
機器學習能力自測題——常見簡單機器學習問題,幫助理解應用
一直苦於沒有辦法自測一下機器學習知識掌握程度,最近看到一篇Ankit Gupta寫的部落格:Solutions for Skilltest Machine Learning : Revealed。有40題機器學習自測題,馬上可以看看你的機器學習知識能打幾分?順便還能查漏補缺相關術語,以及SVM, 隱馬爾科夫, 特徵選擇, 神經網路, 線性迴歸等眾多知識點.
以下是試題, 附答案:
Q1:在一個n維的空間中, 最好的檢測outlier(離群點)的方法是:
A. 作正態分佈概率圖
B. 作盒形圖
C. 馬氏距離
D. 作散點圖
答案:C
馬氏距離是基於卡方分佈的,度量多元outlier離群點的統計方法。更多請詳見:
Q2:對數機率迴歸(logistics regression)和一般迴歸分析有什麼區別?:
A. 對數機率迴歸是設計用來預測事件可能性的
B. 對數機率迴歸可以用來度量模型擬合程度
C. 對數機率迴歸可以用來估計迴歸係數
D. 以上所有
答案:D
A: 這個在我們第八期#8提到過,對數機率迴歸其實是設計用來解決分類問題的
B: 對數機率迴歸可以用來檢驗模型對資料的擬合度
C: 雖然對數機率迴歸是用來解決分類問題的,但是模型建立好後,就可以根據獨立的特徵,估計相關的迴歸係數。就我認為,這只是估計迴歸係數,不能直接用來做迴歸模型。
Q3:bootstrap資料是什麼意思?(提示:考“bootstrap”和“boosting”區別)
A. 有放回地從總共M個特徵中抽樣m個特徵
B. 無放回地從總共M個特徵中抽樣m個特徵
C. 有放回地從總共N個樣本中抽樣n個樣本
D. 無放回地從總共N個樣本中抽樣n個樣本
答案:C
Q4:“過擬合”只在監督學習中出現,在非監督學習中,沒有“過擬合”,這是:
A. 對的
B. 錯的
答案:B
我們可以評估無監督學習方法通過無監督學習的指標,如:我們可以評估聚類模型通過調整蘭德係數(adjusted rand score)
Q5:對於k折交叉驗證, 以下對k的說法正確的是 :
A. k越大, 不一定越好, 選擇大的k會加大評估時間
B. 選擇更大的k, 就會有更小的bias (因為訓練集更加接近總資料集)
C. 在選擇k時, 要最小化資料集之間的方差
D. 以上所有
答案:D
k越大, bias越小, 訓練時間越長. 在訓練時, 也要考慮資料集間方差差別不大的原則. 比如, 對於二類分類問題, 使用2-折交叉驗證, 如果測試集裡的資料都是A類的, 而訓練集中資料都是B類的, 顯然, 測試效果會很差.
如果不明白bias和variance的概念, 務必參考下面連結:
Q6:迴歸模型中存在多重共線性, 你如何解決這個問題?
A. 去除這兩個共線性變數
B. 我們可以先去除一個共線性變數
C. 計算VIF(方差膨脹因子), 採取相應措施
D. 為了避免損失資訊, 我們可以使用一些正則化方法, 比如, 嶺迴歸和lasso迴歸.
以下哪些是對的:
A. 1
B. 2
C. 2和3
D. 2, 3和4
答案: D
解決多重公線性, 可以使用相關矩陣去去除相關性高於75%的變數 (有主觀成分). 也可以VIF, 如果VIF值<=4說明相關性不是很高, VIF值>=10說明相關性較高.
我們也可以用 嶺迴歸和lasso迴歸的帶有懲罰正則項的方法. 我們也可以在一些變數上加隨機噪聲, 使得變數之間變得不同, 但是這個方法要小心使用, 可能會影響預測效果.
Q7:模型的高bias是什麼意思, 我們如何降低它 ?
A. 在特徵空間中減少特徵
B. 在特徵空間中增加特徵
C. 增加資料點
D. B和C
E. 以上所有
答案: B
bias太高說明模型太簡單了, 資料維數不夠, 無法準確預測資料, 所以, 升維吧 !
