
《資料庫系統概論》知識點整理
第一節
一、相關概念
1. Data:資料,是資料庫中儲存的基本物件,是描述事物的符號記錄。
2. Database:資料庫,是長期儲存在計算機內、有組織的、可共享的大量資料的集合。
3. DBMS:資料庫管理系統,是位於使用者與作業系統之間的一層資料管理軟體,用於科學地組織、儲存和管理資料、高效地獲取和維護資料。
4. DBS:資料庫系統,指在計算機系統中引入資料庫後的系統,一般由資料庫、資料庫管理系統、應用系統、資料庫管理員(DBA)構成。
5. 資料模型:是用來抽象、表示和處理現實世界中的資料和資訊的工具,是對現實世界的模擬,是資料庫系統的核心和基礎;其組成元素有資料結構、資料操作和完整性約束。
6. 概念模型:也稱資訊模型,是按使用者的觀點來對資料和資訊建模,主要用於資料庫設計。
7. 邏輯模型:是按計算機系統的觀點對資料建模,用於DBMS實現。
8. 物理模型:是對資料最底層的抽象,描述資料在系統內部的表示方式和存取方法,在磁碟或磁帶上的儲存方式和存取方法,是面向計算機系統的。
9. 實體和屬性:客觀存在並可相互區別的事物稱為實體。實體所具有的某一特性稱為屬性。
10.E-R圖:即實體-關係圖,用於描述現實世界的事物及其相互關係,是資料庫概念模型設計的主要工具。
11.關係模式:從使用者觀點看,關係模式是由一組關係組成,每個關係的資料結構是一張規範化的二維表。
12.型/值:型是對某一類資料的結構和屬性的說明;值是型的一個具體賦值,是型的例項。
13.資料庫模式:是對資料庫中全體資料的邏輯結構(資料項的名字、型別、取值範圍等)和特徵(資料之間的聯絡以及資料有關的安全性、完整性要求)的描述。
14.資料庫的三級系統結構:外模式、模式和內模式。
15.資料庫內模式:又稱為儲存模式,是對資料庫物理結構和儲存方式的描述,是資料在資料庫內部的表示方式。一個數據庫只有一個內模式。
16.資料庫外模式:又稱為子模式或使用者模式,它是資料庫使用者能夠看見和使用的區域性資料的邏輯結構和特徵的描述,是資料庫使用者的資料檢視。通常是模式的子集。一個數據庫可有多個外模式。
17.資料庫的二級映像:外模式/模式映像、模式/內模式映像。
二、重點知識點
1. 資料庫系統由資料庫、資料庫管理系統、應用系統和資料庫管理員構成。
2. 資料模型的組成要素是:資料結構、資料操作、完整性約束條件。
3. 實體型之間的聯絡分為一對一、一對多和多對多三種類型。
4. 常見的資料模型包括:關係、層次、網狀、面向物件、物件關係對映等幾種。
5. 關係模型的完整性約束包括:實體完整性、參照完整性和使用者定義完整性。
6. 闡述資料庫三級模式、二級映象的含義及作用。
資料庫三級模式反映的是資料的三個抽象層次: 模式是對資料庫中全體資料的邏輯結構和特徵的描述。內模式又稱為儲存模式,是對資料庫物理結構和儲存方式的描述。外模式又稱為子模式或使用者模式,是對特定資料庫使用者相關的區域性資料的邏輯結構和特徵的描述。
資料庫三級模式通過二級映象在 DBMS 內部實現這三個抽象層次的聯絡和轉換。外模式面向應用程式, 通過外模式/模式映象與邏輯模式建立聯絡, 實現資料的邏輯獨立性。 模式/內模式映象建立模式與內模式之間的一對一對映, 實現資料的物理獨立性。
第二節
一、相關概念
1. 主鍵: 能夠唯一地標識一個元組的屬性或屬性組稱為關係的鍵或候選鍵。 若一個關係有多個候選鍵則可選其一作為主鍵(Primary key)。
2. 外來鍵:如果一個關係的一個或一組屬性引用(參照)了另一個關係的主鍵,則稱這個或這組屬性為外碼或外來鍵(Foreign key)。
3. 關係資料庫: 依照關係模型建立的資料庫稱為關係資料庫。 它是在某個應用領域的所有關係的集合。
4. 關係模式: 簡單地說,關係模式就是對關係的型的定義, 包括關係的屬性構成、各屬性的資料型別、 屬性間的依賴、 元組語義及完整性約束等。 關係是關係模式在某一時刻的狀態或內容, 關係模型是型, 關係是值, 關係模型是靜態的、 穩定的, 而關係是動態的、隨時間不斷變化的,因為關係操作在不斷地更新著資料庫中的資料。
