
python使用requests包爬取Pixiv圖片--關注畫師的所有作品
最近學了點python,想著做點實際任務來練練手,各種競賽網站的題又都太難了,目前只是學了點皮毛,實際碼點程式碼鞏固語法而已,python只是順便學一學,感覺確實是一門很。。很。。厲害!的語言,相比matlab感覺更像在程式設計,相比C++又簡單很多,不用考慮太多細節的東西,好用的庫一大堆。
好了,廢話不多說,詳細講一講爬P站過程中的那些坑。
網上各種爬蟲教程很多,例子也很多,大多數三次元的網站都被現充們爬完了,也有很多坑的總結帖,但是搜尋P站的相關文章確實太少了,而且這種東西更新地太快了,一開始找了篇今年4月份的部落格,很多都已經不適用了,還得靠自己啊~~
首先看登入過程,畢竟P站也是一個比較大型的二次元交友?網站,登入還是需要的,不過雖然登入介面沒有驗證碼,但是它在POST資訊中有一個post_key用來驗證,一開始在這由於參考前人的程式碼,沒有考慮到post_key,可能也就最近才加上這一層為了更加安全?確實浪費了我很多時間,整整一晚上,差點放棄了。。所以在下面模擬登入是不能只給賬號密碼,還有一個動態的post_key,思路就是用session來記錄這一次會話的post_key,以及後面登入的cookies。程式碼如下。
baseurl就是這個頁面,注意P站的登入介面特別慢,不過登陸進去就好了,監控登入的nework的時候真的是急死我了
此時F12檢視network情況,勾選preserve log(不然登入介面跳轉後原來的POST資訊就沒了),點選登陸後可以發現瀏覽器向伺服器傳送了POST的請求,開啟這個POST看一下,
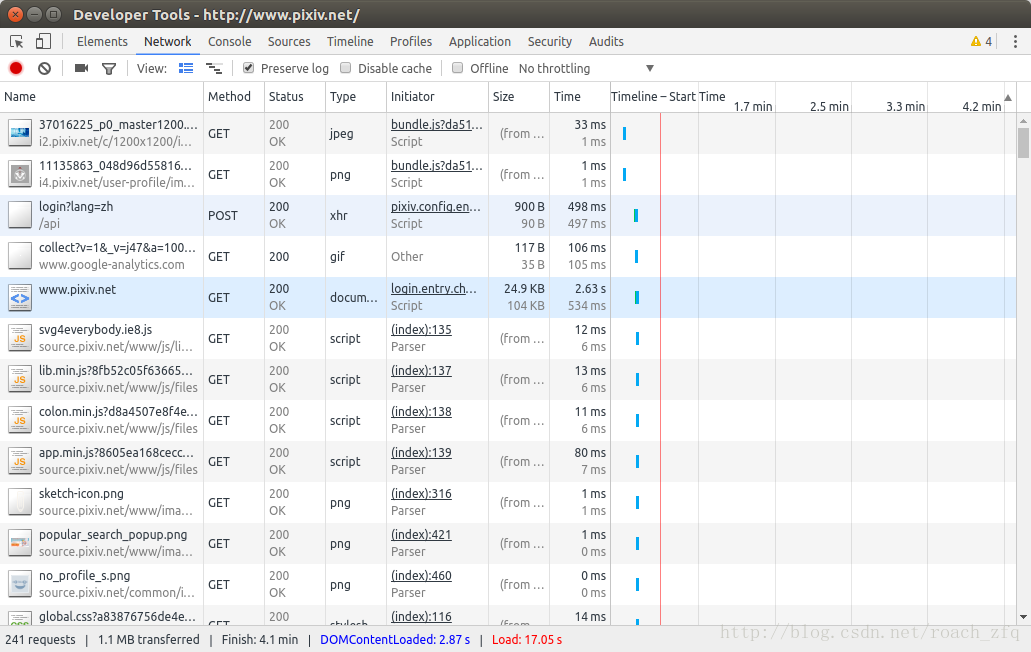
我們就模擬這個Form data來post自己的資訊,模擬登陸,程式碼如下:
def __init__(self):
self.baseUrl = "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index"
self.LoginUrl = "https://accounts.pixiv.net/api/login?lang=zh"
self.firstPageUrl = 'http://www.pixiv.net/member_illust.php?id=7210261&type=all'
self.loginHeader = {
'Host': "accounts.pixiv.net",
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36",
'Referer': "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Connection': "keep-alive"
}
self.return_to = "http://www.pixiv.net/"
self.pixiv_id = ' 後面的話其實就和平常的爬蟲程式碼差不多了,分析網頁,獲取圖片源地址,下載到本地,因為這一次只是一個嘗試的過程,所以選取的任務比較簡單,就是爬取關注的千葉大大@千葉QY3的所有作品,其實一開始想爬Miku標籤下所有高贊作品的,過兩天嘗試了一下也實現了python使用requests和BeautifulSoup包爬取Pixiv圖片--指定tag下的所有作品
然後開始碼程式碼吧,我這裡用的是requests包,感覺比urllib2+cookielib的方式確實簡單很多。
#獲取每頁每一張圖片的詳細頁面地址,總共11頁作品
def getImgDetailPage(self, pageHtml):
pattern = re.compile('<li class="image-item.*?<a href="(.*?)" class="work _work.*?</a>', re.S)
imgPageUrls = re.findall(pattern, pageHtml)
return imgPageUrls #開啟圖片詳細頁面,獲得圖片對應的最大解析度圖片
def getImg(self, pageUrls):
#查詢本頁面內最大解析度的圖片的url的正則表示式