如果不明白bias和variance的概念, 務必參考下面連結:
Q8:訓練決策樹模型, 屬性節點的分裂, 具有最大資訊增益的圖是下圖的哪一個:
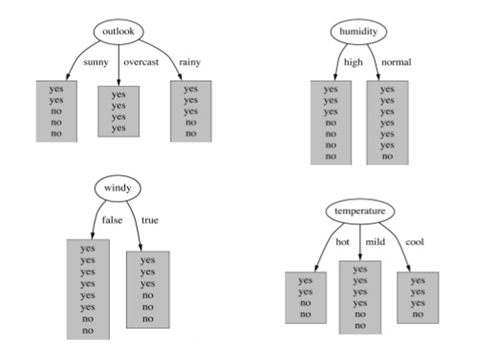
A. Outlook
B. Humidity
C. Windy
D. Temperature
答案: A
資訊增益, 增加平均子集純度, 詳細研究, 請戳下面連結:
Q9:對於資訊增益, 決策樹分裂節點, 下面說法正確的是:
A. 純度高的節點需要更多的資訊去區分
B. 資訊增益可以用”1位元-熵”獲得
C. 如果選擇一個屬性具有許多歸類值, 那麼這個資訊增益是有偏差的
A. 1
B. 2
C.2和3
D. 所有以上
答案: C
詳細研究, 請戳下面連結:
Q10:如果SVM模型欠擬合, 以下方法哪些可以改進模型 :
A. 增大懲罰引數C的值
B. 減小懲罰引數C的值
C. 減小核係數(gamma引數)
答案: A
如果SVM模型欠擬合, 我們可以調高參數C的值, 使得模型複雜度上升.
LibSVM中,SVM的目標函式是:
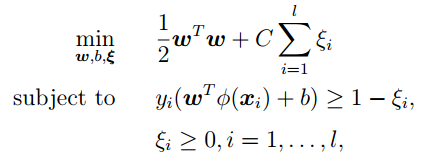
而, gamma引數是你選擇徑向基函式作為kernel後,該函式自帶的一個引數.隱含地決定了資料對映到新的特徵空間後的分佈.
gamma引數與C引數無關. gamma引數越高, 模型越複雜.
Q11:下圖是同一個SVM模型, 但是使用了不同的徑向基核函式的gamma引數, 依次是g1, g2, g3 , 下面大小比較正確的是 :
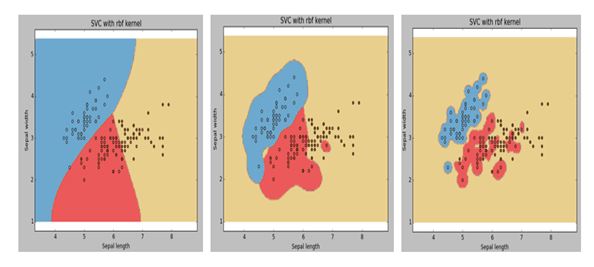
A. g1 > g2 > g3
B. g1 = g2 = g3
C. g1 < g2 < g3
D. g1 >= g2 >= g3
E. g1 <= g2 <= g3
答案: C
參考Q10題
Q12:假設我們要解決一個二類分類問題, 我們已經建立好了模型, 輸出是0或1, 初始時設閾值為0.5, 超過0.5概率估計, 就判別為1, 否則就判別為0 ; 如果我們現在用另一個大於0.5的閾值, 那麼現在關於模型說法, 正確的是 :
A. 模型分類的召回率會降低或不變
B. 模型分類的召回率會升高
C. 模型分類準確率會升高或不變
D. 模型分類準確率會降低
A. 1
B. 2
C.1和3
D. 2和4
E. 以上都不是
答案: C
這篇文章講述了閾值對準確率和召回率影響 :
Q13:”點選率問題”是這樣一個預測問題, 99%的人是不會點選的, 而1%的人是會點選進去的, 所以這是一個非常不平衡的資料集. 假設, 現在我們已經建了一個模型來分類, 而且有了99%的預測準確率, 我們可以下的結論是 :
A. 模型預測準確率已經很高了, 我們不需要做什麼了
B. 模型預測準確率不高, 我們需要做點什麼改進模型
C. 無法下結論
D. 以上都不對
答案: B
99%的預測準確率可能說明, 你預測的沒有點進去的人很準確 (因為有99%的人是不會點進去的, 這很好預測). 不能說明你的模型對點進去的人預測準確, 所以, 對於這樣的非平衡資料集, 我們要把注意力放在小部分的資料上, 即那些點選進去的人.