5. . 實體完整性:用於標識實體的唯一性。它要求基本關係必須要有一個能夠標識元組唯一性的主鍵,主鍵不能為空,也不可取重複值。
6. 參照完整性 : 用於維護實體之間的引用關係。 它要求一個關係的外來鍵要麼為空, 要麼取與被參照關係對應的主鍵值,即外來鍵值必須是主鍵中已存在的值。
7. 使用者定義的完整性:就是針對某一具體應用的資料必須滿足的語義約束。包括非空、 唯一和布林條件約束三種情況。
二、重要知識點
1. 關係資料庫語言分為關係代數、關係演算和結構化查詢語言三大類。
2. 關係的 5 種基本操作是選擇、投影、並、差、笛卡爾積。
3.關係模式是對關係的描述,五元組形式化表示為:R(U,D,DOM,F),其中
R —— 關係名
U —— 組成該關係的屬性名集合
D —— 屬性組 U 中屬性所來自的域
DOM —— 屬性向域的映象集合
F —— 屬性間的資料依賴關係集合
4.笛卡爾乘積,選擇和投影運算如下

第三節
一、相關概念
1. SQL:結構化查詢語言的簡稱, 是關係資料庫的標準語言。SQL 是一種通用的、 功能極強的關係資料庫語言, 是對關係資料存取的標準介面, 也是不同資料庫系統之間互操作的基礎。集資料查詢、資料操作、資料定義、和資料控制功能於一體。
2. 資料定義:資料定義功能包括模式定義、表定義、檢視和索引的定義。
3. 巢狀查詢:指將一個查詢塊巢狀在另一個查詢塊的 WHERE 子句或 HAVING 短語的條件中的查詢。
二、重要知識點
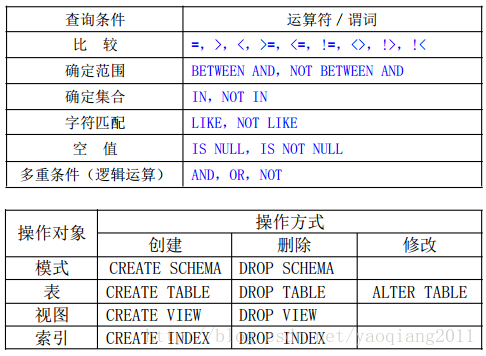
1. SQL 資料定義語句的操作物件有:模式、表、檢視和索引。
2. SQL 資料定義語句的命令動詞是:CREATE、DROP 和 ALTER。
3. RDBMS(關係型資料庫管理系統) 中索引一般採用 B+樹或 HASH 來實現。
4. 索引可以分為唯一索引、非唯一索引和聚簇索引三種類型。
6.SQL 建立表語句的一般格式為
CREATE TABLE <表名>
( <列名> <資料型別>[ <列級完整性約束> ]
[,<列名> <資料型別>[ <列級完整性約束>] ] …
[,<表級完整性約束> ] ) ;
其中<資料型別>可以是資料庫系統支援的各種資料型別,包括長度和精度。
列級完整性約束為針對單個列(本列)的完整性約束, 包括 PRIMARY KEY、 REFERENCES表名(列名)、UNIQUE、NOT NULL 等。
表級完整性約束可以是基於表中多列的約束,包括 PRIMARY KEY ( 列名列表) 、FOREIGN KEY REFERENCES 表名(列名) 等。
7. SQL 建立索引語句的一般格式為
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名> (<列名列表> ) ;
其中UNIQUE:表示建立唯一索引,預設為非唯一索引;
CLUSTER:表示建立聚簇索引,預設為非聚簇索引;
<列名列表>:一個或逗號分隔的多個列名,每個列名後可跟 ASC 或 DESC,表示升/降序,預設為升序。多列時則按為多級排序。
8. SQL 查詢語句的一般格式為
SELECT [ALL|DISTINCT] <算術表示式列表> FROM <表名或檢視名列表>
[ WHERE <條件表示式 1> ]
[ GROUP BY <屬性列表 1> [ HAVING <條件表示式 2 > ] ]
[ ORDER BY <屬性列表 2> [ ASC|DESC ] ] ;
其中
ALL/DISTINCT: 預設為 ALL, 即列出所有查詢結果記錄, 包括重複記錄。 DISTINCT則對重複記錄只列出一條。
算術表示式列表:一個或多個逗號分隔的算術表示式,表示式由常量(包括數字和字串)、列名、函式和算術運算子構成。每個表示式後還可跟別名。也可用 *代表查詢表中的所有列。
<表名或檢視名列表>: 一個或多個逗號分隔的表或檢視名。 表或檢視名後可跟別名。
