
【轉】主題模型--pLSA,LDA
一句話總結:LDA在PLSA的基礎上,為主題分佈和詞分佈分別加了兩個Dirichlet先驗
那PLSA跟LDA的區別在於什麼地方呢?區別就在於:- PLSA中,主題分佈和詞分佈是唯一確定的,能明確的指出主題分佈可能就是{教育:0.5,經濟:0.3,交通:0.2},詞分佈可能就是{大學:0.5,老師:0.3,課程:0.2}。
- 但在LDA中,主題分佈和詞分佈不再唯一確定不變,即無法確切給出。例如主題分佈可能是{教育:0.5,經濟:0.3,交通:0.2},也可能是{教育:0.6,經濟:0.2,交通:0.2},到底是哪個我們不再確定(即不知道),因為它是隨機的可變化的。但再怎麼變化,也依然服從一定的分佈,即主題分佈跟詞分佈由Dirichlet先驗隨機確定。
上個月參加了在北京舉辦SIGKDD國際會議,在個性化推薦、社交網路、廣告預測等各個領域的workshop上都提到LDA模型,感覺這個模型的應用挺廣泛的,會後抽時間瞭解了一下LDA,做一下總結:
(一)LDA作用
傳統判斷兩個文件相似性的方法是通過檢視兩個文件共同出現的單詞的多少,如TF-IDF等,這種方法沒有考慮到文字背後的語義關聯,可能在兩個文件共同出現的單詞很少甚至沒有,但兩個文件是相似的。
舉個例子,有兩個句子分別如下:
“喬布斯離我們而去了。”
“蘋果價格會不會降?”
可以看到上面這兩個句子沒有共同出現的單詞,但這兩個句子是相似的,如果按傳統的方法判斷這兩個句子肯定不相似,所以在判斷文件相關性的時候需要考慮到文件的語義,而語義挖掘的利器是主題模型,LDA就是其中一種比較有效的模型。
在主題模型中,主題表示一個概念、一個方面,表現為一系列相關的單詞,是這些單詞的條件概率。形象來說,主題就是一個桶,裡面裝了出現概率較高的單詞,這些單詞與這個主題有很強的相關性。
怎樣才能生成主題?對文章的主題應該怎麼分析?這是主題模型要解決的問題。
首先,可以用生成模型來看文件和主題這兩件事。所謂生成模型,就是說,我們認為一篇文章的每個詞都是通過“以一定概率選擇了某個主題,並從這個主題中以一定概率選擇某個詞語”

這個概率公式可以用矩陣表示:

其中”文件-詞語”矩陣表示每個文件中每個單詞的詞頻,即出現的概率;”主題-詞語”矩陣表示每個主題中每個單詞的出現概率;”文件-主題”矩陣表示每個文件中每個主題出現的概率。
給定一系列文件,通過對文件進行分詞,計算各個文件中每個單詞的詞頻就可以得到左邊這邊”文件-詞語”矩陣。主題模型就是通過左邊這個矩陣進行訓練,學習出右邊兩個矩陣。
主題模型有兩種:pLSA(ProbabilisticLatent Semantic Analysis)和LDA(Latent Dirichlet Allocation),下面主要介紹LDA。
(二)LDA介紹
如何生成M份包含N個單詞的文件,LatentDirichlet Allocation這篇文章介紹了3方法:
方法一:unigram model
該模型使用下面方法生成1個文件:
For each ofthe N words w_n:
Choose a word w_n ~ p(w);
其中N表示要生成的文件的單詞的個數,w_n表示生成的第n個單詞w,p(w)表示單詞w的分佈,可以通過語料進行統計學習得到,比如給一本書,統計各個單詞在書中出現的概率。
這種方法通過訓練語料獲得一個單詞的概率分佈函式,然後根據這個概率分佈函式每次生成一個單詞,使用這個方法M次生成M個文件。其圖模型如下圖所示:

方法二:Mixture of unigram
unigram模型的方法的缺點就是生成的文字沒有主題【只有根據概率每個出現的多少】,過於簡單,mixture of unigram方法對其進行了改進,該模型使用下面方法生成1個文件:
Choose a topicz ~ p(z);
For each ofthe N words w_n:
Choose a word w_n ~ p(w|z);
其中z表示一個主題,p(z)表示主題的概率分佈,z通過p(z)按概率產生;N和w_n同上;p(w|z)表示給定z時w的分佈,可以看成一個k×V的矩陣,k為主題的個數,V為單詞的個數,每行表示這個主題對應的單詞的概率分佈,即主題z所包含的各個單詞的概率,通過這個概率分佈按一定概率生成每個單詞。
這種方法首先選選定一個主題z,主題z對應一個單詞的概率分佈p(w|z),每次按這個分佈生成一個單詞,使用M次這個方法生成M份不同的文件。其圖模型如下圖所示:

從上圖可以看出,z在w所在的長方形外面,表示z生成一份N個單詞的文件時主題z只生成一次,即只允許一個文件只有一個主題,這不太符合常規情況,通常一個文件可能包含多個主題。
方法三:LDA(Latent Dirichlet Allocation)
LDA方法使生成的文件可以包含多個主題,該模型使用下面方法生成1個文件:
Chooseparameter θ ~ p(θ);
For each ofthe N words w_n:
Choose a topic z_n ~ p(z|θ);
Choose a word w_n ~ p(w|z);
其中θ是一個主題向量,向量的每一列表示每個主題在文件出現的概率,該向量為非負歸一化向量;p(θ)是θ的分佈,具體為Dirichlet分佈,即分佈的分佈;N和w_n同上;z_n表示選擇的主題,p(z|θ)表示給定θ時主題z的概率分佈,具體為θ的值,即p(z=i|θ)= θ_i;p(w|z)同上。
這種方法首先選定一個主題向量θ,確定每個主題被選擇的概率。然後在生成每個單詞的時候,從主題分佈向量θ中選擇一個主題z,按主題z的單詞概率分佈生成一個單詞。其圖模型如下圖所示:

從上圖可知LDA的聯合概率為:

把上面的式子對應到圖上,可以大致按下圖理解:

【鄒博的講義中β到fai-k還有一步】
從上圖可以看出,LDA的三個表示層被三種顏色表示出來:
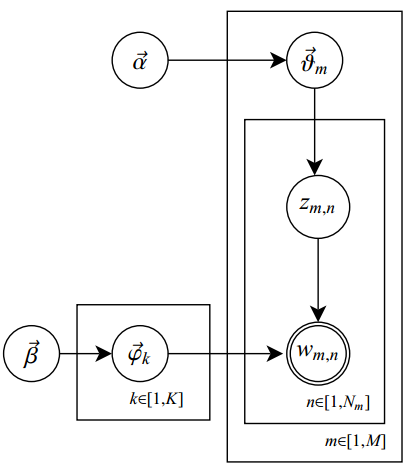
1. corpus-level(紅色):α和β表示語料級別的引數,也就是每個文件都一樣,因此生成過程只採樣一次。
2.document-level(橙色):θ是文件級別的變數,每個文件對應一個θ,也就是每個文件產生各個主題z的概率是不同的,所有生成每個文件取樣一次θ。
3. word-level(綠色):z和w都是單詞級別變數,z由θ生成,w由z和β共同生成,一個 單詞w對應一個主題z。
通過上面對LDA生成模型的討論,可以知道LDA模型主要是從給定的輸入語料中學習訓練兩個控制引數α和β,學習出了這兩個控制引數就確定了模型,便可以用來生成文件。其中α和β分別對應以下各個資訊:
α:分佈p(θ)需要一個向量引數,即Dirichlet分佈的引數,用於生成一個主題θ向量;
β:各個主題對應的單詞概率分佈矩陣p(w|z)。
把w當做觀察變數,θ和z當做隱藏變數,就可以通過EM演算法學習出α和β,求解過程中遇到後驗概率p(θ,z|w)無法直接求解,需要找一個似然函式下界來近似求解,原文使用基於分解(factorization)假設的變分法(varialtional inference)進行計算,用到了EM演算法。每次E-step輸入α和β,計算似然函式,M-step最大化這個似然函式,算出α和β,不斷迭代直到收斂。
參考文獻:
David M. Blei, AndrewY. Ng, Michael I. Jordan, LatentDirichlet Allocation, Journal of Machine Learning Research 3, p993-1022,2003
原文連結:
http://blog.csdn.net/v_july_v/article/details/41209515?utm_source=tuicool&utm_medium=referral
通俗理解LDA主題模型
0 前言
印象中,最開始聽說“LDA”這個名詞,是緣於rickjin在2013年3月寫的一個LDA科普系列,叫LDA數學八卦,我當時一直想看來著,記得還列印過一次,但不知是因為這篇文件的前序鋪墊太長(現在才意識到這些“鋪墊”都是深刻理解LDA 的基礎,但如果沒有人幫助初學者提綱挈領、把握主次、理清思路,則很容易陷入LDA的細枝末節之中),還是因為其中的數學推導細節太多,導致一直沒有完整看完過。
2013年12月,在我組織的Machine Learning讀書會第8期上,@夏粉_百度 講機器學習中排序學習的理論和演算法研究,@沈醉2011 則講主題模型的理解。又一次碰到了主題模型,當時貌似只記得沈博講了一個汪峰寫歌詞的例子,依然沒有理解LDA到底是怎樣一個東西(但理解了LDA之後,再看沈博主題模型的PPT會很贊)。
直到昨日下午,機器學習班第12次課上,鄒博講完LDA之後,才真正明白LDA原來是那麼一個東東!上完課後,趁熱打鐵,再次看LDA數學八卦,發現以前看不下去的文件再看時竟然一路都比較順暢,一口氣看完大部。看完大部後,思路清晰了,知道理解LDA,可以分為下述5個步驟:
- 一個函式:gamma函式
- 四個分佈:二項分佈、多項分佈、beta分佈、Dirichlet分佈
- 一個概念和一個理念:共軛先驗和貝葉斯框架
- 兩個模型:pLSA、LDA(在本文第4 部分闡述)
- 一個取樣:Gibbs取樣
本文便按照上述5個步驟來闡述,希望讀者看完本文後,能對LDA有個儘量清晰完整的瞭解。同時,本文基於鄒博講LDA的PPT、rickjin的LDA數學八卦及其它參考資料寫就,可以定義為一篇學習筆記或課程筆記,當然,後續不斷加入了很多自己的理解。若有任何問題,歡迎隨時於本文評論下指出,thanks。
1 gamma函式
1.0 整體把握LDA
關於LDA有兩種含義,一種是線性判別分析(Linear Discriminant Analysis),一種是概率主題模型:隱含狄利克雷分佈(Latent Dirichlet Allocation,簡稱LDA),本文講後者(前者會在後面的部落格中闡述)。
另外,我先簡單說下LDA的整體思想,不然我怕你看了半天,鋪了太長的前奏,卻依然因沒見到LDA的影子而顯得“心浮氣躁”,導致不想再繼續看下去。所以,先給你吃一顆定心丸,明白整體框架後,咱們再一步步抽絲剝繭,展開來論述。
按照wiki上的介紹,LDA由Blei, David M.、Ng, Andrew Y.、Jordan於2003年提出,是一種主題模型,它可以將文件集 中每篇文件的主題以概率分佈的形式給出,從而通過分析一些文件抽取出它們的主題(分佈)出來後,便可以根據主題(分佈)進行主題聚類或文字分類。同時,它是一種典型的詞袋模型,即一篇文件是由一組詞構成,詞與詞之間沒有先後順序的關係。此外,一篇文件可以包含多個主題,文件中每一個詞都由其中的一個主題生成。
LDA的這三位作者在原始論文中給了一個簡單的例子。比如假設事先給定了這幾個主題:Arts、Budgets、Children、Education,然後通過學習的方式,獲取每個主題Topic對應的詞語。如下圖所示:
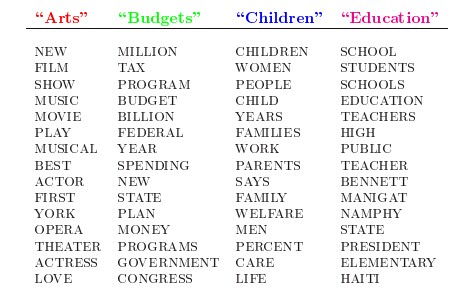
然後以一定的概率選取上述某個主題,再以一定的概率選取那個主題下的某個單詞,不斷的重複這兩步,最終生成如下圖所示的一篇文章(其中不同顏色的詞語分別對應上圖中不同主題下的詞):
而當我們看到一篇文章後,往往喜歡推測這篇文章是如何生成的,我們可能會認為作者先確定這篇文章的幾個主題,然後圍繞這幾個主題遣詞造句,表達成文。LDA就是要幹這事:根據給定的一篇文件,推測其主題分佈。 然,就是這麼一個看似普通的LDA,一度嚇退了不少想深入探究其內部原理的初學者。難在哪呢,難就難在LDA內部涉及到的數學知識點太多了。 在LDA模型中,一篇文件生成的方式如下:

- 從狄利克雷分佈
中取樣生成文件 i 的主題分佈
- 從主題的多項式分佈
中取樣生成文件i第 j 個詞的主題
- 從狄利克雷分佈
中取樣生成主題
對應的詞語分佈
- 從詞語的多項式分佈
中取樣最終生成詞語
其中,類似Beta分佈是二項式分佈的共軛先驗概率分佈,而狄利克雷分佈(Dirichlet分佈)是多項式分佈的共軛先驗概率分佈。
此外,LDA的圖模型結構如下圖所示(類似貝葉斯網路結構):
恩,不錯,短短6句話整體概括了整個LDA的主體思想!但也就是上面短短6句話,卻接連不斷或重複出現了二項分佈、多項式分佈、beta分佈、狄利克雷分佈(Dirichlet分佈)、共軛先驗概率分佈、取樣,那麼請問,這些都是啥呢?
這裡先簡單解釋下二項分佈、多項分佈、beta分佈、Dirichlet 分佈這4個分佈。
- 二項分佈(Binomial distribution)。
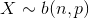 。簡言之,只做一次實驗,是伯努利分佈,重複做了n次,是二項分佈。二項分佈的概率密度函式為:
。簡言之,只做一次實驗,是伯努利分佈,重複做了n次,是二項分佈。二項分佈的概率密度函式為:
對於k = 0, 1, 2, ..., n,其中的
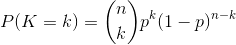
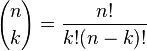 是二項式係數(這就是二項分佈的名稱的由來),又記為
是二項式係數(這就是二項分佈的名稱的由來),又記為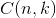 。回想起高中所學的那丁點概率知識了麼:想必你當年一定死記過這個二項式係數就是
。回想起高中所學的那丁點概率知識了麼:想必你當年一定死記過這個二項式係數就是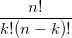 。
。
- 多項分佈,是二項分佈擴充套件到多維的情況。
多項分佈的概率密度函式為: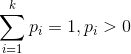
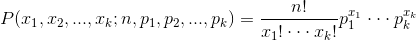
- Beta分佈,二項分佈的共軛先驗分佈。

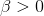 ,取值範圍為[0,1]的隨機變數
x 的概率密度函式
,取值範圍為[0,1]的隨機變數
x 的概率密度函式其中

