
【深度學習】簡單地利用keras做車標識別
阿新 • • 發佈:2019-01-09
一次簡簡單單的實驗課的內容而已。
首先把給出的樣本素材放縮的32*32的大小,這部分可以用Python的批處理和opencv中的放縮函式resize()來做,在此我就不列出程式碼了。
列舉出一部分放縮好的圖片。
然後在利用keras簡歷卷積神經網路的模型,在做此實驗之前,電腦要配置好Python+Theano+Keras的環境。
#生成一個model def __CNN__(testdata,testlabel,traindata,trainlabel): model = Sequential() #第一個卷積層,4個卷積核,每個卷積核大小5*5。1表示輸入的圖片的通道,灰度圖為1通道。 model.add(Convolution2D(20 , 5 , 5, border_mode='valid',input_shape=(1,32,32))) model.add(Activation('sigmoid')) model.add(MaxPooling2D(pool_size=(2, 2))) #第二個卷積層,30個卷積核,每個卷積核大小5*5。 #採用maxpooling,poolsize為(2,2) model.add(Convolution2D(30 , 5 , 5, border_mode='valid')) model.add(Activation('sigmoid')) model.add(MaxPooling2D(pool_size=(2, 2))) #第三個卷積層,16個卷積核,每個卷積核大小3*3 #啟用函式用tanh #採用maxpooling,poolsize為(2,2) #model.add(Convolution2D(16 , 3 , 3, border_mode='valid')) #model.add(Activation('tanh')) #model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(500, init='normal')) model.add(Activation('sigmoid')) #Softmax分類,輸出是4類別 model.add(Dense(4, init='normal')) model.add(Activation('softmax'))
CNN調整引數是一個很麻煩的事情,上面各個層的引數和層數是我參考LENET-5然後自己調試出來的。我本來我沒打算用keras做這個,是在caffe上做的,經過多次調整卷積核大小,模型層數,輸出神經元個數等等。最後在caffe上跑出來的結果是98%也還不錯。在keras上的效果更加理想。
Keras做卷積神經網路的另一個部分就是如何把圖片樣本變成合格的樣本供其訓練,具體說來就是分為兩個列XY,其中X列是一個四維陣列X(x1,x2,x3,x4).x1表示的是樣本的數目;x2,表示圖片的通道值,是RGB還是灰度圖;x3,x4表示圖片畫素點的矩陣,一般為統一大小(這就是前面為什麼要劃分成32*32的原因,開心的話劃分成64*64也行)。
Y列標記的就是和X列對應的圖片的標記。劃分的函式程式碼如下:
#統計樣本的數目 def __getnum__(path): fm=os.listdir(path) i=0 for f in fm: ff= os.listdir(path+f+'/') for n in ff: i+=1 return i #生成X,Y列 def __data_label__(path,count): data = np.empty((count,1,32,32),dtype="float32") label = np.empty((count,),dtype="uint8") i=0; filename= os.listdir(path) for ff in filename : fi=os.listdir(path+ff+'/') for f in fi: img = cv2.imread(path+ff+'/'+f,0) arr = np.asarray(img,dtype="float32") data[i,:,:,:] = arr label[i]=int(ff) i+=1 return data,label
程式碼寫好,各個引數調整好以後,在虛擬機器或者直接呼叫終端執行程式,便可以得到訓練的結果的啦。
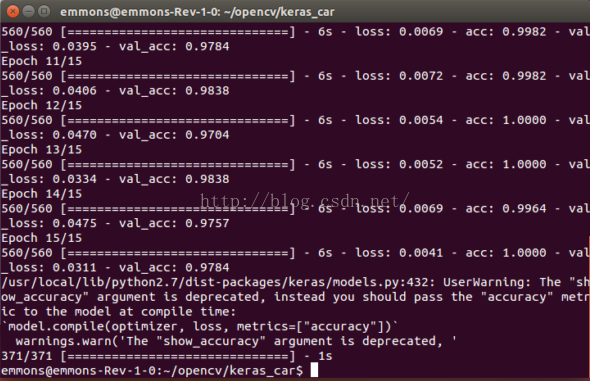
(依我看,就速度方面而言,keras遠勝於caffe。準確率也挺高的。我在cafe上調了無數的引數最後準確率也就98%最多了,然而相同的模型放在keras下就只錯幾個或者根本不錯。究其原因,我還不知道,還要繼續努力學習呀QAQ)
下面是這次實驗的原始碼:
# coding=utf-8
import cv2
import os
import numpy as np
#匯入各種用到的模組元件
#from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.advanced_activations import PReLU
from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras.optimizers import SGD, Adadelta, Adagrad
from keras.utils import np_utils, generic_utils
import numpy as np
from PIL import Image
from keras import backend as k