pattern = re.compile('<div class="_illust_modal.*?<img alt="(.*?)".*?data-src="(.*?)".*?</div>', re.S)
for pageUrl in pageUrls:
#之前查詢得到的只是圖片頁面的半截url,這裡加上字首使之完整
wholePageUrl = 'http://www.pixiv.net' + str(pageUrl)
pageHtml = s.get(wholePageUrl).text
result = re.search(pattern, pageHtml) #如果這個頁面只有一張圖片,那就返回那張圖片的url和名字,如果是多張圖片 那就找不到返回none
if(result):
imgName = result.group(1)
imgSourceUrl = result.group(2)
print u'這個地址含有1張圖片,地址:' + wholePageUrl
print u'正在獲取第1張圖片.....'
print u'名字: ' + result.group(1)
print u'源地址:' + result.group(2)
self.getBigImg(imgSourceUrl, wholePageUrl, imgName)
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
self.getMultipleImg(wholePageUrl) #否則執行多張圖片時的特殊處理方法
另外還要注意有的一個作品它有好幾張,但有的你點開它不止一張,這種的html和單張圖片的不怎麼一樣,需要重新分析並提取地址,相當於在那個圖片詳情頁面的地址再多點一次才能提取到想要的最大解析度圖片的url,這裡也花了很長時間,我的程式碼如下,可以參考python爬蟲學習--pixiv爬蟲(2)--國際排行榜的圖片爬取,裡面的對P站三種不同圖片(單圖,多圖,動圖)的處理方法,比我不知高到哪去了,後悔沒有一開始看到他的解決方法。不過算了一下,感覺複雜度都是差不多的,畢竟就這麼幾行程式碼,不過那篇部落格的程式碼確實更優秀,值得學習。
#多張圖片的處理方法
def getMultipleImg(self, wholePageUrl):
imgAlmostSourceUrl = str(wholePageUrl).replace("medium", "manga")
header = {
'Referer': imgAlmostSourceUrl,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
pageHtml = s.get(imgAlmostSourceUrl, headers = header).text
totalNumPattern = re.compile('<span class="total">(\d)</span></div>', re.S) #找到這一頁共有幾張圖
totalNum = re.search(totalNumPattern, pageHtml)
#運行了一段時間報錯,因為動圖這裡處理不了,實在沒精力了,暫時不抓動圖了吧。。。
if (totalNum):
print u'這個地址含有' + totalNum.group(1) + u'張圖片,轉換後的地址:' + str(imgAlmostSourceUrl)
urlPattern = re.compile('<div class="item-container.*?<img src=".*?".*?data-src="(.*?)".*?</div>', re.S)
namePattern = re.compile('<section class="thumbnail-container.*?<a href="/member_illust.*?>(.*?)</a>', re.S)
urlResult = re.findall(urlPattern, pageHtml)
nameResult = re.search(namePattern, pageHtml)
for index,item in enumerate(urlResult):
print u'正在獲取第' + str(index + 1) + u'張圖片......'
