
推薦系統FM & FFM演算法解讀與實踐
在推薦系統和計算廣告業務中,點選率CTR(click-through rate)和轉化率CVR(conversion rate)是衡量流量轉化的兩個關鍵指標。準確的估計CTR、CVR對於提高流量的價值,增加廣告及電商收入有重要的指導作用。業界常用的方法有人工特徵工程 + LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree) + LR、FM模型。在這些模型中,FM近年來表現突出,分別在由Criteo和Avazu舉辦的CTR預測競賽中奪得冠軍。
因子分解機(Factorization Machine, FM)是由Steffen Rendle提出的一種基於矩陣分解的機器學習演算法,其主要用於解決資料稀疏的業務場景(如推薦業務),特徵怎樣組合的問題。
paper指出FM與SVM相比,有如下優勢:
- FM可以實現非常稀疏資料引數估計,而SVM會效果很差,因為訓出的SVM模型會面臨較高的bias;
- FMs擁有線性的複雜度, 可以通過 primal 來優化而不依賴於像SVM的支援向量機;
一、FM原理
1. 為什麼進行特徵組合?
在feed流推薦場景中,根據user和item基礎資訊(clicked:是否點選;userId:使用者ID;userGender:使用者性別;itemTag:物品類別),來預測使用者是否對物品感興趣(點選與否,二分類問題)。源資料如下:
|
clicked |
userId | userGender | itemTag |
| 1 | 1 | 男 | 籃球 |
| 0 | 1 | 男 | 化妝品 |
| 0 | 2 | 女 | 籃球 |
| 1 | 2 | 女 | 化妝品 |
由於userGender和itemTag特徵都是categorical型別的,需要經過獨熱編碼(One-Hot Encoding)轉換成數值型特徵。
| clicked | userId | userGender_男 | userGender_女 | itemTag_籃球 | itemTag_化妝品 |
| 1 | 1 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 | 1 |
| 0 | 2 | 0 | 1 | 1 | 0 |
| 1 | 2 | 0 | 1 | 0 | 1 |
經過One-Hot編碼之後,大部分樣本資料特徵是比較稀疏的。上面的樣例中,每個樣本有5維特徵,但平均僅有3維特徵具有非零值。實際上,這種情況並不是此例獨有的,在真實應用場景中這種情況普遍存在。例如,CTR/CVR預測時,使用者的性別、職業、教育水平、品類偏好,商品的品類等,經過One-Hot編碼轉換後都會導致樣本資料的稀疏性。特別是商品品類這種型別的特徵,如商品的三級品類約有1000個,採用One-Hot編碼生成1000個數值特徵,但每個樣本的這1000個特徵,有且僅有一個是有效的(非零)。由此可見,資料稀疏性是實際問題中不可避免的挑戰。
One-Hot編碼的另一個特點就是導致特徵空間大。例如,商品三級類目有1000維特徵,一個categorical特徵轉換為1000維數值特徵,特徵空間劇增。
同時通過觀察大量的樣本資料可以發現,某些特徵經過關聯之後,與label之間的相關性就會提高。例如,“男性”與“籃球”、“女性”與“化妝品”這樣的關聯特徵,對使用者的點選有著正向的影響。換句話說:男性使用者很可能會在籃球有大量的瀏覽行為;而在化妝品卻不會有。這種關聯特徵與label的正向相關性在實際問題中是普遍存在的。因此,引入兩個特徵的組合是非常有意義的。
2. 如何組合特徵?
多項式模型是包含特徵組合的最直觀的模型。在多項式模型中,特徵和
的組合採用
表示,即
和
都非零時,組合特徵
才有意義。從對比的角度,本文只討論二階多項式模型。模型的表示式如下:
其中, 代表樣本的特徵數量,
是第
個特徵的值,
是模型引數。
從公式來看,模型前半部分就是普通的LR線性組合,後半部分的交叉項即特徵的組合。單從模型表達能力上來看,FM的表達能力是強於LR的,至少不會比LR弱,當交叉項引數全為0時退化為普通的LR模型。
從上面公式可以看出,組合特徵的引數一共有個,任意兩個引數都是獨立的。然而,在資料稀疏性普遍存在的實際應用場景中,二次項引數的訓練是很困難的。其原因是:每個引數
的訓練需要大量
和
都非零的樣本;由於樣本資料本來就比較稀疏,滿足
和
都非零的樣本將會非常少。訓練樣本的不足,很容易導致引數
不準確,最終將嚴重影響模型的效能。
3. 如何解決二次項引數的訓練問題呢?