條件表示式 1:包含關係或邏輯運算子的表示式,代表查詢條件。
條件表示式 2:包含關係或邏輯運算子的表示式,代表分組條件。
<屬性列表 1>:一個或逗號分隔的多個列名。
<屬性列表 2>: 一個或逗號分隔的多個列名, 每個列名後可跟 ASC 或 DESC, 表示升/降序,預設為升序。
關於SQL語句的知識這裡先作如上簡略介紹,具體寫法下次將專門拿出一篇來敘述。
第四節
一、相關概念和知識
1.觸發器是使用者定義在基本表上的一類由事件驅動的特殊過程。由伺服器自動啟用, 能執行更為複雜的檢查和操作,具有更精細和更強大的資料控制能力。使用 CREATE TRIGGER 命令建立觸發器。
2.計算機系統存在技術安全、管理安全和政策法律三類安全性問題。
3. TCSEC/TDI 標準由安全策略、責任、保證和文件四個方面內容構成。
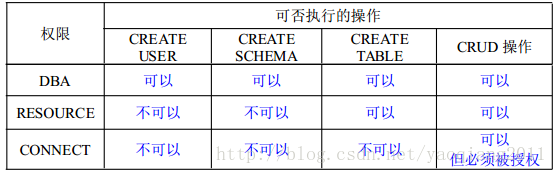
4. 常用存取控制方法包括自主存取控制(DAC)和強制存取控制(MAC)兩種。
5. 自主存取控制(DAC)的 SQL 語句包括 GRANT 和 REVOKE 兩個。 使用者許可權由資料物件和操作型別兩部分構成。
6. 常見SQL 自主許可權控制命令和例子。
1) 把對 Student 和 Course 表的全部許可權授予所有使用者。
GRANT ALL PRIVILIGES ON TABLE Student,Course TO PUBLIC ;
2) 把對 Student 表的查詢權和姓名修改權授予使用者 U4。
GRANT SELECT,UPDATE(Sname) ON TABLE Student TO U4 ;
3) 把對 SC 表的插入許可權授予 U5 使用者,並允許他傳播該許可權。
GRANT INSERT ON TABLE SC TO U5 WITH GRANT OPTION ;
4) 把使用者 U5 對 SC 表的 INSERT 許可權收回,同時收回被他傳播出去的授權。
REVOKE INSERT ON TABLE SC FROM U5 CASCADE ;
5) 建立一個角色 R1,並使其對 Student 表具有資料查詢和更新許可權。
CREATE ROLE R1;
GRANT SELECT,UPDATE ON TABLE Student TO R1;
6) 對修改 Student 表結構的操作進行審計。
AUDIT ALTER ON Student ;
一、相關概念和知識點
1.資料依賴:反映一個關係內部屬性與屬性之間的約束關係,是現實世界屬性間相互聯絡的抽象,屬於資料內在的性質和語義的體現。
2. 規範化理論:是用來設計良好的關係模式的基本理論。它通過分解關係模式來消除其中不合適的資料依賴,以解決插入異常、刪除異常、更新異常和資料冗餘問題。
3. 函式依賴:簡單地說,對於關係模式的兩個屬性子集X和Y,若X的任一取值能唯一確定Y的值,則稱Y函式依賴於X,記作X→Y。
4. 非平凡函式依賴:對於關係模式的兩個屬性子集X和Y,如果X→Y,但Y!⊆X,則稱X→Y為非平凡函式依賴;如果X→Y,但Y⊆X,則稱X→Y為非平凡函式依賴。
5. 完全函式依賴:對於關係模式的兩個屬性子集X和Y,如果X→Y,並且對於X的任何一個真子集X',都沒有X'→Y,則稱Y對X完全函式依賴。
6. 正規化:指符合某一種級別的關係模式的集合。在設計關係資料庫時,根據滿足依賴關係要求的不同定義為不同的正規化。
7. 規範化:指將一個低一級正規化的關係模式,通過模式分解轉換為若干個高一級正規化的關係模式的集合的過程。
8. 1NF:若關係模式的所有屬性都是不可分的基本資料項,則該關係模式屬於1NF。
9. 2NF:1NF關係模式如果同時滿足每一個非主屬性完全函式依賴於碼,則該關係模式屬於2NF。
10. 3NF:若關係模式的每一個非主屬性既不部分依賴於碼也不傳遞依賴於碼,則該關係模式屬於3NF。
11. BCNF:若一個關係模式的每一個決定因素都包含碼,則該關係模式屬於BCNF。