詳細可以參考這篇文章: article
Q14:使用k=1的knn演算法, 下圖二類分類問題, “+” 和 “o” 分別代表兩個類, 那麼, 用僅拿出一個測試樣本的交叉驗證方法, 交叉驗證的錯誤率是多少 :
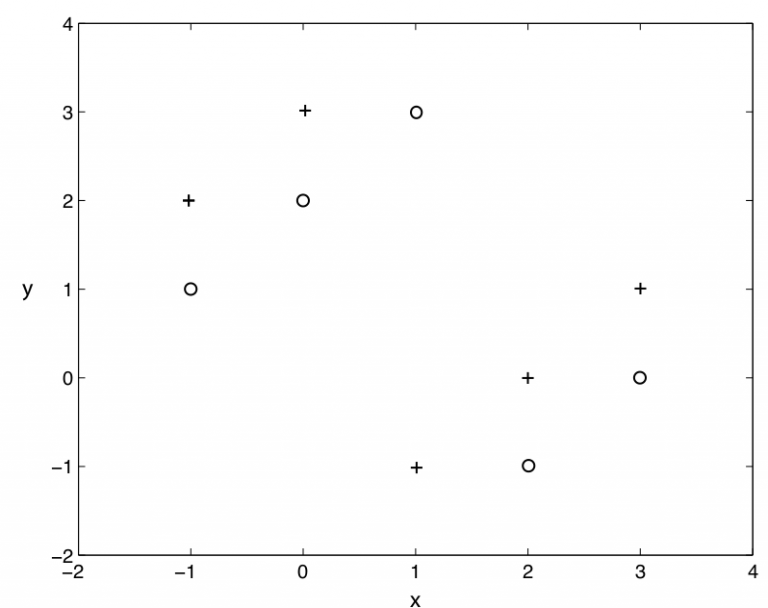
A. 0%
B. 100%
C. 0% 到 100%
D. 以上都不是
答案: B
knn演算法就是, 在樣本週圍看k個樣本, 其中大多數樣本的分類是A類, 我們就把這個樣本分成A類. 顯然, k=1 的knn在上圖不是一個好選擇, 分類的錯誤率始終是100%
Q15:我們想在大資料集上訓練決策樹, 為了使用較少時間, 我們可以 :
A. 增加樹的深度
B. 增加學習率 (learning rate)
C. 減少樹的深度
D. 減少樹的數量
答案: C
- 增加樹的深度, 會導致所有節點不斷分裂, 直到葉子節點是純的為止. 所以, 增加深度, 會延長訓練時間.
- 決策樹沒有學習率引數可以調. (不像整合學習和其它有步長的學習方法)
- 決策樹只有一棵樹, 不是隨機森林.
Q16:對於神經網路的說法, 下面正確的是 :
1. 增加神經網路層數, 可能會增加測試資料集的分類錯誤率
2. 減少神經網路層數, 總是能減小測試資料集的分類錯誤率
3. 增加神經網路層數, 總是能減小訓練資料集的分類錯誤率
A. 1
B. 1 和 3
C. 1 和 2
D. 2
答案: A
深度神經網路的成功, 已經證明, 增加神經網路層數, 可以增加模型範化能力, 即, 訓練資料集和測試資料集都表現得更好. 但是, 在這篇文獻中, 作者提到, 更多的層數, 也不一定能保證有更好的表現. 所以, 不能絕對地說層數多的好壞, 只能選A
Q17:假如我們使用非線性可分的SVM目標函式作為最優化物件, 我們怎麼保證模型線性可分 :
A. 設C=1
B. 設C=0
C. 設C=無窮大
D. 以上都不對
答案: C
C無窮大保證了所有的線性不可分都是可以忍受的.
