
推薦系統的演算法
推薦系統的分類:
基於應用領域分類:電子商務推薦,社交好友推薦,搜尋引擎推薦,資訊內容推薦
基於設計思想:基於協同過濾的推薦,基於內容的推薦,基於知識的推薦,混合推薦
基於使用何種資料:基於使用者行為資料的推薦,基於使用者標籤的推薦,基於社交網路資料,基於上下文資訊(時間上下文,地點上下文等等)
協同過濾:
協同過濾的基本思想(基於使用者):
協同過濾一般是在海量的使用者中發掘出一小部分和你品味比較類似的,在協同過濾中,這些使用者成為鄰居,然後根據他們喜歡的其他東西組織成為一個排序的目錄作為推薦給你
核心問題:
如何確定一個使用者是不是和你有相似的品味?
如何將鄰居們的喜好組織成一個排序的目錄?
實現協同過濾的步驟:
收集使用者偏好
找到相似的使用者或物品
計算推薦(基於使用者,基於物品)
收集使用者偏好的方法:

通過收集使用者把使用者的特徵變成向量(一般變成向量前需要降噪(拋去或者修改),歸一化)
相似度:
當已經對使用者行為迚行分析得到使用者喜好後,我們可以根據使用者喜好計算相似使用者和物品,然後基於相似使用者戒者物品迚行推薦,這就是最典型的CF 的兩個分支:基於使用者的CF 和基於物品的CF。這兩種方法都需要計算相似度
把資料看成空間中的向量(降噪,歸一化)
距離的計算:
歐幾里得距離
其它距離
基於距離計算相似度:

基於相關係數計算相似度:
皮爾遜相關係數:

基於夾角餘弦計算相似度:

基於Tanimoto係數計算相似度:

同現相似度:

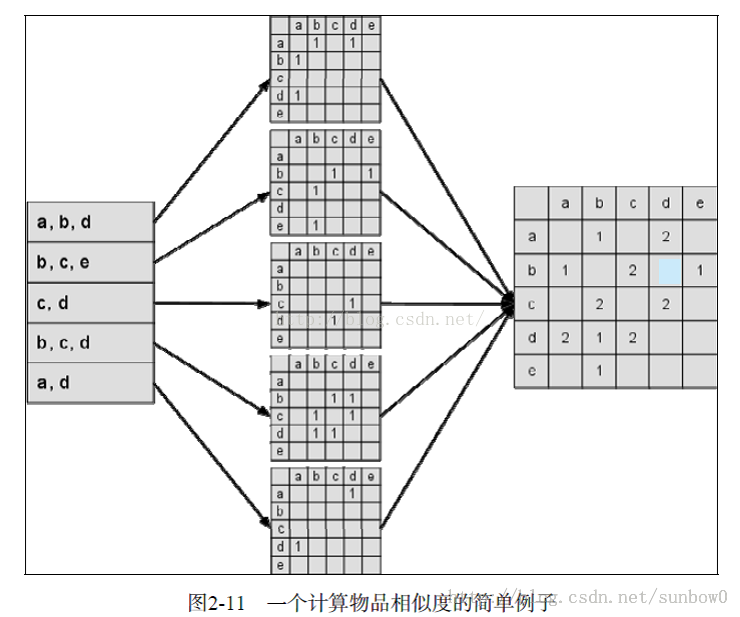
同現相似度模型:根據使用者評分資料表,生成物品的相似矩陣;
鄰居(使用者,物品)的圈定:
固定數量的鄰居:K-neighborhoods
基於相似度門檻的鄰居:Threshold-based neighborhoods

前面小節:前面講解了相似度怎麼計算,我們通過調查、收集資料得到使用者的一些偏好,然後組成了使用者的特徵向量,然後我們在用數學上的
距離或者相關係數等作為指標可以算出兩個特徵向量之間的相似度,有了使用者的相似度以後,我們可以通過k近鄰法或者鄰居法來求出相應特徵點的鄰居‘
這個時候可以有兩大流派的走向:如果特徵向量代表的是使用者,那就是說我首先在使用者之間計算使用者的相似度,然後找出與該使用者
相似口味的一些使用者出來,然後看看那些使用者買過一些什麼東西,然後看看他買過的但是該使用者沒有買過,就把這些東西推薦給該使用者,這個叫做基於
使用者的協同過濾演算法;如果特徵代表的是物品,當用戶面對一個商品的時候,我們會把與該商品相似的商品推薦給該使用者;
基於使用者的協同過濾演算法UserCF
基於使用者的協同過濾,通過不同使用者對物品的評分來評測使用者之間的相似性,基於使用者不間的相似性做出推薦。
簡單來講就是:給使用者推薦和他興趣相似的其他使用者喜歡的物品。

基於UserCF的基本思想相當簡單,基於使用者對物品的偏好找到相鄰鄰居使用者,然後將鄰居使用者喜歡的推薦給當前使用者。
計算上,就是將一個使用者對所有物品的偏好作為一個向量來計算使用者之間的相似度,找到K 鄰居後,根據鄰居的相似度權重以及他們對物品的偏好,預測當前使用者沒有偏好的未涉及物品,計算得到一個排序的物品列表作為推薦。
上圖給出了一個例子,對於使用者A,根據使用者的歷史偏好,這裡只計算得到一個鄰居–使用者C,然後將使用者C 喜歡的物品D 推薦給使用者A。