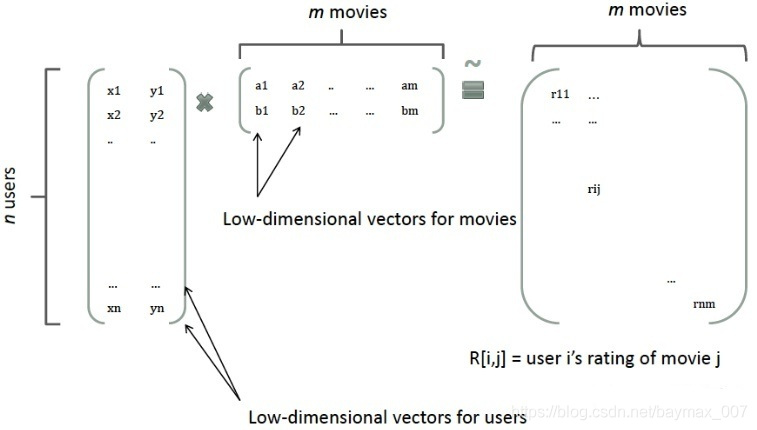
矩陣分解提供了一種解決思路。在model-based的協同過濾中,一個rating矩陣可以分解為user矩陣和item矩陣,每個user和item都可以採用一個隱向量表示。比如在下圖中的例子中,我們把每個user表示成一個二維向量,同時把每個item表示成一個二維向量,兩個向量的點積就是矩陣中user對item的打分。
任意的實對稱矩陣都有
個線性無關的特徵向量。並且這些特徵向量都可以正交單位化而得到一組正交且模為1的向量。故實對稱矩陣
可被分解成:
類似地,所有二次項引數可以組成一個對稱陣
(為了方便說明FM的由來,對角元素可以設定為正實數),那麼這個矩陣就可以分解為
,
的第
列(
)便是第
維特徵(
)的隱向量。換句話說,特徵分量
和
的交叉項係數就等於
對應的隱向量與
對應的隱向量的內積,即每個引數
,這就是FM模型的核心思想。
為了求出,我們需要求出特徵分量
的輔助向量
,
的輔助向量
,
表示隱向量長度(實際應用中
),轉換過程如下圖所示:
矩陣對角線上面的元素即為交叉項的引數。
FM的模型方程為(本文不討論FM的高階形式):
其中, 是第
維特徵的隱向量,
代表向量點積。隱向量的長度為
,包含
個描述特徵的因子。根據公式,二次項的引數數量減少為
個,遠少於多項式模型的引數數量。所有包含
的非零組合特徵(存在某個
,使得
)的樣本都可以用來學習隱向量
,這很大程度上避免了資料稀疏性造成的影響。
顯而易見,上述是一個通用的擬合方程,可以採用不同的損失函式用於解決迴歸、二元分類等問題,比如可以採用MSE(Mean Square Error)損失函式來求解迴歸問題,也可以採用Hinge/Cross-Entropy 損失來求解分類問題。當然,在進行二元分類時,FM的輸出需要經過sigmoid變換,這與Logistic迴歸是一樣的。直觀上看,FM的複雜度是 。但是,通過公式(3)的等式,FM的二次項可以化簡,其複雜度可以優化到
。由此可見,FM可以線上性時間對新樣本作出預測。
採用隨機梯度下降法SGD求解引數
由上式可知,的訓練只需要樣本
的特徵非0即可,適合於稀疏資料。
在使用SGD訓練模型時,在每次迭代中,只需計算一次所有 的
,就能夠方便得到所有
的梯度,上述偏導結果求和公式中沒有
,即與
無關,只與
有關,顯然計算所有
的
的複雜度是
,模型引數一共有
個。因此,FM引數訓練的複雜度也是
。綜上可知,FM可以線上性時間訓練和預測,是一種非常高效的模型。
二、FFM原理
1. 特徵組合為什麼引入field?
