
char* 和char[]的區別
以下內容均來自網際網路,系筆者彙總並總結。
1. 問題介紹
問題引入:
在實習過程中發現了一個以前一直預設的錯誤,同樣char *c = "abc"和char c[]="abc",前者改變其內
容程式是會崩潰的,而後者完全正確。
程式演示:
測試環境Devc++
程式碼
#include <iostream>
using namespace std;
main()
{
char *c1 = "abc";
char c2[] = "abc";
char *c3 = ( char* )malloc(3);
c3 = "abc";
printf("%d %d %s\n",&c1,c1,c1);
printf("%d %d %s\n",&c2,c2,c2);
printf("%d %d %s\n",&c3,c3,c3);
getchar();
}
執行結果
2293628 4199056 abc
2293624 2293624 abc
2293620 4199056 abc
參考資料:
首先要搞清楚編譯程式佔用的記憶體的分割槽形式:
一、預備知識—程式的記憶體分配
一個由c/C++編譯的程式佔用的記憶體分為以下幾個部分
1、棧區(stack)—由編譯器自動分配釋放,存放函式的引數值,區域性變數的值等。其操作方式類似於
資料結構中的棧。
2、堆區(heap)—一般由程式設計師分配釋放,若程式設計師不釋放,程式結束時可能由OS回收。注意它與資料
結構中的堆是兩回事,分配方式倒是類似於連結串列,呵呵。
3、全域性區(靜態區)(static)—全域性變數和靜態變數的儲存是放在一塊的,初始化的全域性變數和靜態
變數在一塊區域,未初始化的全域性變數和未初始化的靜態變數在相鄰的另一塊區域。程式結束後由系統
釋放。
4、文字常量區—常量字串就是放在這裡的。程式結束後由系統釋放。
5、程式程式碼區
這是一個前輩寫的,非常詳細
//main.cpp
int a=0; //全域性初始化區
char *p1; //全域性未初始化區
main()
{
int b;棧
char s[]="abc"; //棧
char *p2; //棧
char *p3="123456"; //123456\0在常量區,p3在棧上。
static int c=0; //全域性(靜態)初始化區
p1 = (char*)malloc(10);
p2 = (char*)malloc(20); //分配得來得10和20位元組的區域就在堆區。
strcpy(p1,"123456"); //123456\0放在常量區,編譯器可能會將它與p3所向"123456"優化成一個
地方。
}
二、堆和棧的理論知識
2.1申請方式
stack:
由系統自動分配。例如,宣告在函式中一個區域性變數int b;系統自動在棧中為b開闢空間
heap:
需要程式設計師自己申請,並指明大小,在c中malloc函式
如p1=(char*)malloc(10);
在C++中用new運算子
如p2=(char*)malloc(10);
但是注意p1、p2本身是在棧中的。
2.2
申請後系統的響應
棧:只要棧的剩餘空間大於所申請空間,系統將為程式提供記憶體,否則將報異常提示棧溢位。
堆:首先應該知道作業系統有一個記錄空閒記憶體地址的連結串列,當系統收到程式的申請時,
會遍歷該連結串列,尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閒結點連結串列中刪除,並將
該結點的空間分配給程式,另外,對於大多數系統,會在這塊記憶體空間中的首地址處記錄本次分配的大
小,這樣,程式碼中的delete語句才能正確的釋放本記憶體空間。另外,由於找到的堆結點的大小不一定正
好等於申請的大小,系統會自動的將多餘的那部分重新放入空閒連結串列中。
2.3申請大小的限制
棧:在Windows下,棧是向低地址擴充套件的資料結構,是一塊連續的記憶體的區域。這句話的意思是棧頂的地
址和棧的最大容量是系統預先規定好的,在WINDOWS下,棧的大小是2M(也有的說是1M,總之是一個編譯
時就確定的常數),如果申請的空間超過棧的剩餘空間時,將提示overflow。因此,能從棧獲得的空間
較小。
堆:堆是向高地址擴充套件的資料結構,是不連續的記憶體區域。這是由於系統是用連結串列來儲存的空閒記憶體地
址的,自然是不連續的,而連結串列的遍歷方向是由低地址向高地址。堆的大小受限於計算機系統中有效的
虛擬記憶體。由此可見,堆獲得的空間比較靈活,也比較大。
2.4申請效率的比較:
棧:由系統自動分配,速度較快。但程式設計師是無法控制的。
堆:是由new分配的記憶體,一般速度比較慢,而且容易產生記憶體碎片,不過用起來最方便.