print u'名字: ' + nameResult.group(1) + str(index + 1)
print u'源地址:' + item
self.getBigImg(item, wholePageUrl, nameResult.group(1)+str(index + 1))
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
print u'這個網址是一個gif,實在沒精力去研究怎麼儲存動圖了。。跳過吧'
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
#下載指定url的圖片
def getBigImg(self, sourceUrl, wholePageUrl, name):
header = {
'Referer': wholePageUrl, #這個referer必須要,不然get不到這個圖片,會報403Forbidden,具體機制也不是很清楚,可能也和cookies之類的有關吧
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
img = s.get(sourceUrl, headers = header)
f = open(name + '.jpg', 'wb') #寫入多媒體檔案要 b 這個引數
f.write(img.content) #多媒體檔案要是用conctent
f.close()
#輸入資料夾名,建立資料夾
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
if not isExists:
print u'建了一個名字叫做' + path + u'的資料夾!'
os.makedirs(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
return True
else:
print u'名字叫做' + path + u'的資料夾已經存在了!'
return False關於如何獲取下一頁作品的html,因為在第一頁html中沒有找打總共有多少頁,所以只能用while迴圈來判斷獲取頁面上下一頁按鈕得到的url是否為空來結束,不過後來在其他部落格裡看到第一頁可以獲取總共作品的數量,然後每一頁20個,用總數量除以20向上取整就得到總頁數了,這個方法也是可行的。這裡先把獲取每一頁上的圖片註釋掉,測試一下我的方法能否正常工作,如下:
#輸入資料夾名,建立資料夾
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
if not isExists:
print u'建了一個名字叫做' + path + u'的資料夾!'
os.makedirs(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
return True
else:
print u'名字叫做' + path + u'的資料夾已經存在了!'
return False
def start(self):
pathName = 'images'
self.mkdir(pathName) #呼叫mkdir函式建立資料夾!這兒path是資料夾名
os.chdir(pathName) #切換到目錄
self.getPostKey() #獲得此次會話的post_key
firstPageHtml = self.getPageAfterLogin() #從第一頁url開始
imgPageUrls = self.getImgDetailPage(firstPageHtml) #獲取第一頁所有圖片url
# self.getImg(imgPageUrls) #獲取第一頁所有圖片url所指向頁面的一張或多張圖片
currentPageUrl = self.getNextUrl(firstPageHtml)
while(currentPageUrl):
print currentPageUrl
currentPageHtml = self.getPageWithUrl(currentPageUrl)
imgPageUrls = self.getImgDetailPage(currentPageHtml)
# self.getImg(imgPageUrls)
currentPageUrl = self.getNextUrl(currentPageHtml)
p = Pixiv()
p.start()
執行結果:
說明這種方法還是可行的。
下面整理一下,貼上完整的,並執行
# -*- coding:utf-8 -*-
#created by zfq
#first edited: 2016.12.08
import requests
import re
import os
s = requests.Session()
class Pixiv:
def __init__(self):
self.baseUrl = "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index"
self.LoginUrl = "https://accounts.pixiv.net/api/login?lang=zh"
self.firstPageUrl = 'http://www.pixiv.net/member_illust.php?id=7210261&type=all'
self.loginHeader = {
'Host': "accounts.pixiv.net",
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36",
'Referer': "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Connection': "keep-alive"
}
self.return_to = "http://www.pixiv.net/"
self.pixiv_id = '7xxxxxxxx.com',
self.password = 'xxxxxxx'
self.postKey = []
#獲取此次session的post_key
def getPostKey(self):
loginHtml = s.get(self.baseUrl)
pattern = re.compile('<input type="hidden".*?value="(.*?)">', re.S)
result = re.search(pattern, loginHtml.text)
self.postKey = result.group(1)