同樣以feed流推薦場景為例,我們多引入user維度使用者年齡資訊,其中性別和年齡同屬於user維度特徵,而tag屬於item維度特徵。在FM原理講解中,“男性”與“籃球”、“男性”與“年齡”所起潛在作用是預設一樣的,但實際上不一定。FM演算法無法捕捉這個差異,因為它不區分更廣泛類別field的概念,而會使用相同引數的點積來計算。
在FFM(Field-aware Factorization Machines )中每一維特徵(feature)都歸屬於一個特定和field,field和feature是一對多的關係。如下表所示:
| field | user field(U) | item field(I) | |||||
| clicked | userId | userGender_男 | userGender_女 | userAge_[20.30] | userAge_[30,40] | itemTag_籃球 | itemTag_化妝品 |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 0 | 2 | 0 | 1 | 0 | 1 | 1 | 0 |
| 1 | 2 | 0 | 1 | 0 | 1 | 0 | 1 |
FFM模型認為不僅跟
有關係,還跟與
相乘的
所屬的Field有關係,即
成了一個二維向量
,
是隱向量長度,
是Field的總個數。設樣本一共有
個特徵,
個field,那麼FFM的二次項有
個隱向量。而在FM模型中,每一維特徵的隱向量只有一個。FM可以看作FFM的特例,是把所有特徵都歸屬到一個field時的FFM模型。
其中,是第
的特徵所屬的欄位。如果隱向量的長度為
,那麼FFM的二次引數有
個,遠多於FM模型的
個。此外,由於隱向量與field相關,FFM二次項並不能夠化簡,時間複雜度是
。
需要注意的是由於FFM中的latent vector只需要學習特定的field,所以通常:
2. 如何組合特徵?
還是以feed流場景為例,說明FFM是如何組合特徵的。輸入記錄如下:
|
clicked |
userId | userGender(U) | userAge(U) | itemTag(I) |
| 1 | 1 | 男 | [20,30] | 籃球 |
FM模型交叉項為:
而FFM模型特徵交叉項為:
FFM在做latent vector的inner product的時候,必須考慮到其他特徵所屬的欄位。例如
中男性和年齡[20,30]均為user field,所以不區分field;
和
中男性、年齡[20,30]屬於user field,而籃球屬於item field,所以要考慮特徵的latent vector。
三、xlearn實現
實現FM & FFM的最流行的python庫有:LibFM、LibFFM、xlearn和tffm。其中,xLearn是一款高效能,易於使用且可擴充套件的機器學習軟體包,包括FM和FFM模型,可用於大規模解決機器學習問題。xlearn比libfm和libffm庫快得多,併為模型測試和調優提供了更好的功能。這裡以xlearn實現FM和FFM演算法。
1. FM實現
資料來自Kaggle預測泰坦尼克號的生存資料集,xlearn可以直接處理csv以及libsvm格式資料來實現FM演算法,但對於FFM必須是libsvm格式資料。
1.1 python程式碼
import xlearn as xl
# 訓練
fm_model = xl.create_fm() # 使用xlearn自帶的FM模型
fm_model.setTrain("./fm_train.txt") # 訓練資料
# 引數:
# 0. 二分類任務
# 1. learning rate: 0.2
# 2. lambda: 0.002
# 3. metric: accuracy
param = {'task':'binary', 'lr':0.2,
'lambda':0.002, 'metric':'acc'}
# 使用交叉驗證
fm_model.cv(param)1.2 執行
[ ACTION ] Start to train ... [ ACTION ] Cross-validation: 1/3: [------------] Epoch Train log_loss Test log_loss Test Accuarcy Time cost (sec) [ 10% ] 1 0.520567 0.519509 0.770270 0.00 [ 20% ] 2 0.462764 0.504741 0.787162 0.00 [ 30% ] 3 0.451524 0.499556 0.790541 0.00 [ 40% ] 4 0.446151 0.497348 0.787162 0.00 [ 50% ] 5 0.443402 0.494840 0.793919 0.00 [ 60% ] 6 0.440488 0.494532 0.793919 0.00 [ 70% ] 7 0.439055 0.493156 0.804054 0.00 [ 80% ] 8 0.438151 0.493404 0.800676 0.00 [ 90% ] 9 0.437012 0.492352 0.807432 0.00 [ 100% ] 10 0.436463 0.492059 0.804054 0.00 [ ACTION ] Cross-validation: 2/3: [------------] Epoch Train log_loss Test log_loss Test Accuarcy Time cost (sec) [ 10% ] 1 0.529570 0.491618 0.798658 0.00 [ 20% ] 2 0.474390 0.477966 0.788591 0.00 [ 30% ] 3 0.461248 0.470482 0.785235 0.00 [ 40% ] 4 0.456666 0.469640 0.788591 0.00 [ 50% ] 5 0.452902 0.468955 0.788591 0.00 [ 60% ] 6 0.450912 0.467620 0.785235 0.00 [ 70% ] 7 0.449447 0.467692 0.785235 0.00 [ 80% ] 8 0.447781 0.466430 0.781879 0.01 [ 90% ] 9 0.447122 0.466931 0.785235 0.00 [ 100% ] 10 0.446272 0.466597 0.788591 0.00 [ ACTION ] Cross-validation: 3/3: [------------] Epoch Train log_loss Test log_loss Test Accuarcy Time cost (sec) [ 10% ] 1 0.544947 0.470564 0.781145 0.00 [ 20% ] 2 0.491881 0.448169 0.794613 0.00 [ 30% ] 3 0.479801 0.442210 0.794613 0.00 [ 40% ] 4 0.475032 0.438578 0.804714 0.00 [ 50% ] 5 0.472111 0.436720 0.808081 0.00 [ 60% ] 6 0.470067 0.435224 0.811448 0.00 [ 70% ] 7 0.468599 0.434378 0.811448 0.00 [ 80% ] 8 0.466845 0.434049 0.811448 0.00 [ 90% ] 9 0.466121 0.433529 0.811448 0.00 [ 100% ] 10 0.465646 0.433083 0.814815 0.00 [------------] Average log_loss: 0.463913 [------------] Average Accuarcy: 0.802486 [ ACTION ] Finish Cross-Validation [ ACTION ] Clear the xLearn environment ... [------------] Total time cost: 0.04 (sec)
