 + 1.254 * X1 + 1.491 * X2 Ridge model: 0.919 * X0 + 1.005 * X1 + 1.033 * X2
Random seed 4 Linear model: 0.187 * X0 + 0.772 * X1 + 2.189 * X2 Ridge model: 0.964 * X0 + 0.982 * X1 + 1.098 * X2
Random seed 5 Linear model: -1.291 * X0 + 1.591 * X1 + 2.747 * X2 Ridge model: 0.758 * X0 + 1.011 * X1 + 1.139 * X2
Random seed 6 Linear model: 1.199 * X0 + -0.031 * X1 + 1.915 * X2 Ridge model: 1.016 * X0 + 0.89 * X1 + 1.091 * X2
Random seed 7 Linear model: 1.474 * X0 + 1.762 * X1 + -0.151 * X2 Ridge model: 1.018 * X0 + 1.039 * X1 + 0.901 * X2
Random seed 8 Linear model: 0.084 * X0 + 1.88 * X1 + 1.107 * X2 Ridge model: 0.907 * X0 + 1.071 * X1 + 1.008 * X2
Random seed 9 Linear model: 0.714 * X0 + 0.776 * X1 + 1.364 * X2 Ridge model: 0.896 * X0 + 0.903 * X1 + 0.98 * X2
可以看出,不同的資料上線性迴歸得到的模型(係數)相差甚遠,但對於L2正則化模型來說,結果中的係數非常的穩定,差別較小,都比較接近於1,能夠反映出資料的內在結構。