#獲取登陸後的頁面
def getPageAfterLogin(self):
loginData = {"pixiv_id": self.pixiv_id, "password": self.password, 'post_key': self.postKey, 'return_to': self.return_to}
s.post(self.LoginUrl, data = loginData, headers = self.loginHeader)
targetHtml = s.get(self.firstPageUrl)
return targetHtml.text
#獲取頁面
def getPageWithUrl(self, url):
return s.get(url).text
#獲取下一頁url
def getNextUrl(self, pageHtml):
pattern = re.compile('<ul class="page-list.*?<span class="next.*?href="(.*?)" rel="next"', re.S)
url = re.search(pattern, pageHtml)
if url:
#如果存在,則返回url
nextUrl = 'http://www.pixiv.net/member_illust.php' + str(url.group(1))
return nextUrl
else:
return None
#獲取每一頁每一張圖片的詳細頁面地址
def getImgDetailPage(self, pageHtml):
pattern = re.compile('<li class="image-item.*?<a href="(.*?)" class="work _work.*?</a>', re.S)
imgPageUrls = re.findall(pattern, pageHtml)
return imgPageUrls
#下載指定url的圖片
def getBigImg(self, sourceUrl, wholePageUrl, name):
header = {
'Referer': wholePageUrl,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
imgExist = os.path.exists('/home/zfq/workspace/Pixiv/QianYe/images/' + name + '.jpg')
if (imgExist):
print u'該圖片已經存在,不用再次儲存,跳過!'
else:
img = s.get(sourceUrl, headers = header)
f = open(name + '.jpg', 'wb') #寫入多媒體檔案要 b 這個引數
f.write(img.content) #多媒體檔案要是用conctent!
f.close()
#開啟圖片詳細頁面,獲得圖片對應的最大解析度圖片
def getImg(self, pageUrls):
#查詢本頁面內最大解析度的圖片的url的正則表示式
pattern = re.compile('<div class="_illust_modal.*?<img alt="(.*?)".*?data-src="(.*?)".*?</div>', re.S)
for pageUrl in pageUrls:
#之前查詢得到的只是圖片頁面的半截url,這裡加上字首使之完整
wholePageUrl = 'http://www.pixiv.net' + str(pageUrl)
pageHtml = self.getPageWithUrl(wholePageUrl)
result = re.search(pattern, pageHtml) #如果這個頁面只有一張圖片,那就返回那張圖片的url和名字,如果是多張圖片 那就找不到返回none
if(result):
imgName = result.group(1)
imgSourceUrl = result.group(2)
print u'這個地址含有1張圖片,地址:' + wholePageUrl
print u'正在獲取第1張圖片.....'
print u'名字: ' + result.group(1)
print u'源地址:' + result.group(2)
self.getBigImg(imgSourceUrl, wholePageUrl, imgName)
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
self.getMultipleImg(wholePageUrl) #否則執行多張圖片時的特殊處理方法
#多張圖片的處理方法
def getMultipleImg(self, wholePageUrl):
imgAlmostSourceUrl = str(wholePageUrl).replace("medium", "manga")
pageHtml = self.getPageWithUrl(imgAlmostSourceUrl)
totalNumPattern = re.compile('<span class="total">(\d)</span></div>', re.S) #找到這一頁共有幾張圖
totalNum = re.search(totalNumPattern, pageHtml)
#運行了一段時間報錯,因為動圖這裡處理不了,實在沒精力了,暫時不抓動圖了吧。。。
if (totalNum):
print u'這個地址含有' + totalNum.group(1) + u'張圖片,轉換後的地址:' + str(imgAlmostSourceUrl)
urlPattern = re.compile('<div class="item-container.*?<img src=".*?".*?data-src="(.*?)".*?</div>', re.S)
namePattern = re.compile('<section class="thumbnail-container.*?<a href="/member_illust.*?>(.*?)</a>', re.S)
urlResult = re.findall(urlPattern, pageHtml)
nameResult = re.search(namePattern, pageHtml)
for index,item in enumerate(urlResult):
print u'正在獲取第' + str(index + 1) + u'張圖片......'
