
JAVA集合原始碼解析 Hashtable探索(基於JDK1.8)
JDK1.8Hashtable探索
本文的討論分析是基於JDK1.8進行的
依舊是採用前幾篇文章的大綱來進行介紹
1.簡介
Hashtable 採用陣列+單鏈表來實現的,Hashtable 實現了一個雜湊表,它將鍵對映到值。任何非 null 物件可以用作鍵或值。為了成功儲存和檢索雜湊表中的物件,用作鍵的物件必須實現 hashCode 方法和 equals 方法。Hashtable 的方法被synchronized修飾,因此是同步的、執行緒安全的。
2.探索
2.1類關係
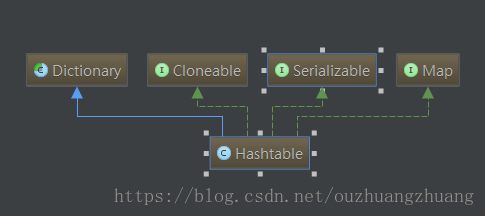
Hashtable 繼承了 Dictionary,能夠重寫裡面的鍵值對應的一些方法,但是官方已經廢棄它,推薦新的實現應該實現Map介面,而不是擴充套件這個類。
Hashtable 實現了 Map 介面,能夠實現其中的所有可選的Map操作;
Hashtable 實現了 Cloneable 介面,能夠使用 clone() 方法;
Hashtable 實現了 Serializable 介面,支援序列化操作。
2.2屬性
/**
* 散列表資料
*/
private transient Entry<?,?>[] table;
/**
* 散列表中的條目總數
*/
private transient int count;
/**
* 臨界值
* (這個欄位的值是(int)(capacity * loadFactor)。)
*
* @serial
*/
private int threshold;
/**
* 載入因子
*
* @serial table 乍一看是個Entry[ ] 陣列,其實也是個單向連結串列;
count 是記錄了整個table的大小;
threshold 臨界值或者閥值,是判斷是否需要擴容的重要依據,具體計算為 threshold = capacity * loadFactor;
loadFactor 為載入因子
modCount 記錄結構性變化,與fail-fast機制有關(後期專門寫一篇介紹)。
2.3構造方法
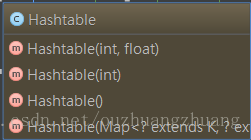
Hashtable 一共有 4 個構造方法。
/**
* 用指定的初始容量和指定的載入因子構造一個新的空的散列表。
*
* @param initialCapacity 散列表的初始容量。
* @param loadFactor 散列表的載入因子。
*/
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];//初始化table陣列
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);//初始化臨界值
}
/**
* 用指定的初始容量和預設載入因子(0.75)構造一個新的空雜湊表。
*
* @param initialCapacity the initial capacity of the hashtable.
*/
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
/**
* 使用預設的初始容量(11)和載入因子(0.75)構造一個新的空雜湊表。
*/
public Hashtable() {
this(11, 0.75f);
}
/**
* 使用與給定Map相同的對映構造一個新的散列表。
* 散列表的初始容量足以容納給定Map中的對映和預設載入因子(0.75)。
*
*/
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);//初始化hashtable
putAll(t);//將t集合放入hashtable中
}1)Hashtable() 預設初始容量為 11 ,載入因子為 0.75。
2)Hashtable(int initialCapacity) 用指定的初始容量和預設載入因子(0.75)構造一個新的空雜湊表。
3)Hashtable(Map<? extends K, ? extends V> t) 使用與給定Map相同的對映構造一個新的散列表。
4)以上 3 個構造方法其實最後都是呼叫了Hashtable(int initialCapacity, float loadFactor)構造方法。
5)Hashtable(int initialCapacity, float loadFactor) 在其中實現了 table 和 threshold 的初始化工作以及異常情況的判斷。
2.4核心方法
(1)putAll( )
/**
* 將指定對映中的所有映射覆制到此散列表。
* 這些對映將替換此散列表對當前指定對映中的任何鍵的任何對映。
*
*/
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())//遍歷t集合
put(e.getKey(), e.getValue());//呼叫put方法
}putAll() 中遍歷集合呼叫 put() 方法。
(2)put(K key, V value)
/**
* 將指定的鍵對映到此散列表中指定的值
* 鍵和值都不能是 null
* 通過使用與原始鍵相等的鍵呼叫 get 方法,可以檢索該值。
* 該方法是執行緒安全的,被synchronized修飾
*/
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;//初始化陣列
int hash = key.hashCode();//計算hash值
int index = (hash & 0x7FFFFFFF) % tab.length;//桶的位置索引
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {//如果桶中hash值相等且值相等
V old = entry.value;//獲取舊值
entry.value = value;//覆蓋舊值
return old;
}
}
addEntry(hash, key, value, index);//呼叫addEntry方法
return null;
}1) put(K key, V value) 方法中會先初始化 table 陣列,然後計算 key 對應的 hashcode() 以及 key 在桶中的位置索引 index。
2)如果放入的鍵值對都不為空,判斷是否桶中 hash 和 key 相等的位置是否有值,有的話覆蓋原值。
3)呼叫addEntry( ) 方法。
private void addEntry(int hash, K key, V value, int index) {
modCount++;//結構性加1
Entry<?,?> tab[] = table;
if (count >= threshold) {//如果散列表中條目數大於臨界值
// 如果超出臨界值,則擴容
rehash();