注:,
。
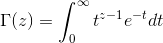
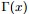 便是所謂的gamma函式,下文會具體闡述。
便是所謂的gamma函式,下文會具體闡述。
- Dirichlet分佈,是beta分佈在高維度上的推廣。
其中
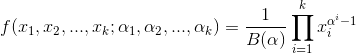
至此,我們可以看到二項分佈和多項分佈很相似,Beta分佈和Dirichlet 分佈很相似,而至於“Beta分佈是二項式分佈的共軛先驗概率分佈,而狄利克雷分佈(Dirichlet分佈)是多項式分佈的共軛先驗概率分佈”這點在下文中說明。
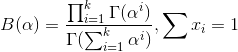
OK,接下來,咱們就按照本文開頭所說的思路:“一個函式:gamma函式,四個分佈:二項分佈、多項分佈、beta分佈、Dirichlet分佈,外加一個概念和一個理念:共軛先驗和貝葉斯框架,兩個模型:pLSA、LDA(文件-主題,主題-詞語),一個取樣:Gibbs取樣”一步步詳細闡述,爭取給讀者一個儘量清晰完整的LDA。
(當然,如果你不想深究背後的細節原理,只想整體把握LDA的主體思想,可直接跳到本文第4 部分,看完第4部分後,若還是想深究背後的細節原理,可再回到此處開始看)
1.1 gamma函式
咱們先來考慮一個問題(此問題1包括下文的問題2-問題4皆取材自LDA數學八卦):
- 問題1 隨機變數
- 把這n 個隨機變數排序後得到順序統計量
- 然後請問
的分佈是什麼。
為解決這個問題,可以嘗試計算
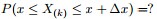
首先,把 [0,1] 區間分成三段 [0,x),[x,x+Δx],(x+Δx,1],然後考慮下簡單的情形:即假設n 個數中只有1個落在了區間 [x,x+Δx]內,由於這個區間內的數X(k)是第k大的,所以[0,x)中應該有 k−1 個數,(x+Δx,1] 這個區間中應該有n−k 個數。如下圖所示:
從而問題轉換為下述事件E:
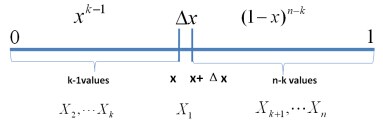
對於上述事件E,有:
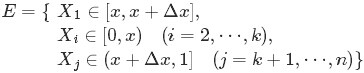
其中,o(Δx)表示Δx的高階無窮小。顯然,由於不同的排列組合,即n個數中有一個落在 [x,x+Δx]區間的有n種取法,餘下n−1個數中有k−1個落在[0,x)的有
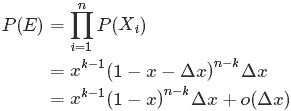
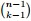 種組合,所以和事件E等價的事件一共有
種組合,所以和事件E等價的事件一共有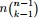 個。
如果有2個數落在區間[x,x+Δx]呢?如下圖所示:
個。
如果有2個數落在區間[x,x+Δx]呢?如下圖所示:
類似於事件E,對於2個數落在區間[x,x+Δx]的事件E’:
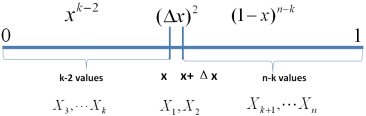
有:
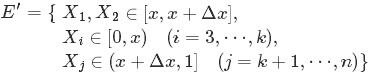
從上述的事件E、事件E‘中,可以看出,只要落在[x,x+Δx]內的數字超過一個,則對應的事件的概率就是 o(Δx)。於是乎有:
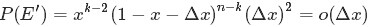
從而得到
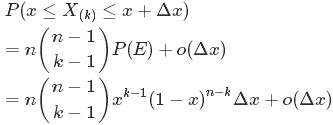 的概率密度函式
的概率密度函式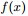 為:
為:
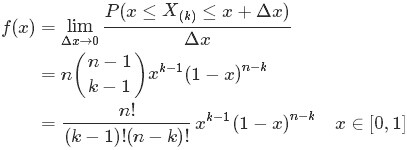
至此,本節開頭提出的問題得到解決。然仔細觀察
兩者結合是否會產生奇妙的效果呢?考慮到
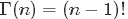
故將代入到
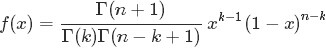
然後取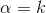
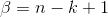
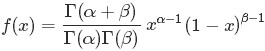
如果熟悉beta分佈的朋友,可能會驚呼:哇,竟然推出了beta分佈!
2 beta分佈
2.1 beta分佈
在概率論中,beta是指一組定義在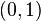 區間的連續概率分佈,有兩個引數
區間的連續概率分佈,有兩個引數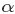 和
和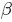 ,且
,且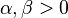 。
beta分佈的概率密度函式是:
。
beta分佈的概率密度函式是:
其中的
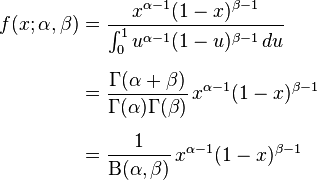
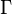 便是函式:
便是函式:
隨機變數X服從引數為
 的beta分佈通常寫作:
的beta分佈通常寫作: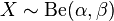 。
。
2.2 Beta-Binomial 共軛
回顧下1.1節開頭所提出的問題:“問題1 隨機變數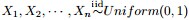 ,把這n 個隨機變數排序後得到順序統計量
,把這n 個隨機變數排序後得到順序統計量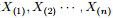 ,然後請問的分佈是什麼。”
如果,咱們要在這個問題的基礎上增加一些觀測資料,變成問題2:
,然後請問的分佈是什麼。”
如果,咱們要在這個問題的基礎上增加一些觀測資料,變成問題2:
;
,
中有
個比p小,
個比
大;
- 那麼,請問
的分佈是什麼。
個比小,個比大”,換言之,Yi中有個比小,個比大,所以是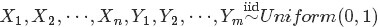 中第
中第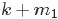 大的數。
根據1.1節最終得到的結論“只要落在[x,x+Δx]內的數字超過一個,則對應的事件的概率就是 o(Δx)”,繼而推出事件服從beta分佈,從而可知的概率密度函式為:
大的數。
根據1.1節最終得到的結論“只要落在[x,x+Δx]內的數字超過一個,則對應的事件的概率就是 o(Δx)”,繼而推出事件服從beta分佈,從而可知的概率密度函式為:
熟悉貝葉斯方法(不熟悉的沒事,參見此文第一部分)的朋友心裡估計又犯“嘀咕”了,這不就是貝葉斯式的思考過程麼?
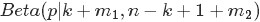
- 為了猜測
,此稱為
- 然後為了獲得這個結果“