Q18:訓練完SVM模型後, 不是支援向量的那些樣本我們可以丟掉, 也可以繼續分類:
A. 正確
B. 錯誤
答案: A
SVM模型中, 真正影響決策邊界的是支援向量
Q19:以下哪些演算法, 可以用神經網路去構造:
1. KNN
2. 線性迴歸
3. 對數機率迴歸
A. 1和 2
B. 2 和 3
C. 1, 2 和 3
D. 以上都不是
答案: B
1. KNN演算法不需要訓練引數, 而所有神經網路都需要訓練引數, 因此神經網路幫不上忙
2. 最簡單的神經網路, 感知器, 其實就是線性迴歸的訓練
3. 我們可以用一層的神經網路構造對數機率迴歸
Q20:請選擇下面可以應用隱馬爾科夫(HMM)模型的選項:
A. 基因序列資料集
B. 電影瀏覽資料集
C. 股票市場資料集
D. 所有以上
答案: D
只要是和時間序列問題有關的 , 都可以試試HMM
Q21:我們建立一個5000個特徵, 100萬資料的機器學習模型. 我們怎麼有效地應對這樣的大資料訓練 :
A. 我們隨機抽取一些樣本, 在這些少量樣本之上訓練
B. 我們可以試用線上機器學習演算法
C. 我們應用PCA演算法降維, 減少特徵數
D. B 和 C
E. A 和 B
F. 以上所有
答案: F
Q22:我們想要減少資料集中的特徵數, 即降維. 選擇以下適合的方案 :
1. 使用前向特徵選擇方法
2. 使用後向特徵排除方法
3. 我們先把所有特徵都使用, 去訓練一個模型, 得到測試集上的表現. 然後我們去掉一個特徵, 再去訓練, 用交叉驗證看看測試集上的表現. 如果表現比原來還要好, 我們可以去除這個特徵.
4. 檢視相關性表, 去除相關性最高的一些特徵
A. 1 和 2
B. 2, 3和4
C. 1, 2和4
D. All
答案: D
- 前向特徵選擇方法和後向特徵排除方法是我們特徵選擇的常用方法
- 如果前向特徵選擇方法和後向特徵排除方法在大資料上不適用, 可以用這裡第三種方法.
- 用相關性的度量去刪除多餘特徵, 也是一個好方法
所有D是正確的
Q23:對於 隨機森林和GradientBoosting Trees, 下面說法正確的是:
- 在隨機森林的單個樹中, 樹和樹之間是有依賴的, 而GradientBoosting Trees中的單個樹之間是沒有依賴的.
- 這兩個模型都使用隨機特徵子集, 來生成許多單個的樹.
- 我們可以並行地生成GradientBoosting Trees單個樹, 因為它們之間是沒有依賴的, GradientBoosting Trees訓練模型的表現總是比隨機森林好
A. 2
B. 1 and 2
C. 1, 3 and 4
D. 2 and 4
答案: A
- 隨機森林是基於bagging的, 而Gradient Boosting trees是基於boosting的, 所有說反了,在隨機森林的單個樹中, 樹和樹之間是沒有依賴的, 而GradientBoosting Trees中的單個樹之間是有依賴關係.
- 這兩個模型都使用隨機特徵子集, 來生成許多單個的樹.
所有A是正確的
Q24:對於PCA(主成分分析)轉化過的特徵 , 樸素貝葉斯的”不依賴假設”總是成立, 因為所有主要成分是正交的, 這個說法是 :
A. 正確的
B. 錯誤的
答案: B.
這個說法是錯誤的, 首先, “不依賴”和”不相關”是兩回事, 其次, 轉化過的特徵, 也可能是相關的.
Q25:對於PCA說法正確的是 :
1. 我們必須在使用PCA前規範化資料
2. 我們應該選擇使得模型有最大variance的主成分
3. 我們應該選擇使得模型有最小variance的主成分
4. 我們可以使用PCA在低維度上做資料視覺化
A. 1, 2 and 4
B. 2 and 4
C. 3 and 4
D. 1 and 3
E. 1, 3 and 4
答案: A
- PCA對資料尺度很敏感, 打個比方, 如果單位是從km變為cm, 這樣的資料尺度對PCA最後的結果可能很有影響(從不怎麼重要的成分變為很重要的成分).
