
聊聊Greenplum的那些事

開卷有益——作者的話
有時候真的感嘆人生歲月匆匆,特別是當一個IT人沉浸於某個技術領域十來年後,驀然回首,總有說不出的萬千感慨。
筆者有幸從04年就開始從事大規模資料計算的相關工作,08年作為Greenplum 早期員工加入Greenplum團隊(當時的工牌是“005”,哈哈),記得當時看了一眼Greenplum的架構(嗯,就是現在大家耳熟能詳的那個好多個X86框框的圖),就義無反顧地加入了,轉眼之間,已經到了第8個年頭。
在諸多專案中我親歷了Greenplum在國內的生根發芽到高速發展,再到現在擁有一百多個企業級使用者的過程。也見證了Greenplum從早期的2.1版本到當前的4.37版本,許多NB功能的不斷增強、系統穩定性的不斷大幅提高,在Greenplum的發展壯大中,IT行業也發生著巨大的變化,業界潮流沿著開放、開源的方向走向了大資料和雲端計算時代。由此看出,Greenplum十來年的快速發展不是偶然發生的,這與其在技術路線上始終保持與整個I

多年曆練中接觸過大大小小几十個資料類專案,有些淺嘗輒止(最短的不到一週甚至還有遠端支援),有些週期以年來計(長期出差現場、生不如死),客觀來說, 每個專案都有其獨一無二的的特點,只要有心,你總能在這個專案上學到些什麼或有所領悟。我覺得把這些整理一下,用隨筆的方式寫下來,除了自己備忘以外,也許會對大家更深入地去了解GP帶來一些啟發,也或許在某個技術點上是你目前遇到的問題,如亂碼怎麼載入?異構資料庫如何遷移?叢集間如何高速複製資料?如何用C API擴充套件實現高效備份恢復等。希望我的這篇文章能夠給大家帶來幫助,同時也希望大家多拍磚。
Greenplum的起源
Greenplum最早是在10多年前(大約在2002年)出現的,基本上和Hadoop是同一時期(Hadoop 約是2004年前後,早期的Nutch可追溯到2002年)。當時的背景是:
1
網際網路行業經過之前近10年的由慢到快的發展,累積了大量資訊和資料,資料在爆發式增長,這些海量資料急需新的計算方式,需要一場計算方式的革命;
2傳統的主機計算模式在海量資料面前,除了造價昂貴外,在技術上也難於滿足資料計算效能指標,傳統主機的Scale-up模式遇到了瓶頸,SMP(對稱多處理)架構難於擴充套件,並且在CPU計算和IO吞吐上不能滿足海量資料的計算需求;
3分散式儲存和分散式計算理論剛剛被提出來,Google的兩篇著名論文發表後引起業界的關注,一篇是關於GFS分散式檔案系統,另外一篇是關於MapReduce 平行計算框架的理論,分散式計算模式在網際網路行業特別是收索引擎和分詞檢索等方面獲得了巨大成功。
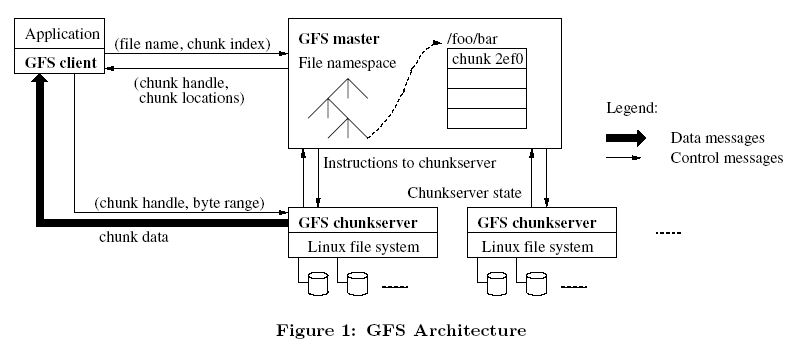
由此,業界認識到對於海量資料需要一種新的計算模式來支援,這種模式就是可以支援Scale-out橫向擴充套件的分散式並行資料計算技術。
當時,開放的X86伺服器技術已經能很好的支援商用,藉助高速網路(當時是千兆乙太網)組建的X86叢集在整體上提供的計算能力已大幅高於傳統SMP主機,並且成本很低,橫向的擴充套件性還可帶來系統良好的成長性。
問題來了,在X86叢集上實現自動的平行計算,無論是後來的MapReduce計算框架還是MPP(海量並行處理)計算框架,最終還是需要軟體來實現,Greenplum正是在這一背景下產生的,藉助於分散式計算思想,Greenplum實現了基於資料庫的分散式資料儲存和平行計算(GoogleMapReduce實現的是基於檔案的分散式資料儲存和計算,我們過後會比較這兩種方法的優劣性)。