另外,在WINDOWS下,最好的方式是用Virtual Alloc分配記憶體,他不是在堆,也不是在棧,而是直接在進
程的地址空間中保留一塊記憶體,雖然用起來最不方便。但是速度快,也最靈活。
2.5堆和棧中的儲存內容
棧:在函式呼叫時,第一個進棧的是主函式中後的下一條指令(函式呼叫語句的下一條可執行語句)的
地址,然後是函式的各個引數,在大多數的C編譯器中,引數是由右往左入棧的,然後是函式中的區域性變
量。注意靜態變數是不入棧的。
當本次函式呼叫結束後,區域性變數先出棧,然後是引數,最後棧頂指標指向最開始存的地址,也就是主
函式中的下一條指令,程式由該點繼續執行。
堆:一般是在堆的頭部用一個位元組存放堆的大小。堆中的具體內容由程式設計師安排。
2.6存取效率的比較
char s1[]="aaaaaaaaaaaaaaa";
char *s2="bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在執行時刻賦值的;
而bbbbbbbbbbb是在編譯時就確定的;
但是,在以後的存取中,在棧上的陣列比指標所指向的字串(例如堆)快。
比如:
#include
voidmain()
{
char a=1;
char c[]="1234567890";
char *p="1234567890";
a = c[1];
a = p[1];
return;
}
對應的彙編程式碼
10:a=c[1];
004010678A4DF1movcl,byteptr[ebp-0Fh]
0040106A884DFCmovbyteptr[ebp-4],cl
11:a=p[1];
0040106D8B55ECmovedx,dwordptr[ebp-14h]
004010708A4201moval,byteptr[edx+1]
004010738845FCmovbyteptr[ebp-4],al
第一種在讀取時直接就把字串中的元素讀到暫存器cl中,而第二種則要先把指標值讀到edx中,在根據
edx讀取字元,顯然慢了。
2.7小結:
堆和棧的區別可以用如下的比喻來看出:
使用棧就象我們去飯館裡吃飯,只管點菜(發出申請)、付錢、和吃(使用),吃飽了就走,不必理會
切菜、洗菜等準備工作和洗碗、刷鍋等掃尾工作,他的好處是快捷,但是自由度小。
使用堆就象是自己動手做喜歡吃的菜餚,比較麻煩,但是比較符合自己的口味,而且自由度大。
自我總結:
char *c1 = "abc";實際上先是在文字常量區分配了一塊記憶體放"abc",然後在棧上分配一地址給c1並指向
這塊地址,然後改變常量"abc"自然會崩潰
然而char c2[] = "abc",實際上abc分配記憶體的地方和上者並不一樣,可以從
4199056
2293624 看出,完全是兩塊地方,推斷4199056處於常量區,而2293624處於棧區
2293628
2293624
2293620 這段輸出看出三個指標分配的區域為棧區,而且是從高地址到低地址
2293620 4199056 abc 看出編譯器將c3優化指向常量區的"abc"
繼續思考:
程式碼:
#include <iostream>
using namespace std;
main()
{
char *c1 = "abc";
char c2[] = "abc";
char *c3 = ( char* )malloc(3);
// *c3 = "abc" //error
strcpy(c3,"abc");
c3[0] = 'g';
printf("%d %d %s\n",&c1,c1,c1);
printf("%d %d %s\n",&c2,c2,c2);
printf("%d %d %s\n",&c3,c3,c3);
getchar();
}
輸出:
2293628 4199056 abc
2293624 2293624 abc
2293620 4012976 gbc
寫成註釋那樣,後面改動就會崩潰
可見strcpy(c3,"abc");abc是另一塊地方分配的,而且可以改變,和上面的參考文件說法有些不一定,
而且我不能斷定4012976是哪個區的,可能要通過算區的長度,希望高人繼續深入解釋,謝謝
2. 一個例項
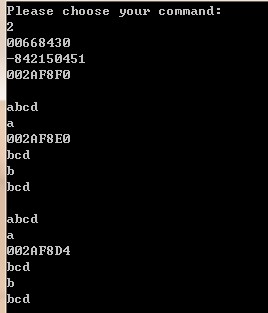
int *ip = new int;
char s[] = "abcd";
char* p = "abcd";
cout<<ip<<endl;
cout<<*ip<<endl;
cout<<&ip<<endl;
// s = p; //error C2440: '=' : cannot convert from 'char *' to 'char'
//難道s不是指向第一個字元的指標嗎?
cout << s <<endl;//果然這句話輸出的是abcd!
cout << *s <<endl;//但這句輸出的是a!
