呼叫face++平臺api進行人臉識別
Face++介紹:
Face++平臺提供一整套世界領先的人臉檢測,人臉識別,面部分析的視覺技術服務。通過提供雲端API、離線SDK等供使用者進行開發,像支付寶人臉支付使用的技術就是Face++。(face++的介紹)
每個人在Face++的官網註冊賬號後可以申請新建API,填寫相關資訊後,隨後會分配API key和 API Secrect。我們可以選擇試用的服務,由於是免費的有的功能不支援。
分配的API key和 API Secrect,有了這兩個東西才能呼叫api。

官網提供了API文件和演示。
開啟api文件可以檢視詳細說明,很詳細不多說了。
實驗平臺:
我的測試程式是在Ubuntu下自帶的Python環境下編寫,用到了Python-OpenCV,所以要裝一下Python-OpenCV。
console下輸入:
sudo apt-get install python-opencv很快就會安裝完成,並且會自動配置好環境變數。
import cv包和cv2包看看,發現沒有報錯,安裝成功。
程式碼:
# -*- coding:utf-8 -*-
import cv2
import urllib2
import urllib
import time
#讀取原圖,並顯示
img = cv2.imread("football_players.jpeg")
cv2.namedWindow("原圖")
cv2.imshow("原圖", img)
#URL
http_url='https://api-cn.faceplusplus.com/facepp/v3/detect' 程式不復雜,按照程式思路簡單解釋下:
1、指定圖片的名稱,讀取圖片,並顯示。
#讀取原圖,並顯示
img = cv2.imread("football_players.jpeg")
cv2.namedWindow("原圖")
cv2.imshow("原圖", img)把圖片直接放在當前目錄下即可(圖片是巴薩的<( ̄︶ ̄)>)。
2、填一些呼叫api相關的資訊,根據需要自己改就行。
#URL
http_url='https://api-cn.faceplusplus.com/facepp/v3/detect'
#使用者資訊
key = "RU8VkInUd4zpcCo2GbKxPz90rPoaY5O0"
secret = "01YadiHNX_Fpqw6saBYa2POD6ozL6gWu"
#圖片儲存路徑
filepath = r"/home/xhb/Study/FaceRecognition/python-opencv-face++/football_players.jpeg"使用者資訊要填上自己在前面申請的API Key和API Secret。