話說當年Greenplum(當時還是一個Startup公司,創始人家門口有一棵青梅 ——greenplum,因此而得名)召集了十幾位業界大咖(據說來自google、yahoo、ibm和TD),說幹就幹,花了1年多的時間完成最初的版本設計和開發,用軟體實現了在開放X86平臺上的分散式平行計算,不依賴於任何專有硬體,達到的效能卻遠遠超過傳統高昂的專有系統。
大家都知道Greenplum的資料庫引擎層是基於著名的開源資料庫Postgresql的(下面會分析為什麼採用Postgresql,而不是mysql等等),但是Postgresql是單例項資料庫,怎麼能在多個X86伺服器上執行多個例項且實現平行計算呢?為了這,Interconnnect大神器出現了。在那1年多的時間裡,大拿們很大一部分精力都在不斷的設計、優化、開發Interconnect這個核心軟體元件。最終實現了對同一個叢集中多個Postgresql例項的高效協同和平行計算,interconnect承載了並行查詢計劃生產和Dispatch分發(QD)、協調節點上QE執行器的並行工作、負責資料分佈、Pipeline計算、映象複製、健康探測等等諸多工。
在Greenplum開源以前,據說一些廠商也有開發MPP資料庫的打算,其中最難的部分就是在Interconnect上遇到了障礙,可見這項技術的關鍵性。
Greenplum為什麼選擇Postgreeql做輪子
說到這,也許有同學會問,為什麼Greenplum 要基於Postgresql? 這個問題大致引申出兩個問題:
1、為什麼不從資料庫底層進行重新設計研發?
道理比較簡單,所謂術業有專攻,就像製造跑車的不會親自生產車輪一樣,我們只要專注在分散式技術中最核心的並行處理技術上面,協調我們下面的輪子跑的更快更穩才是我們的最終目標。而資料庫底層元件就像車輪一樣,經過幾十年磨礪,資料庫引擎技術已經非常成熟,大可不必去重新設計開發,而且把資料庫底層交給其它專業化組織來開發(對應到Postgresql就是社群),還可充分利用到社群的源源不斷的創新能力和資源,讓產品保持持續旺盛的生命力。
這也是我們在使用者選型時,通常建議使用者考察一下底層的技術支撐是不是有好的組織和社群支援的原因,如果缺乏這方面的有力支援或獨自閉門造輪,那就有理由為那個車的前途感到擔憂,一個簡單判斷的標準就是看看底下那個輪子有多少人使用,有多少人為它貢獻力量。
2、為什麼是Postgresql而不是其它的?
我想大家可能主要想問為什麼是Postgresql而不是Mysql(對不起,還有很多開源關係型資料庫,但相比這兩個主流開源庫,但和這兩個大牛比起來,實在不在一個起跑線上)。本文無意去從詳細技術點上PK這兩個資料庫孰優孰劣(網上很多比較),我相信它們的存在都有各自的特點,它們都有成熟的開源社群做支援,有各自的龐大的fans群眾基礎。個人之見,Greenplum選擇Postgressql有以下考慮:
1)Postgresql號稱最先進的資料庫(官方主頁“The world’s most advanced open source database”),且不管這是不是自我標榜,就從OLAP分析型方面來考察,以下幾點Postgresql確實勝出一籌:
1