12. 資料庫設計:是指對於一個給定的應用環境,構造優化的資料庫邏輯模式和物理結構,並據此建立資料庫及其應用系統,使之能夠有效地儲存和管理資料,滿足各種使用者的應用需求,包括資訊管理要求和資料操作要求。
13. 資料庫設計的6個基本步驟:需求分析,概念結構設計,邏輯結構設計,物理結構設計,資料庫實施,資料庫執行和維護。
14. 概念結構設計:指將需求分析得到的使用者需求抽象為資訊結構即概念模型的過程。也就是通過對使用者需求進行綜合、歸納與抽象,形成一個獨立於具體DBMS的概念模型。
15. 邏輯結構設計:將概念結構模型(基本E-R圖)轉換為某個DBMS產品所支援的資料模型相符合的邏輯結構,並對其進行優化。
16. 物理結構設計:指為一個給定的邏輯資料模型選取一個最適合應用環境的物理結構的過程。包括設計資料庫的儲存結構與存取方法。
17. 抽象:指對實際的人、物、事和概念進行人為處理,抽取所關心的共同特性,忽略非本質的細節,並把這些特性用各種概念精確地加以描述,這些概念組成了某種模型。
18. 資料庫設計必須遵循結構設計和行為設計相結合的原則。
19. 資料字典主要包括資料項、資料結構、資料流、資料儲存和處理過程五個部分。
20. 三種常用抽象方法是分類、聚集和概括。
21. 區域性 E-R 圖之間的衝突主要表現在屬性衝突、命名衝突和結構衝突三個方面。
22. 資料庫常用的存取方法包括索引方法、聚簇方法和 HASH方法三種。
23. 確定資料存放位置和儲存結構需要考慮的因素主要有: 存取時間、 儲存空間利用率和維護代價等。
二、細說資料庫三正規化
2.1 第一正規化(1NF)無重複的列
第一正規化(1NF)中資料庫表的每一列都是不可分割的基本資料項
同一列中不能有多個值
即實體中的某個屬性不能有多個值或者不能有重複的屬性。
簡而言之,第一正規化就是無重複的列。
在任何一個關係資料庫中,第一正規化(1NF)是對關係模式的基本要求,不滿足第一正規化(1NF)的資料庫就不是關係資料庫。
2.2 第二正規化(2NF)屬性完全依賴於主鍵[消除部分子函式依賴]
滿足第二正規化(2NF)必須先滿足第一正規化(1NF)。
第二正規化(2NF)要求資料庫表中的每個例項或行必須可以被惟一地區分。
為實現區分通常需要為表加上一個列,以儲存各個例項的惟一標識。
第二正規化(2NF)要求實體的屬性完全依賴於主關鍵字。所謂完全依賴是指不能存在僅依賴主關鍵字一部分的屬性,如果存在,那麼這個屬性和主關鍵字的這一部分應該分離出來形成一個新的實體,新實體與原實體之間是一對多的關係。為實現區分通常需要為表加上一個列,以儲存各個例項的惟一標識。簡而言之,第二正規化就是屬性完全依賴於主鍵。
2.3 第三正規化(3NF)屬性不依賴於其它非主屬性[消除傳遞依賴]
滿足第三正規化(3NF)必須先滿足第二正規化(2NF)。
簡而言之,第三正規化(3NF)要求一個數據庫表中不包含已在其它表中已包含的非主關鍵字資訊。
例如,存在一個部門資訊表,其中每個部門有部門編號(dept_id)、部門名稱、部門簡介等資訊。那麼在的員工資訊表中列出部門編號後就不能再將部門名稱、部門簡介等與部門有關的資訊再加入員工資訊表中。如果不存在部門資訊表,則根據第三正規化(3NF)也應該構建它,否則就會有大量的資料冗餘。簡而言之,第三正規化就是屬性不依賴於其它非主屬性。
2.4 具體例項剖析
下面列舉一個學校的學生系統的例項,以示幾個正規化的應用。
在設計資料庫表結構之前,我們先確定一下要設計的內容包括那些。學號、學生姓名、年齡、性別、課程、課程學分、系別、學科成績,系辦地址、系辦電話等資訊。為了簡單我們暫時只考慮這些欄位資訊。我們對於這些資訊,說關心的問題有如下幾個方面。
1)學生有那些基本資訊
2)學生選了那些課,成績是什麼
3)每個課的學分是多少
4)學生屬於那個系,系的基本資訊是什麼。
首先第一正規化(1NF):資料庫表中的欄位都是單一屬性的,不可再分。這個單一屬性由基本型別構成,包括整型、實數、字元型、邏輯型、日期型等。在當前的任何關係資料庫管理系統(DBMS)中,不允許你把資料庫表的一列再分成二列或多列,因此做出的都是符合第一正規化的資料庫。
