
【mysql】mysql刪除重複記錄並且只保留一條
阿新 • • 發佈:2019-01-09
最近在做題庫系統,由於在題庫中添加了重複的試題,所以需要查詢出重複的試題,並且刪除掉重複的試題只保留其中1條,以保證考試的時候抽不到重複的題。
首先寫了一個小的例子:
單個欄位的操作
這是資料庫中的表:
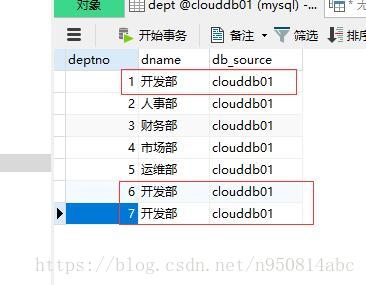
分組:

Select 重複欄位 From 表 Group By 重複欄位 Having Count(*)>1檢視是否有重複的資料:
GROUP BY <列名序列>
HAVING <組條件表示式>
查詢出:根據dname分組,同時滿足having字句中組條件表示式(重複次數大於1)的那些組
count(*)與count(1)其實沒有什麼差別,用哪個都可以
查詢全部重複的資料:

Select * From 表 Where 重複欄位 In (Select 重複欄位 From 表 Group By 重複欄位 Having Count(*)>1)
刪除全部重複試題:
將上面的查詢select改為delete(這樣會出錯的)
DELETE
FROM
dept
WHERE
dname IN (
SELECT
dname
FROM
dept
GROUP BY
dname
HAVING
count(1) > 1
)會出現如下錯誤:[Err] 1093 - You can't specify target table 'dept' for update in FROM clause
原因是:更新這個表的同時又查詢了這個表,查詢這個表的同時又去更新了這個表,可以理解為死鎖。mysql不支援這種更新查詢同一張表的操作
解決辦法:把要更新的幾列資料查詢出來做為一個第三方表,然後篩選更新。

查詢表中多餘重複試題(根據depno來判斷,除了rowid最小的一個)
第一種方法:
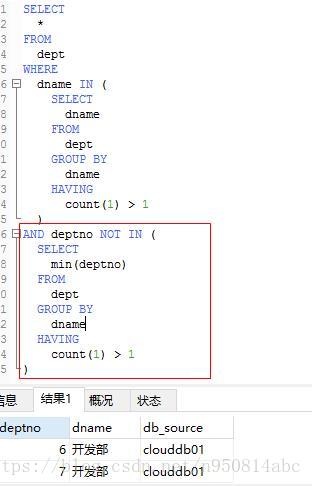
SELECT * FROM dept WHERE dname IN ( SELECT dname FROM dept GROUP BY dname HAVING COUNT(1) > 1 ) AND deptno NOT IN ( SELECT MIN(deptno) FROM dept GROUP BY dname HAVING COUNT(1) > 1 )
上面這種寫法正確,但是查詢的速度太慢,可以試一下下面這種方法:
第二種方法:
☆根據dname分組,查找出deptno最小的。然後再查詢deptno不包含剛才查出來的。這樣就查詢出了所有的重複資料(除了deptno最小的那行)
SELECT *
FROM
dept
WHERE
deptno NOT IN (
SELECT
dt.minno
FROM
(
SELECT
MIN(deptno) AS minno
FROM
dept
GROUP BY
dname
) dt
)刪除表中多餘重複試題並且只留1條:
第一種方法:
DELETE
FROM
dept
WHERE
dname IN (
SELECT
t.dname
FROM
(
SELECT
dname
FROM
dept
GROUP BY
dname
HAVING
count(1) > 1
) t
)
AND deptno NOT IN (
SELECT
dt.mindeptno
FROM
(
SELECT
min(deptno) AS mindeptno
FROM
dept
GROUP BY
dname
HAVING
count(1) > 1
) dt
)☆第二種方法(與上面查詢的第二種方法對應,只是將select改為delete):
DELETE
FROM
dept
WHERE
deptno NOT IN (
SELECT
dt.minno
FROM
(
SELECT
MIN(deptno) AS minno
FROM
dept
GROUP BY
dname
) dt
)多個欄位的操作:
單個欄位的如果會了,多個欄位也非常簡單。
DELETE
FROM
dept
WHERE
(dname, db_source) IN (
SELECT
t.dname,
t.db_source
FROM
(
SELECT
dname,
db_source
FROM
dept
GROUP BY
dname,
db_source
HAVING
count(1) > 1
) t
)
AND deptno NOT IN (
SELECT
dt.mindeptno
FROM
(
SELECT
min(deptno) AS mindeptno
FROM
dept
GROUP BY
dname,
db_source
HAVING
count(1) > 1
) dt
)總結:
其實上面的方法還有很多需要優化的地方,如果資料量太大的話,執行起來很慢,可以考慮加優化一下:
- 在經常查詢的欄位上加上索引
- 將*改為你需要查詢出來的欄位,不要全部查詢出來
- 小表驅動大表用IN,大表驅動小表用EXISTS。IN適合的情況是外表資料量小的情況,而不是外表資料大的情況,因為IN會遍歷外表的全部資料,假設a表100條,b表10000條那麼遍歷次數就是100*10000次,而exists則是執行100次去判斷a表中的資料是否在b表中存在,它只執行了a.length次數。至於哪一個效率高是要看情況的,因為in是在記憶體中比較的,而exists則是進行資料庫查詢操作的