PG有非常強大 SQL 支援能力和非常豐富的統計函式和統計語法支援,除對ANSI SQL完全支援外,還支援比如分析函式(SQL2003 OLAP window函式),還可以用多種語言來寫儲存過程,對於Madlib、R的支援也很好。這一點上MYSQL就差的很遠,很多分析功能都不支援,而Greenplum作為MPP資料分析平臺,這些功能都是必不可少的。
2Mysql查詢優化器對於子查詢、複製查詢如多表關聯、外關聯的支援等較弱,特別是在關聯時對於三大join技術:hash join、merge join、nestloop join的支援方面,Mysql只支援最後一種nestloop join(據說未來會支援hash join),而多個大表關聯分析時hash join是必備的利器,缺少這些關鍵功能非常致命,將難於在OLAP領域充當大任。我們最近對基於MYSQL的某記憶體分散式資料庫做對比測試時,發現其優點是OLTP非常快,TPS非常高(輕鬆搞定幾十萬),但一到複雜多表關聯效能就立馬下降,即使其具有記憶體計算的功能也無能為力,就其因估計還是受到mysql在這方面限制。
2)擴充套件性方面,Postgresql比mysql也要出色許多,Postgres天生就是為擴充套件而生的,你可以在PG中用Python、C、Perl、TCL、PLSQL等等語言來擴充套件功能,在後續章節中,我將展現這種擴充套件是如何的方便,另外,開發新的功能模組、新的資料型別、新的索引型別等等非常方便,只要按照API介面開發,無需對PG重新編譯。PG中contrib目錄下的各個第三方模組,在GP中的postgis空間資料庫、R、Madlib、pgcrypto各類加密演算法、gptext全文檢索都是通過這種方式實現功能擴充套件的。
3)在諸如ACID事物處理、資料強一致性保證、資料型別支援、獨特的MVCC帶來高效資料更新能力等還有很多方面,Postgresql似乎在這些OLAP功能上都比mysql更甚一籌。
4)最後,Postgresql許可是仿照BSD許可模式的,沒有被大公司控制,社群比較純潔,版本和路線控制非常好,基於Postgresql可讓使用者擁有更多自主性。反觀Mysql的社群現狀和眾多分支(如MariaDB),確實夠亂的。
好吧,不再過多列舉了,這些特點已經足夠了,據說很多網際網路公司採用Mysql來做OLTP的同時,卻採用Postgresql來做內部的OLAP分析資料庫,甚至對新的OLTP系統也直接採用Postgresql。
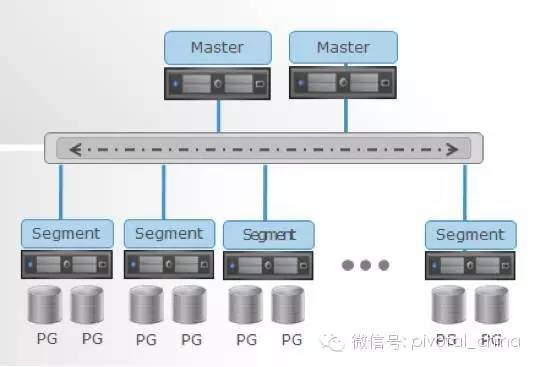
相比之下,Greenplum更強悍,把Postgresql作為例項(注:該例項非Oracle例項概念,這裡指的是一個分散式子庫)架構在Interconnect下,在Interconnect的指揮協調下,數十個甚至數千個Sub Postgresql資料庫例項同時開展平行計算,而且,這些Postgresql之間採用share-nothing無共享架構,從而更將這種平行計算能力發揮到極致。
除此之外,MPP採用兩階段提交和全域性事務管理機制來保證叢集上分散式事務的一致性,Greenplum像Postgresql一樣滿足關係型資料庫的包括ACID在內的所有特徵。
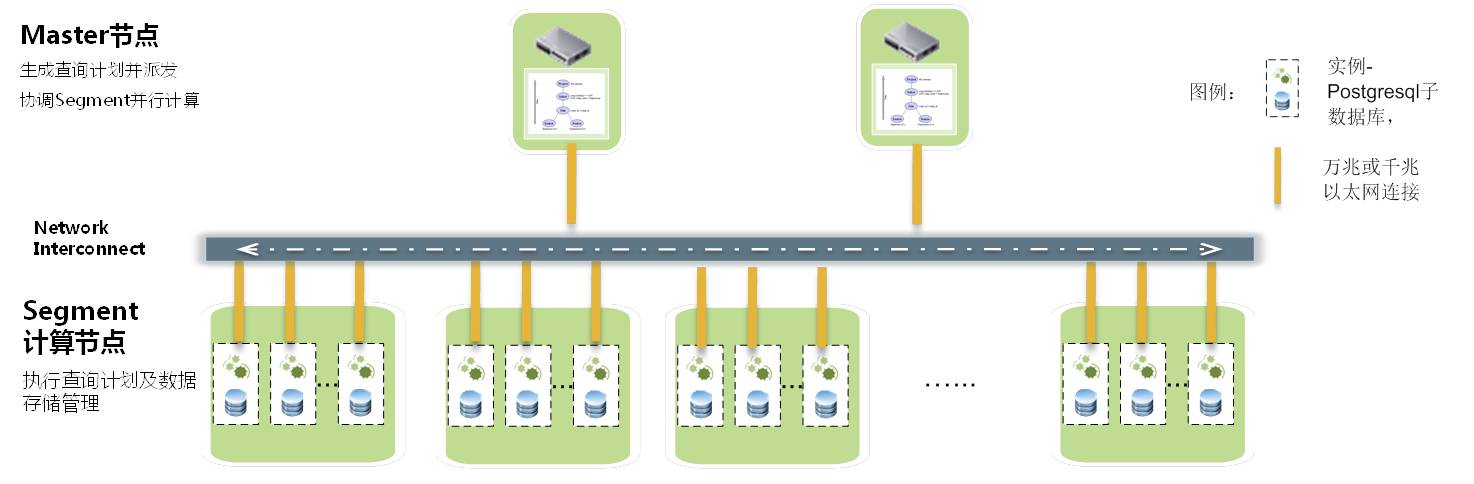