要傳送圖片到face++的伺服器去進行識別,填上圖片所在的目錄的路徑:
當前目錄路徑+圖片名。
#圖片儲存路徑
filepath = r"/home/xhb/Study/FaceRecognition/python-opencv-face++/football_players.jpeg"
3、中間的程式其實就是把資訊封裝一下,建立網路連結,然後跟伺服器通訊。呼叫urlopen()訪問伺服器,返回resp,列印結果。
try:
#req.add_header('Referer','http://remotserver.com/')
#post data to server
resp = urllib2.urlopen(req, timeout=5)
#get response
qrcont=resp.read()
print qrcont #打印出得到的結果
except urllib2.HTTPError as e:
print e.read()4、resp是返回的資料。呼叫read()方法,轉換成qrcont,這是個字串,然後在終端打印出來。
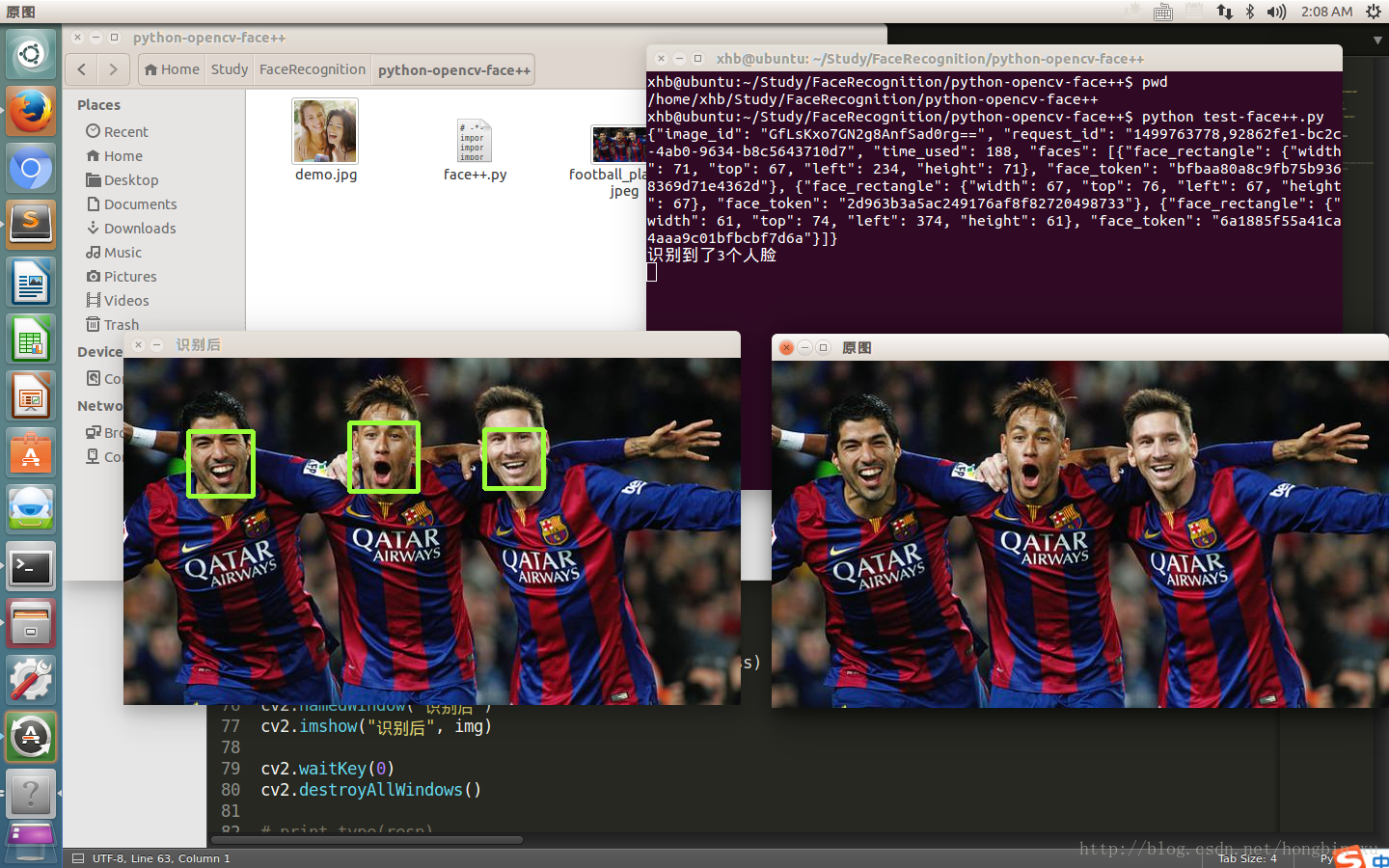
終端的全部列印資訊:
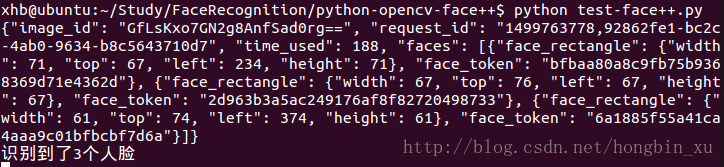
很明顯,返回的resp是一個字典,其中記錄了一些圖片的資訊,還有識別出的人臉的位置。
qrcont是一組字串,呼叫eval()函式將其轉換回字典型別,取出來再處理一下,在圖片上標識出人臉的位置。
#進過測試前面的程式會返回一個字典,其中指出了人臉所在的矩形的位置和大小等,所以直接進行標註
mydict = eval(qrcont)
faces = mydict["faces"]
faceNum = len(faces)
print("識別到了%d個人臉"%(faceNum))
for i in range(faceNum):
face_rectangle = faces[i]['face_rectangle']
width = face_rectangle['width']
top = face_rectangle['top']
left = face_rectangle['left']
height = face_rectangle['height']
start = (left, top)
end = (left+width, top+height)
color = (55,255,155)
thickness = 3
cv2.rectangle(img, start, end, color, thickness)