print u'名字: ' + nameResult.group(1) + str(index + 1)
print u'源地址:' + item
self.getBigImg(item, wholePageUrl, nameResult.group(1)+str(index + 1))
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
print u'這個網址是一個gif,實在沒精力去研究怎麼儲存動圖了。。跳過吧'
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
#輸入資料夾名,建立資料夾
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
if not isExists:
print u'建了一個名字叫做' + path + u'的資料夾!'
os.makedirs(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
return True
else:
print u'名字叫做' + path + u'的資料夾已經存在了!'
return False
def start(self):
pathName = 'images'
self.mkdir(pathName) #呼叫mkdir函式建立資料夾!這兒path是資料夾名
os.chdir(pathName) #切換到目錄
self.getPostKey() #獲得此次會話的post_key
firstPageHtml = self.getPageAfterLogin() #從第一頁url開始
imgPageUrls = self.getImgDetailPage(firstPageHtml) #獲取第一頁所有圖片url
self.getImg(imgPageUrls) #獲取第一頁所有圖片url所指向頁面的一張或多張圖片
currentPageUrl = self.getNextUrl(firstPageHtml)
while(currentPageUrl):
currentPageHtml = self.getPageWithUrl(currentPageUrl)
imgPageUrls = self.getImgDetailPage(currentPageHtml)
self.getImg(imgPageUrls)
currentPageUrl = self.getNextUrl(currentPageHtml)
p = Pixiv()
p.start()