我們再考慮第二正規化,把所有這些資訊放到一個表中(學號,學生姓名、年齡、性別、課程、課程學分、系別、學科成績,系辦地址、系辦電話)下面存在如下的依賴關係。
1)(學號)→ (姓名, 年齡,性別,系別,系辦地址、系辦電話)
2) (課程名稱) → (學分)
3)(學號,課程)→ (學科成績)
根據依賴關係我們可以把選課關係表SelectCourse改為如下三個表:
學生:Student(學號,姓名, 年齡,性別,系別,系辦地址、系辦電話);
課程:Course(課程名稱, 學分);
選課關係:SelectCourse(學號, 課程名稱, 成績)。
事實上,對照第二正規化的要求,這就是滿足第二正規化的資料庫表,若不滿足第二正規化,會產生如下問題
資料冗餘: 同一門課程由n個學生選修,"學分"就重複n-1次;同一個學生選修了m門課程,姓名和年齡就重複了m-1次。
更新異常: 1)若調整了某門課程的學分,資料表中所有行的"學分"值都要更新,否則會出現同一門課程學分不同的情況。
2)假設要開設一門新的課程,暫時還沒有人選修。這樣,由於還沒有"學號"關鍵字,課程名稱和學分也無法記錄入資料庫。
刪除異常 : 假設一批學生已經完成課程的選修,這些選修記錄就應該從資料庫表中刪除。但是,與此同時,課程名稱和學分資訊也被刪除了。很顯然,這也會導致插入異常。
我們再考慮如何將其改成滿足第三正規化的資料庫表,接著看上面的學生表Student(學號,姓名, 年齡,性別,系別,系辦地址、系辦電話),關鍵字為單一關鍵字"學號",因為存在如下決定關係:
(學號)→ (姓名, 年齡,性別,系別,系辦地址、系辦電話)
但是還存在下面的決定關係
(學號) → (所在學院)→(學院地點, 學院電話)
即存在非關鍵欄位"學院地點"、"學院電話"對關鍵欄位"學號"的傳遞函式依賴。
它也會存在資料冗餘、更新異常、插入異常和刪除異常的情況(這裡就不具體分析了,參照第二正規化中的分析)。根據第三正規化把學生關係表分為如下兩個表就可以滿足第三正規化了:
學生:(學號, 姓名, 年齡, 性別,系別);
系別:(系別, 系辦地址、系辦電話)。
SQL語句中常用關鍵詞及其解釋如下:
將資料從資料庫中的表格內選出,兩個關鍵字:從 (FROM) 資料庫中的表格內選出 (SELECT)。語法為
SELECT "欄位名" FROM "表格名"。
在上述 SELECT 關鍵詞後加上一個 DISTINCT 就可以去除選擇出來的欄位中的重複,從而完成求得這個表格/欄位內有哪些不同的值的功能。語法為
SELECT DISTINCT "欄位名" FROM "表格名"。
這個關鍵詞可以幫助我們選擇性地抓資料,而不是全取出來。語法為
SELECT "欄位名" FROM "表格名" WHERE "條件"
上例中的 WHERE 指令可以被用來由表格中有條件地選取資料。這個條件可能是簡單的 (像上一頁的例子),也可能是複雜的。複雜條件是由二或多個簡單條件透過 AND 或是 OR 的連線而成。語法為:
SELECT "欄位名" FROM "表格名" WHERE "簡單條件" {[AND|OR] "簡單條件"}+
在 SQL 中,在兩個情況下會用到 IN 這個指令;這一頁將介紹其中之一:與 WHERE 有關的那一個情況。在這個用法下,我們事先已知道至少一個我們需要的值,而我們將這些知道的值都放入 IN 這個子句。語法為:
SELECT "欄位名" FROM "表格名" WHERE "欄位名" IN ('值一', '值二', ...)
IN 這個指令可以讓我們依照一或數個不連續 (discrete)的值的限制之內抓出資料庫中的值,而 BETWEEN 則是讓我們可以運用一個範圍 (range) 內抓出資料庫中的值,語法為:
SELECT "欄位名" FROM "表格名" WHERE "欄位名" BETWEEN '值一' AND '值二'
LIKE 是另一個在 WHERE 子句中會用到的指令。基本上, LIKE 能讓我們依據一個模式(pattern) 來找出我們要的資料。語法為:
SELECT "欄位名" FROM "表格名" WHERE "欄位名" LIKE {模式}
我們經常需要能夠將抓出的資料做一個有系統的顯示。這可能是由小往大 (ascending) 或是由大往小(descending)。在這種情況下,我們就可以運用 ORDER BY 這個指令來達到我們的目的。語法為:
SELECT "欄位名" FROM "表格名 [WHERE "條件"] ORDER BY "欄位名" [ASC, DESC]
函式允許我們能夠對這些數字的型態存在的行或者列做運算,包括 AVG (平均)、COUNT (計數)、MAX (最大值)、MIN (最小值)、SUM (總合)。語法為:
SELECT "函式名"("欄位名") FROM "表格名"
這個關鍵詞能夠幫我我們統計有多少筆資料被選出來,語法為:
SELECT COUNT("欄位名") FROM "表格名"
GROUP BY 語句用於結合合計函式,根據一個或多個列對結果集進行分組。語法為:
SELECT "欄位1", SUM("欄位2") FROM "表格名" GROUP BY "欄位1"
該關鍵詞可以幫助我們對函式產生的值來設定條件。語法為:
SELECT "欄位1", SUM("欄位2") FROM "表格名" GROUP BY "欄位1" HAVING (函式條件)
我們可以通過ALIAS為列名稱和表名稱指定別名,語法為:
SELECT "表格別名"."欄位1" "欄位別名" FROM "表格名" "表格別名"
下面為一個例子,通過它我們應該能很好地掌握以上關鍵詞的使用方法。
Student(S#,Sname,Sage,Ssex) 學生表
Course(C#,Cname,T#) 課程表
SC(S#,C#,score) 成績表
Teacher(T#,Tname) 教師表
問題:
1、查詢“001”課程比“002”課程成績高的所有學生的學號;
select a.S#
from (select s#,score from SC where C#=’001′) a,
(select s#,score from SC where C#=’002′) b
where a.score>b.score and a.s#=b.s#;
2、查詢平均成績大於60分的同學的學號和平均成績;
select S#,avg(score)
from sc
group by S# having avg(score) >60;
3、查詢所有同學的學號、姓名、選課數、總成績;
select Student.S#,Student.Sname,count(SC.C#),sum(score)
from Student left Outer join SC on Student.S#=SC.S#
group by Student.S#,Sname
4、查詢姓“李”的老師的個數;
select count(distinct(Tname))
from Teacher
where Tname like ‘李%’;
5、查詢沒學過“葉平”老師課的同學的學號、姓名;
select Student.S#,Student.Sname
from Student
where S# not in (select distinct( SC.S#) from SC,Course,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname=’葉平’);
6、查詢學過“001”並且也學過編號“002”課程的同學的學號、姓名;
select Student.S#,Student.Sname
from Student,SC
where Student.S#=SC.S# and SC.C#=’001′and exists( Select * from SC as SC_2 where SC_2.S#=SC.S# and SC_2.C#=’002′);
7、查詢學過“葉平”老師所教的所有課的同學的學號、姓名;