cout << &s <<endl;
cout << (s+1) <<endl;
// cout << &(s+1) <<endl;//error C2102: '&' requires l-value
cout << *(s+1) <<endl;
cout << &s[1] <<endl;
cout << p <<endl;
cout << *p <<endl;
cout << &p <<endl;
cout << (p+1) <<endl;
// cout << &(p+1) <<endl;//error C2102: '&' requires l-value
cout << *(p+1) <<endl;
cout << &p[1] <<endl;輸出:
相關解釋:
char[]是一個數組定義,char*是指標定義,你可以看下他們的區別,對你會有幫助。
1 指標和陣列的區別
(1)指標和陣列的分配
陣列是開闢一塊連續的記憶體空間,陣列本身的識別符號(也就是通常所說的陣列名)代表整個陣列,可以使用sizeof來獲得陣列所佔據記憶體空間的大小(注意,不是陣列元素的個數,而是陣列佔據記憶體空間的大小,這是以位元組為單位的)。舉例如下:
#include <stdio.h>
int main(void)
{
char a[] = "hello";
int b[] = {1, 2, 3, 4, 5};
printf("a: %d\n", sizeof(a));
printf("b memory size: %d bytes\n", sizeof(b));
printf("b elements: %d\n", sizeof(b)/sizeof(int));
return 0;
}
陣列a為字元型,後面的字串實際上佔據6個位元組空間(注意最後有一個\0標識字串的結束)。從後面sizeof(b)就可以看出如何獲得陣列佔據的記憶體空間,如何獲得陣列的元素數目。至於int資料型別分配記憶體空間的多少,則是編譯器相關的。gcc預設為int型別分配4個位元組的記憶體空間。
(2)空間的分配
這裡又分為兩種情況。
第一,如果是全域性的和靜態的
char *p = “hello”;
這是定義了一個指標,指向rodata section裡面的“hello”,可以被編譯器放到字串池。在彙編裡面的關鍵字為.ltorg。意思就是在字串池裡的字串是可以共享的,這也是編譯器優化的一個措施。
char a[] = “hello”;
這是定義了一個數組,分配在可寫資料塊,不會被放到字串池。
第二,如果是區域性的
char *p = “hello”;
這是定義了一個指標,指向rodata section裡面的“hello”,可以被編譯器放到字串池。在彙編裡面的關鍵字為.ltorg。意思就是在字串池裡的字串是可以共享的,這也是編譯器優化的一個措施。另外,在函式中可以返回它的地址,也就是說,指標是區域性變數,但是它指向的內容是全域性的。
char a[] = “hello”;
這是定義了一個數組,分配在堆疊上,初始化由編譯器進行。(短的時候直接用指令填充,長的時候就從全域性字串表拷貝),不會被放到字串池(同樣如前,可能會從字串池中拷貝過來)。注意不應該返回它的地址。
cout經研究得出以下結論:
1、對於數字指標如int *p=new int; 那麼cout<<p只會輸出這個指標的值,而不會輸出這個指標指向的內容。
2、對於字元指標入char *p="sdf f";那麼cout<<p就會輸出指標指向的資料,即sdf f
============================================================================
如果還不是很理解,水木上也有高人對此進行解釋:
這裡的char ch[]="abc";
表示ch 是一個足以存放字串初值和空字元'/0'的一維陣列,可以更改陣列中的字元,但是char本身是不可改變的常量。
char *pch = "abc";
那麼pch 是一個指標,其初值指向一個字串常量,之後它可以指向其他位置,但如果試圖修改字串的內容,結果將不確定。
______ ______ ______
ch: |abc\0 | pch: | ◎-----> |abc\0 |
______ ______ ______
char chArray[100];
chArray[i] 等價於 *(chArray+i)
和指標的不同在於 chArray不是變數 無法對之賦值
另 事實上 i[chArray] 也等價於 *(chArray+i)
因此,總結如下:
1. char[] p表示p是一個數組指標,相當於const pointer,不允許對該指標進行修改。但該指標所指向的陣列內容,是分配在棧上面的,是可以修改的。
2. char * pp表示pp是一個可變指標,允許對其進行修改,即可以指向其他地方,如pp = p也是可以的。對於*pp = "abc";這樣的情況,由於編譯器優化,一般都會將abc存放在常量區域內,然後pp指標是區域性變數,存放在棧中,因此,在函式返回中,允許返回該地址(實際上指向一個常量地址,字串常量區);而,char[] p是區域性變數,當函式結束,存在棧中的陣列內容均被銷燬,因此返回p地址是不允許的。
同時,從上面的例子可以看出,cout確實存在一些規律:
1、對於數字指標如int *p=new int; 那麼cout<<p只會輸出這個指標的值,而不會輸出這個指標指向的內容。
2、對於字元指標入char *p="sdf f";那麼cout<<p就會輸出指標指向的資料,即sdf f
那麼,像&(p+1),由於p+1指向的是一個地址,不是一個指標,無法進行取址操作。
&p[1] = &p + 1,這樣取到的實際上是從p+1開始的字串內容。
分析上面的程式:
*pp = "abc";
p[] = "abc";
*pp指向的是字串中的第一個字元。
cout << pp; // 返回pp地址開始的字串:abc
cout << p; // 返回p地址開始的字串:abc
cout << *p; // 返回第一個字元:a
cout << *(p+1); // 返回第二個字元:b
cout << &p[1];// 返回從第二個字元開始的字串:bc