2. FFM實現
資料來自Criteo點選率預測挑戰賽中CTR資料集的一個微小(1%)抽樣,首先我們需要將其轉換為xLearn所需的libffm格式以擬合模型。
2.1 python程式碼
import xlearn as xl
# 訓練
ffm_model = xl.create_ffm() # 使用FFM模型
ffm_model.setTrain("./FFM_train.txt") # 訓練資料
ffm_model.setValidate("./FFM_test.txt") # 校驗測試資料
# param:
# 0. binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: accuracy
param = {'task':'binary', 'lr':0.2,
'lambda':0.002, 'metric':'acc'}
# 開始訓練
ffm_model.fit(param, './model.out')
# 預測
ffm_model.setTest("./FFM_test.txt") # 測試資料
ffm_model.setSigmoid() # 歸一化[0,1]之間
# 開始預測
ffm_model.predict("./model.out", "./output.txt")2.2 執行
[ ACTION ] Initialize model ... [------------] Model size: 5.56 MB [------------] Time cost for model initial: 0.01 (sec) [ ACTION ] Start to train ... [------------] Epoch Train log_loss Test log_loss Test Accuarcy Time cost (sec) [ 10% ] 1 0.600614 0.534322 0.770000 0.00 [ 20% ] 2 0.541555 0.536250 0.770000 0.00 [ 30% ] 3 0.521822 0.530098 0.770000 0.00 [ 40% ] 4 0.505286 0.537378 0.770000 0.00 [ 50% ] 5 0.492967 0.528159 0.770000 0.00 [ 60% ] 6 0.483819 0.533365 0.775000 0.00 [ 70% ] 7 0.472950 0.537750 0.770000 0.00 [ 80% ] 8 0.465698 0.531461 0.775000 0.00 [ 90% ] 9 0.457841 0.531676 0.770000 0.00 [ 100% ] 10 0.450092 0.531530 0.770000 0.00 [ ACTION ] Early-stopping at epoch 8, best Accuarcy: 0.775000 [ ACTION ] Start to save model ... [------------] Model file: ./model.out [------------] Time cost for saving model: 0.00 (sec) [ ACTION ] Finish training [ ACTION ] Clear the xLearn environment ... [------------] Total time cost: 0.05 (sec) ---------------------------------------------------------------------------------------------- _ | | __ _| | ___ __ _ _ __ _ __ \ \/ / | / _ \/ _` | '__| '_ \ > <| |___| __/ (_| | | | | | | /_/\_\_____/\___|\__,_|_| |_| |_|
xLearn -- 0.36 Version -- ----------------------------------------------------------------------------------------------
[------------] xLearn uses 4 threads for prediction task. [ ACTION ] Load model ... [------------] Load model from ./model.out [------------] Loss function: cross-entropy [------------] Score function: ffm [------------] Number of Feature: 9991 [------------] Number of K: 4 [------------] Number of field: 18 [------------] Time cost for loading model: 0.00 (sec) [ ACTION ] Read Problem ... [------------] First check if the text file has been already converted to binary format. [------------] Binary file (./FFM_test.txt.bin) found. Skip converting text to binary. [------------] Time cost for reading problem: 0.00 (sec) [ ACTION ] Start to predict ... [------------] The test loss is: 0.531461 [ ACTION ] Clear the xLearn environment ... [------------] Total time cost: 0.00 (sec)
參考資料