- 我們總是應該選擇使得模型有最大variance的主成分
- 有時在低維度上左圖是需要PCA的降維幫助的
Q26:對於下圖, 最好的主成分選擇是多少 ? :
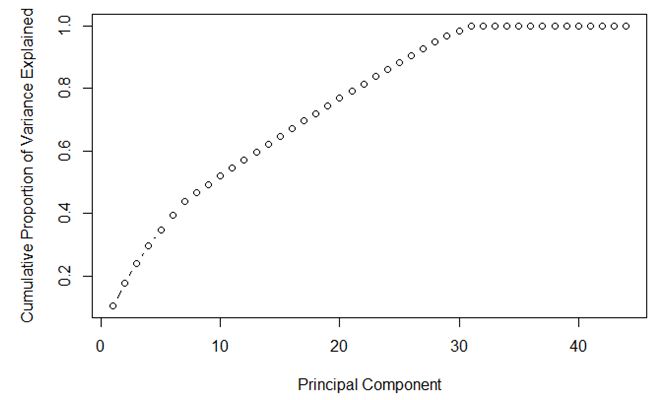
A. 7
B. 30
C. 35
D. Can’t Say
答案: B
- 主成分選擇使variance越大越好, 在這個前提下, 主成分越少越好。
Q27:資料科學家可能會同時使用多個演算法(模型)進行預測, 並且最後把這些演算法的結果整合起來進行最後的預測(整合學習),以下對整合學習說法正確的是 :
A. 單個模型之間有高相關性
B. 單個模型之間有低相關性
C. 在整合學習中使用“平均權重”而不是“投票”會比較好
D. 單個模型都是用的一個演算法
答案: B
Q28:在有監督學習中, 我們如何使用聚類方法? :
A. 我們可以先建立聚類類別, 然後在每個類別上用監督學習分別進行學習
B. 我們可以使用聚類“類別id”作為一個新的特徵項, 然後再用監督學習分別進行學習
C. 在進行監督學習之前, 我們不能新建聚類類別
D. 我們不可以使用聚類“類別id”作為一個新的特徵項, 然後再用監督學習分別進行學習
A. 2 和 4
B. 1 和 2
C. 3 和 4
D. 1 和 3
答案: B
我們可以為每個聚類構建不同的模型, 提高預測準確率。
“類別id”作為一個特徵項去訓練, 可以有效地總結了資料特徵。
所以B是正確的
Q29:以下說法正確的是 :
A. 一個機器學習模型,如果有較高準確率,總是說明這個分類器是好的
B. 如果增加模型複雜度, 那麼模型的測試錯誤率總是會降低
C. 如果增加模型複雜度, 那麼模型的訓練錯誤率總是會降低
D. 我們不可以使用聚類“類別id”作為一個新的特徵項, 然後再用監督學習分別進行學習
A. 1
B. 2
C. 3
D. 1 and 3
答案: C
考的是過擬合和欠擬合的問題。
Q30:對應GradientBoosting tree演算法, 以下說法正確的是 :
A. 當增加最小樣本分裂個數,我們可以抵制過擬合
B. 當增加最小樣本分裂個數,會導致過擬合
C. 當我們減少訓練單個學習器的樣本個數,我們可以降低variance
D. 當我們減少訓練單個學習器的樣本個數,我們可以降低bias
A. 2 和 4
B. 2 和 3
C. 1 和 3
D. 1 和 4
答案: C
- 最小樣本分裂個數是用來控制“過擬合”引數。太高的值會導致“欠擬合”,這個引數應該用交叉驗證來調節。
- 第二點是靠bias和variance概念的。
Q31:以下哪個圖是KNN演算法的訓練邊界 :
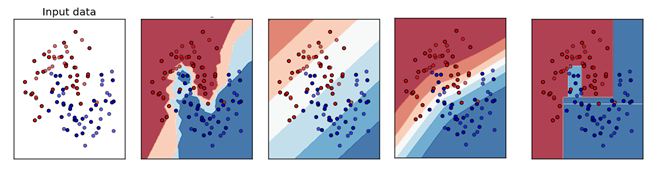
A) B
B) A
C) D
D) C
E) 都不是
答案: B
KNN演算法肯定不是線性的邊界, 所以直的邊界就不用考慮了。另外這個演算法是看周圍最近的k個樣本的分類用以確定分類,所以邊界一定是坑坑窪窪的。
Q32:如果一個訓練好的模型在測試集上有100%的準確率, 這是不是意味著在一個新的資料集上,也會有同樣好的表現? :
A. 是的,這說明這個模型的範化能力已經足以支援新的資料集合了
B. 不對,依然後其他因素模型沒有考慮到,比如噪音資料
答案: B
沒有一個模型是可以總是適應新資料的。我們不可能可到100%準確率。
Q33:下面的交叉驗證方法 :
i. 有放回的Bootstrap方法
ii. 留一個測試樣本的交叉驗證
iii. 5折交叉驗證
iv. 重複兩次的5折教程驗證
當樣本是1000時,下面執行時間的順序,正確的是:
A. i > ii > iii > iv
B. ii > iv > iii > i
C. iv > i > ii > iii
D. ii > iii > iv > i
答案: B
- Boostrap方法是傳統地隨機抽樣,驗證一次的驗證方法,只需要訓練1次模型,所以時間最少。
- 留一個測試樣本的交叉驗證,需要n次訓練過程(n是樣本個數),這裡,要訓練1000個模型。
- 5折交叉驗證需要訓練5個模型。
- 重複2次的5折交叉驗證,需要訓練10個模型。
所有B是正確的
Q34. Removed
Q35:變數選擇是用來選擇最好的判別器子集, 如果要考慮模型效率,我們應該做哪些變數選擇的考慮? :
1. 多個變數其實有相同的用處
2. 變數對於模型的解釋有多大作用
3. 特徵攜帶的資訊
4. 交叉驗證
A. 1 和 4
B. 1, 2 和 3
C. 1,3 和 4
D. 以上所有
答案: C
注意, 這題的題眼是考慮模型效率,所以不要考慮選項2.