基於物品的協同過濾演算法ItemCF
基於item的協同過濾,通過使用者對不同item的評分來評測item之間的相似性,基於item之間的相似性做出推薦。
簡單來講就是:給使用者推薦和他之前喜歡的物品相似的物品。

基於物品的協同過濾演算法ItemCF
基於ItemCF的原理和基於UserCF類似,只是在計算鄰居時採用物品本身,而不是從使用者的角度,即基於使用者對物品的偏好找到相似的物品,然後根據使用者的歷史偏好,推薦相似的物品給他。
從計算的角度看,就是將所有使用者對某個物品的偏好作為一個向量來計算物品之間的相似度,得到物品的相似物品後,根據使用者歷史的偏好預測當前使用者還沒有表示偏好的物品,計算得到一個排序的物品列表作為推薦。
上圖給出了一個例子,對於物品A,根據所有使用者的歷史偏好,喜歡物品A 的使用者都喜歡物品C,得出物品A 和物品C 比較相似,而使用者C 喜歡物品A,那麼可以推斷出使用者C 可能也喜歡物品C。

User CF vs. Item CF
對於電子商務,使用者數量一般大大超過商品數量,此時Item CF的計算複雜度較低
在非社交網路的網站中,內容內在的聯絡是很重要的推薦原則,它比基於相似使用者的推薦原則更加有效。比如在購書網站上,當你看一本書的時候,推薦引擎會給你推薦相關的書籍,這個推薦的重要性進進超過了網站首頁對該使用者的綜合推薦。可以看到,在這種情況下,Item CF 的推薦成為了引導使用者瀏覽的重要手段。基於物品的協同過濾演算法,是目前電子商務採用最廣泛的推薦演算法。
在社交網路站點中,User CF 是一個更丌錯的選擇,User CF 加上社會網路資訊,可以增加使用者對推薦解釋的信服程度。
推薦多樣性和精度,各有千秋
使用者對推薦演算法的適應度

基於物品的協同過濾演算法實現
分為2個步驟
1. 計算物品之間的相似度
2. 根據物品的相似度和使用者的歷史行為給使用者生成推薦列表
算例:
網際網路某電影點評網站,主要產品包括電影介紹,電影排行,網友對電影打分,網友影評,影訊&購票,使用者在看|想看|看過的電影,猜你喜歡(推薦)。
使用者在完成註冊後,可以瀏覽網站的各種電影介紹,看電影排行榜,選擇自己喜歡的分類,找到自己想看的電影,並設定為“想看”,同時對自己已經看過的電影寫下影評,並打分。
需求分析:案例介紹
通過簡短的描述,我們可以粗略地看出,這個網站提供個性化推薦電影服務:
核心點:
網站提供所有電影資訊,吸引使用者瀏覽
網站收集使用者行為,包括瀏覽行為,評分行為,評論行為,從而推測出使用者的愛好。
網站幫助使用者找到,使用者還沒有看過,並滿足他興趣的電影列表。
網站通過海量資料的積累了,預測未來新片的市場影響和票房
電影推薦將成為這個網站的核心功能。
考慮因素:
在真實的環境中設計推薦的時候,要全面考量資料量,演算法效能,結果準確度等的指標。
推薦演算法選型:基於物品的協同過濾演算法ItemCF,並行實現
資料量:是否需要基於大資料架構,支援GB,TB,PB級資料量
演算法檢驗:可以通過準確率,召回率,覆蓋率,流行度等指標評判。
結果解讀:通過ItemCF的定義,合理給出結果解釋
測試資料集:
Mahout In Action書裡,第一章第六節基於物品的協同過濾演算法迚行實現。
測試資料集:small.csv
每行3個欄位,依次是使用者ID,電影ID,使用者對電影的評分(0-5分,每0.5分為一個評分點!)

步驟:
1. 建立物品的同現矩陣
2. 建立使用者對物品的評分矩陣
3. 矩陣計算推薦結果
步驟1:建立物品的同現矩陣
按使用者分組,找到每個使用者所選的物品,單獨出現計數及兩兩一組計數

步驟2:建立使用者對物品的評分矩陣
按使用者分組,找到每個使用者所選的物品及評分

步驟3:矩陣計算推薦結果
同現矩陣*評分矩陣=推薦結果

演算法評估:


演算法評估:
被檢索到的越多越好,這是追求“查全率”,即A/(A+B),越大越好。被檢索到的,越相關的越多越好,不相關的越少越好,這是追求“查準率”,即A/(A+C),越大越好。
在大規模資料集合中,這兩個指標是相互制約的。當希望索引出更多的資料的時候,查準率就會下降,當希望索引更準確的時候,會索引更少的資料。
Slope One演算法:
Mahout 提供的輕量級CF 推薦策略,是Daniel Lemire和Anna Maclachlan在2005 年提出的一種對基於評分的協同過濾推薦引擎的改迚方法SlopeOne是一種簡單高效的協同過濾演算法。通過均差計算迚行評分。
Slope One 的核心優勢是在大規模的資料上,它依然能保證良好的計算速度和推薦效果。
這個演算法在mahout-0.8版本中,已經被@Deprecated。
演算法思想:Slope One 推薦的基本原理,它將使用者的評分乊間的關係看作簡單的線性關係:Y = mX+ b; 當m = 1 時就是Slope One。