tab = table;//初始化新值
hash = key.hashCode();//計算key的hash值
index = (hash & 0x7FFFFFFF) % tab.length;//key的位置索引
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];//初始化新的連結串列
tab[index] = new Entry<>(hash, key, value, e);//儲存新連結串列到tab中
count++;//連結串列大小加1
}1)如果 table 大小 count 大於臨界值 threshold ,則進行擴容操作。
2)初始化新 tab 陣列,key 的hash值,key 的位置索引。
3)儲存新值到tab連結串列中,連結串列大小加1。
(3)rehash()擴容方法
/**
* 增加散列表的容量並在內部重新組織,以便更有效地容納和訪問條目。
* 當散列表中的鍵數超過散列表的容量和載入因子時,將自動呼叫此方法。
*/
@SuppressWarnings("unchecked")
protected void rehash() {
int oldCapacity = table.length;//儲存舊的table容量
Entry<?,?>[] oldMap = table;//儲存舊的陣列
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;//擴大容量為原來的2倍+1
if (newCapacity - MAX_ARRAY_SIZE > 0) {//如果容量大於最大陣列長度
if (oldCapacity == MAX_ARRAY_SIZE)//如果舊容量與最大陣列容量相等
// Keep running with MAX_ARRAY_SIZE buckets
return;//返回
newCapacity = MAX_ARRAY_SIZE;//重新賦值新的容量大小
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];//初始化新的連結串列
modCount++;//結構性加1
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);//計算新的臨界值
table = newMap;//儲存新的table
for (int i = oldCapacity ; i-- > 0 ;) {//倒序遍歷舊連結串列
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {//遍歷取出舊值
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;//產生新的hash位置
e.next = (Entry<K,V>)newMap[index];//同一表中,新結點連結到表頭
newMap[index] = e;//儲存新值
}
}
}1 ) 首先儲存舊的table容量和陣列
2 ) 擴大容量為原來的2倍+1,判斷是否需要重新賦值容量值
3 ) 計算新的臨界值,儲存table陣列,把舊陣列遍歷儲存到擴容後的陣列中
(4)get(Object key)
/**
* 返回指定鍵對映到的值,
* 或者如果此對映不包含金鑰的對映,則返回null。
*/
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;//賦值新陣列連結串列
int hash = key.hashCode();//計算hashcode
int index = (hash & 0x7FFFFFFF) % tab.length;//計算匹配的位置
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {//遍歷連結串列尋找
if ((e.hash == hash) && e.key.equals(key)) {//如果hash值相同且key相等
return (V)e.value;//返回
}
}
return null;
}1)先計算key的hashcode和key對應的索引位置。
2)遍歷陣列連結串列查詢hash值和key都匹配的值。
(5)remove(Object key)
/**
* 從該散列表中刪除鍵(及其相應的值)。
* 如果金鑰不在散列表中,此方法不執行任何操作。
*/
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;//獲取當前的table
int hash = key.hashCode();//計算要移除key的hashcode
int index = (hash & 0x7FFFFFFF) % tab.length;//計算位置
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];//儲存該值到e中
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {//遍歷連結串列
if ((e.hash == hash) && e.key.equals(key)) {//如果hash值且key相等
modCount++;//結構性加1
if (prev != null) {//如果不為空
prev.next = e.next;//下一個表頭替換該位置
} else {//如果為空
tab[index] = e.next;//下一個表頭賦值該位置
}
count--;//大小減1
V oldValue = e.value;//獲取舊值
e.value = null;//置空當前位置值
return oldValue;
}
}
return null;
}1)先獲取hashcode和key的位置值 。
2)先儲存垓值到e中 。
3)如果hash值和key都相等,表頭不為空時,下一個表頭替換該位置,表頭為空時,下一個表頭賦值該位置。
4)返回移除的值。
3.總結
- Hashtable 繼承的是 Dictionary,HashMap 繼承的是 AbstractMap,Dictionary 類是一個抽象類,用來儲存鍵/值對,作用和Map類相似。AbstractMap實現了大部分的Map介面。
- Hashtable 的 put() 方法中是允許鍵和值為 null ,HashMap 則不允許為空。
- Hashtable 比 HashMap 多了 enumerator 迭代器。
- Hashtable 的大部分 public 方法都被 synchronized 修飾,是執行緒安全的,HashMap 不是,如果一個執行緒安全的實現是不需要的,建議使用 HashMap 代替 Hashtable。如果執行緒安全高度併發的實現是需要的,那麼推薦使用java.util.concurrent.ConcurrentHashMap 或者 Collections.synchronizeMap 代替 Hashtable。