#統計樣本的數目
def __getnum__(path):
fm=os.listdir(path)
i=0
for f in fm:
ff= os.listdir(path+f+'/')
for n in ff:
i+=1
return i
#生成X,Y列
def __data_label__(path,count):
data = np.empty((count,1,32,32),dtype="float32")
label = np.empty((count,),dtype="uint8")
i=0;
filename= os.listdir(path)
for ff in filename :
fi=os.listdir(path+ff+'/')
for f in fi:
img = cv2.imread(path+ff+'/'+f,0)
arr = np.asarray(img,dtype="float32")
data[i,:,:,:] = arr
label[i]=int(ff)
i+=1
return data,label
###############
#開始建立CNN模型
###############
#生成一個model
def __CNN__(testdata,testlabel,traindata,trainlabel):
model = Sequential()
#第一個卷積層,4個卷積核,每個卷積核大小5*5。1表示輸入的圖片的通道,灰度圖為1通道。
model.add(Convolution2D(20 , 5 , 5, border_mode='valid',input_shape=(1,32,32)))
model.add(Activation('sigmoid'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#第二個卷積層,30個卷積核,每個卷積核大小5*5。
#採用maxpooling,poolsize為(2,2)
model.add(Convolution2D(30 , 5 , 5, border_mode='valid'))
model.add(Activation('sigmoid'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#第三個卷積層,16個卷積核,每個卷積核大小3*3
#啟用函式用tanh
#採用maxpooling,poolsize為(2,2)
#model.add(Convolution2D(16 , 3 , 3, border_mode='valid'))
#model.add(Activation('tanh'))
#model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(500, init='normal'))
model.add(Activation('sigmoid'))
#Softmax分類,輸出是4類別
model.add(Dense(4, init='normal'))
model.add(Activation('softmax'))
#############
#開始訓練模型
##############
#使用SGD + momentum衝量
sgd = SGD(lr=0.05, decay=1e-6, momentum=0.9, nesterov=True)
#model.compile裡的引數loss就是損失函式(目標函式)
model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=['accuracy'])
#開始訓練, show_accuracy在每次迭代後顯示正確率 。 batch_size是每次帶入訓練的樣本數目 , nb_epoch 是迭代次數, shuffle 是打亂樣本隨機。
model.fit(traindata, trainlabel, batch_size=16,nb_epoch=15,shuffle=True,verbose=1,show_accuracy=True,validation_data=(testdata, testlabel))
#設定測試評估引數,用測試集樣本
model.evaluate(testdata, testlabel, batch_size=16,verbose=1,show_accuracy=True)
############
#主模組
############
trainpath = '/home/emmons/carband_resize/train/'
testpath = '/home/emmons/carband_resize/test/'
testcount=__getnum__(testpath)
traincount=__getnum__(trainpath)
testdata,testlabel= __data_label__(testpath, testcount)
traindata,trainlabel= __data_label__(trainpath, traincount)
#label為0~3共4個類別,keras要求格式為binary class matrices,轉化一下,直接呼叫keras提供的這個函式
testlabel = np_utils.to_categorical(testlabel, 4)
trainlabel = np_utils.to_categorical(trainlabel, 4)
__CNN__(testdata, testlabel, traindata, trainlabel)