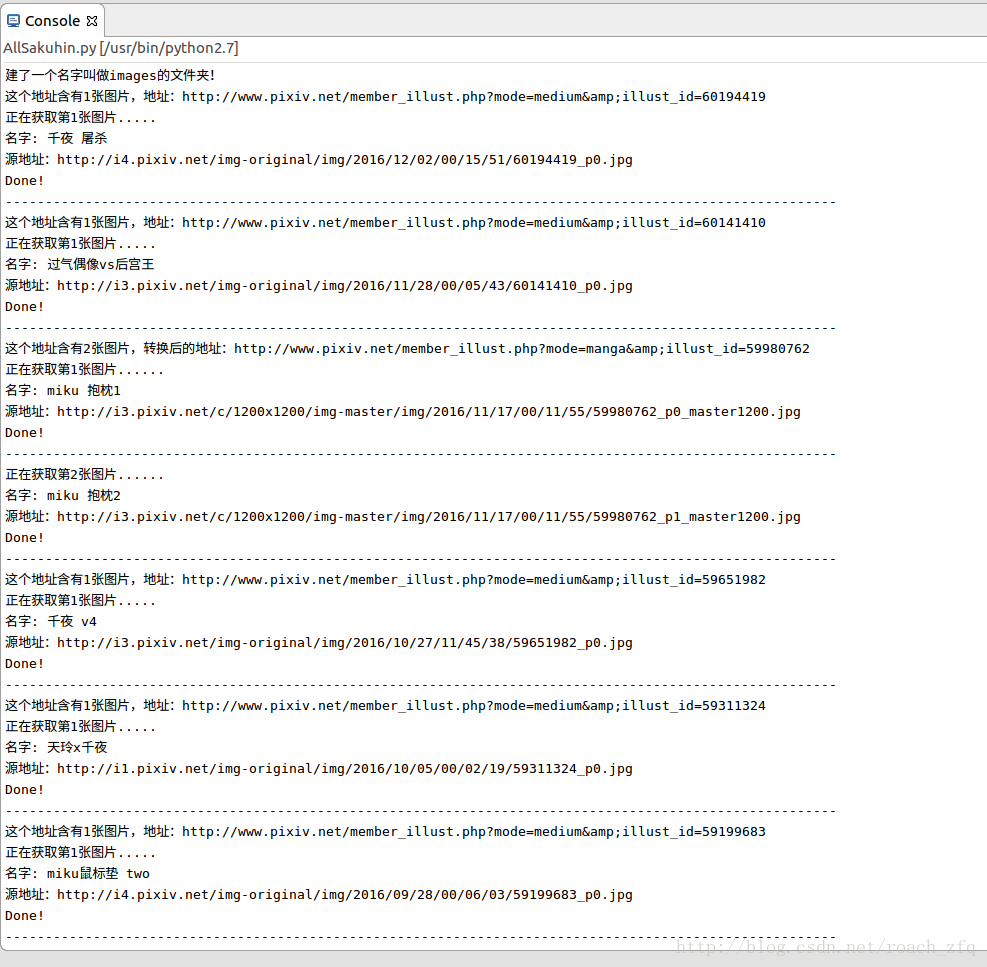
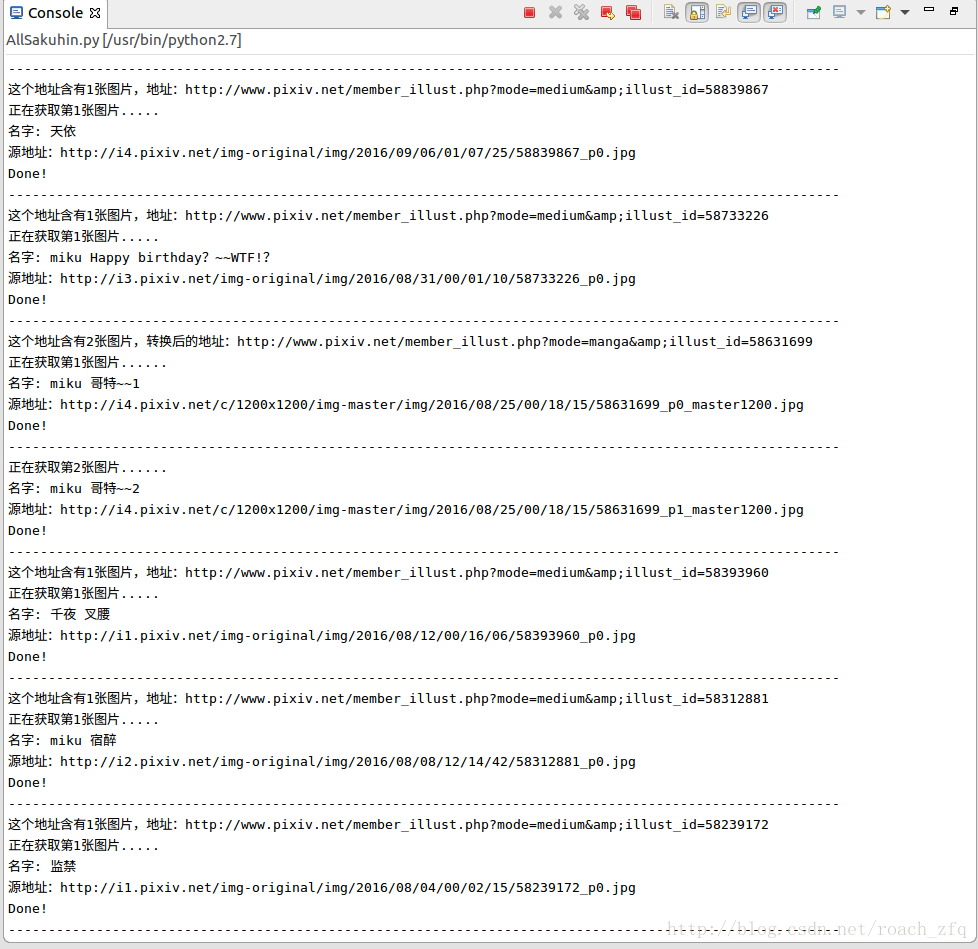
偶爾還會在某一張圖片卡很久,然後下載不全,可能也是因為網路的原因吧,像這樣:

它底下是空的,亂碼的。。這樣的還好幾張呢
最後看一下到目前的成果
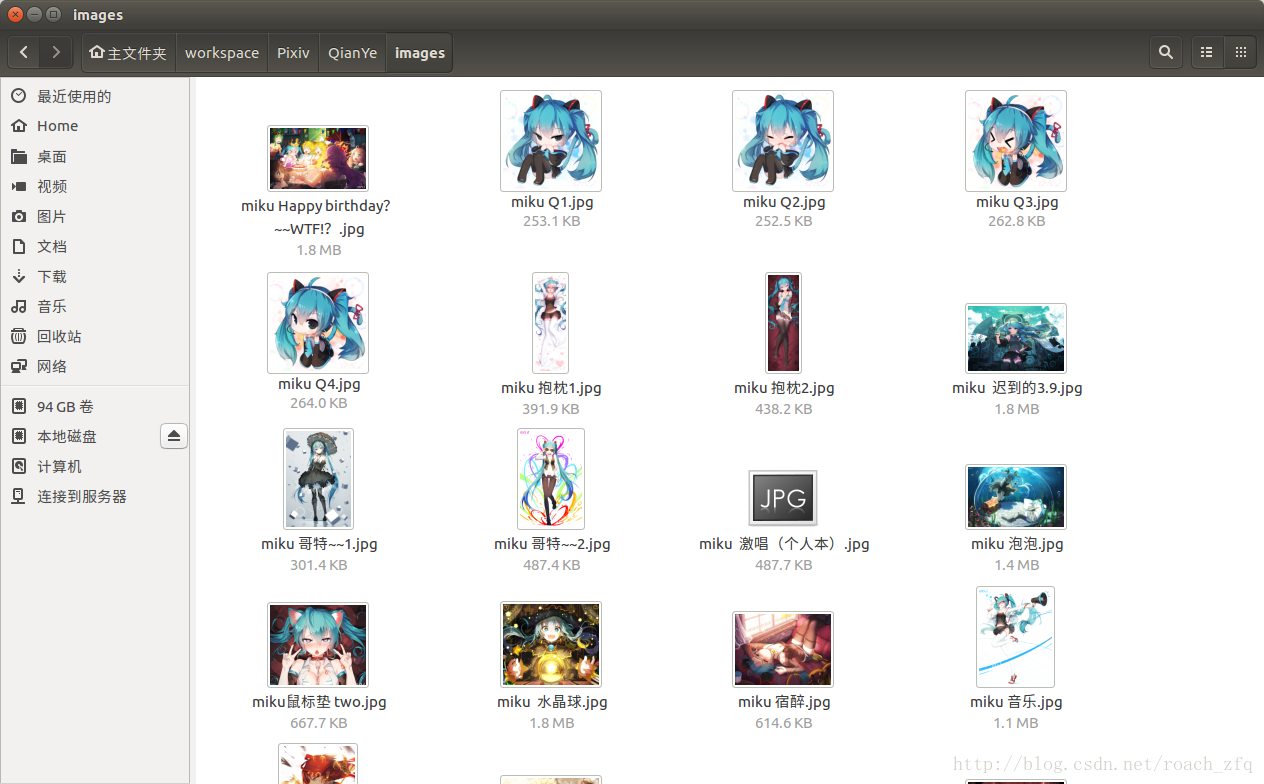
才30幾張,還有85%呢,讓它跑一夜吧,完了再來更新。
第二早發現執行到第3頁遇到第一個動圖獲取不了,於是添上了上面處理動圖的方法。
不過偶爾會get不到某個指定url的頁面,可能是P站的某種反爬蟲技術吧,限制IP訪問頻率?限制User-Agent?不過又很不確定,有時候可以get上百張突然報錯get不了,有時候才十幾張就不讓繼續get,也還是沒太多時間的原因,沒有太多精力去研究了,暫且就這樣吧,給它加了檢查是否已經下載過該圖片報錯下載過的話自動跳過的語句,這樣發生錯誤的話從錯誤的那一頁重新開始就好了(將firstPageUrl設為該頁的url)
這樣執行一會的話,有這樣的結果:
重新從某一頁開始獲取時:

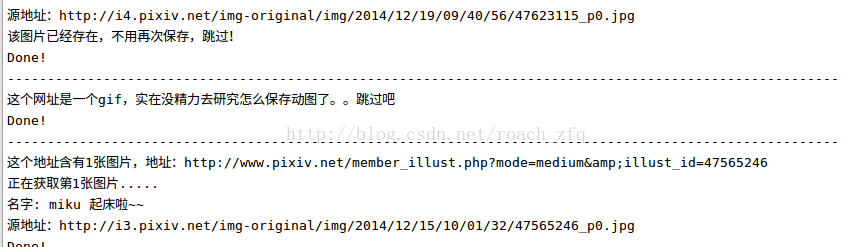
遇到gif是的情況:
不過當所有都get完了從第一頁再重新開始的時候,速度很快,刷刷刷的,大概用了3分鐘檢查完了所有11頁的內容,中間沒有任何阻礙,看來P站真的限制同一次會話get原圖的次數?,你不去get原圖只是依次check每一個原圖的url就完全沒問題。然後檢查結果就是全都已經存在不用再儲存,也順便把那幾張黑掉的圖 如下圖,刪掉重新get到了完整的,今早的網還不錯呢!>_<~~~
最後快結束時,get最後幾張圖片時的控制檯輸出:
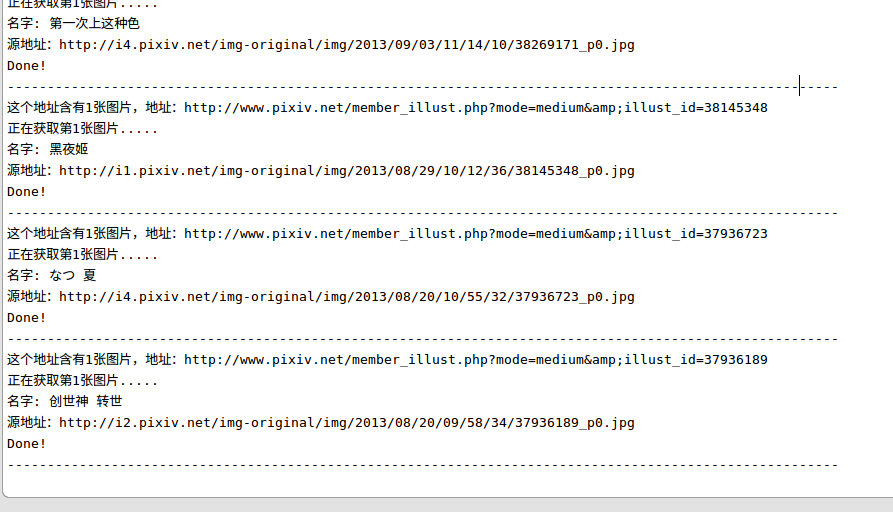
這就是最後一張啦!執行結束啦~
最後晒一下成果,總共219張圖片:
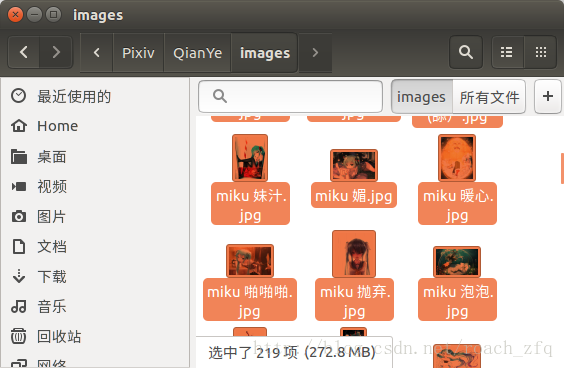
注意全都是高清大圖哦,每個1-2MB左右的,可以做桌面的那種,跟網頁上看到的那種小圖可不一樣。。
遺留問題:程式碼不穩定,每次執行不確定的迭代次數後直到self.getPageWithUrl(Url)報錯:requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",)),有時候可以直接執行到最後,get到所有的圖片,有時候get到50張,有時候30,有時候甚至才幾張就報錯,不過增加了判斷圖片是否存在機制後直接執行就好 會跳過已經下載好的,目前不太清楚具體原因,這個可能要很深入的學習才能理解吧。
最後來張V家眾人圖,完結\(≧▽≦)/~