select S#,Sname
from Student
where S# in
(select S#
from SC ,Course ,Teacher
where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname=’葉平’ group by S# having count(SC.C#)=(select count(C#) from Course,Teacher where Teacher.T#=Course.T# and Tname=’葉平’));
8、查詢所有課程成績小於60分的同學的學號、姓名;
select S#,Sname
from Student
where S# not in (select Student.S# from Student,SC where S.S#=SC.S# and score>60);
9、查詢沒有學全所有課的同學的學號、姓名;
select Student.S#,Student.Sname
from Student,SC
where Student.S#=SC.S#
group by Student.S#,Student.Sname having count(C#) <(select count(C#) from Course);
10、查詢至少有一門課與學號為“1001”的同學所學相同的同學的學號和姓名;
select S#,Sname
from Student,SC
where Student.S#=SC.S# and C# in (select C# from SC where S#='1001');
11、刪除學習“葉平”老師課的SC表記錄;
Delect SC
from course ,Teacher
where Course.C#=SC.C# and Course.T#= Teacher.T# and Tname='葉平';
12、查詢各科成績最高和最低的分:以如下形式顯示:課程ID,最高分,最低分
SELECT L.C# 課程ID,L.score 最高分,R.score 最低分
FROM SC L ,SC R
WHERE L.C# = R.C#
and
L.score = (SELECT MAX(IL.score)
FROM SC IL,Student IM
WHERE IL.C# = L.C# and IM.S#=IL.S#
GROUP BY IL.C#)
and
R.Score = (SELECT MIN(IR.score)
FROM SC IR
WHERE IR.C# = R.C#
GROUP BY IR.C# );
13、查詢學生平均成績及其名次
SELECT 1+(SELECT COUNT( distinct 平均成績)
FROM (SELECT S#,AVG(score) 平均成績
FROM SC
GROUP BY S# ) T1
WHERE 平均成績 > T2.平均成績) 名次, S# 學生學號,平均成績
FROM (SELECT S#,AVG(score) 平均成績 FROM SC GROUP BY S# ) T2
ORDER BY 平均成績 desc;
14、查詢各科成績前三名的記錄:(不考慮成績並列情況)
SELECT t1.S# as 學生ID,t1.C# as 課程ID,Score as 分數
FROM SC t1
WHERE score IN (SELECT TOP 3 score
FROM SC
WHERE t1.C#= C#
ORDER BY score DESC)
ORDER BY t1.C#;
15、查詢每門功成績最好的前兩名
SELECT t1.S# as 學生ID,t1.C# as 課程ID,Score as 分數
FROM SC t1
WHERE score IN (SELECT TOP 2 score
FROM SC
WHERE t1.C#= C#
ORDER BY score DESC )
ORDER BY t1.C#;