Q36:對於線性迴歸模型,包括附加變數在內,以下的可能正確的是 :
1. R-Squared 和 Adjusted R-squared都是遞增的
2. R-Squared 是常量的,Adjusted R-squared是遞增的
3. R-Squared 是遞減的, Adjusted R-squared 也是遞減的
4. R-Squared 是遞減的, Adjusted R-squared是遞增的
A. 1 和 2
B. 1 和 3
C. 2 和 4
D. 以上都不是
答案: D
R-squared不能決定係數估計和預測偏差,這就是為什麼我們要估計殘差圖。但是,R-squared有R-squared 和 predicted R-squared 所沒有的問題。
每次你為模型加入預測器,R-squared遞增或不變.
Q37:對於下面三個模型的訓練情況, 下面說法正確的是 :
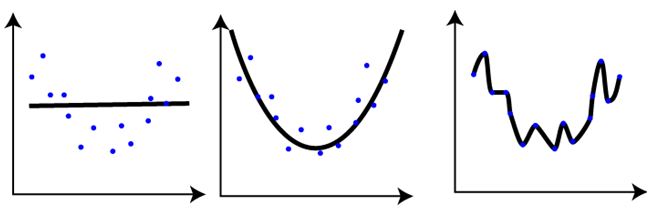
1. 第一張圖的訓練錯誤與其餘兩張圖相比,是最大的
2. 最後一張圖的訓練效果最好,因為訓練錯誤最小
3. 第二張圖比第一和第三張圖魯棒性更強,是三個裡面表現最好的模型
4. 第三張圖相對前兩張圖過擬合了
5. 三個圖表現一樣,因為我們還沒有測試資料集
A. 1 和 3
B. 1 和 3
C. 1, 3 和 4
D. 5
答案: C
Q38:對於線性迴歸,我們應該有以下哪些假設? :
1. 找到利群點很重要, 因為線性迴歸對利群點很敏感
2. 線性迴歸要求所有變數必須符合正態分佈
3. 線性迴歸假設資料沒有多重線性相關性
A. 1 和 2
B. 2 和 3
C. 1,2 和 3
D. 以上都不是
答案: D
- 利群點要著重考慮, 第一點是對的
- 不是必須的, 當然, 如果是正態分佈, 訓練效果會更好
- 有少量的多重線性相關性是可以的, 但是我們要儘量避免
Q39:當我們構造線性模型時, 我們注意變數間的相關性. 在相關矩陣中搜索相關係數時, 如果我們發現3對變數的相關係數是(Var1 和Var2, Var2和Var3, Var3和Var1)是-0.98, 0.45, 1.23 . 我們可以得出什麼結論:
1. Var1和Var2是非常相關的
2. 因為Var和Var2是非常相關的, 我們可以去除其中一個
3. Var3和Var1的1.23相關係數是不可能的
A. 1 and 3
B. 1 and 2
C. 1,2 and 3
D. 1
答案: C
- Var1和Var2相關係數是負的, 所以這是多重線性相關, 我們可以考慮去除其中一個.
- 一般地, 如果相關係數大於0.7或者小於-0.7, 是高相關的
- 相關性係數範圍應該是 [-1,1]
Q40:如果在一個高度非線性並且複雜的一些變數中, 一個樹模型可能比一般的迴歸模型效果更好. 只是:
A. 對的
B. 錯的
答案: A