從上圖進而可以看到,Greenplum的最小並行單元不是節點層級,而是在例項層級,安裝過Greenplum的同學應該都看到每個例項都有自己的postgresql目錄結構,都有各自的一套Postgresql資料庫守護程序(甚至可以通過UT模式進行單個例項的訪問)。正因為如此,甚至一個執行在單節點上的GreenplumDB也是一個小型的平行計算架構,一般一個節點配置6~8個例項,相當於在一個節點上有6~8個Postgresql資料庫同時並行工作,優勢在於可以充分利用到每個節點的所有CPU和IO 能力。
Greenplum單個節點上執行能力比其它資料庫也快很多,如果執行在多節點上,其提供效能幾乎是線性的增長,這樣一個叢集提供的效能能夠很輕易的達到傳統資料庫的數百倍甚至數千倍,所管理資料儲存規模達到100TB~數PB,而你在硬體上的投入,僅僅是數臺一般的X86伺服器和普通的萬兆交換機。
Greenplum採用Postgresl作為底層引擎,良好的相容了Postgresql的功能,Postgresql中的功能模組和介面基本上99%都可以在Greenplum上使用,例如odbc、jdbc、oledb、perldbi、python psycopg2等,所以Greenplum與第三方工具、BI報表整合的時候非常容易;對於postgresql的contrib中的一些常用模組Greenplum提供了編譯後的模組開箱即用,如oraface、postgis、pgcrypt等,對於其它模組,使用者可以自行將contrib下的程式碼與Greenplum的include標頭檔案編譯後,將動態so庫檔案部署到所有節點就可進行測試使用了。有些模組還是非常好用的,例如oraface,基本上集成了Oracle常用的函式到Greenplum中,曾經在一次PoC測試中,使用者提供的22條Oracle SQL語句,不做任何改動就能執行在Greenplum上。
最後特別提示,Greenplum絕不僅僅只是簡單的等同於“Postgresql+interconnect並行排程+分散式事務兩階段提交”,Greenplum還研發了非常多的高階資料分析管理功能和企業級管理模組,這些功能都是Postgresql沒有提供的:
-
外部表並行資料載入
-
可更新資料壓縮表
-
行、列混合儲存
-
資料表多級分割槽
-
Bitmap索引
-
Hadoop外部表
-
Gptext全文檢索
-
並行查詢計劃優化器和Orca優化器
-
Primary/Mirror映象保護機制
-
資源佇列管理
-
WEB/Brower監控
Greenplum的藝術,一切皆並行(Parallel Everything)
前面介紹了Greenplum的分散式平行計算架構,其中每個節點上所有Postgresql例項都是並行工作的,這種並行的Style貫穿了Greenplum功能設計的方方面面:外部表資料載入是並行的、查詢計劃執行是並行的、索引的建立和使用是並行的,統計資訊收集是並行的、表關聯(包括其中的重分佈或廣播及關聯計算)是並行的,排序和分組聚合都是並行的,備份恢復也是並行的,甚而資料庫啟停和元資料檢查等維護工具也按照並行方式來設計,得益於這種無所不在的並行,Greenplum在資料載入和資料計算中表現出強悍的效能,某行業客戶深有體會:同樣2TB左右的資料,在Greenplum中不到一個小時就載入完成了,而在使用者傳統資料倉庫平臺上耗時半天以上。
在該使用者的生產環境中,1個數百億表和2個10多億條記錄表的全表關聯中(只有on關聯條件,不帶where過濾條件,其中一個10億條的表計算中需要重分佈),Greenplum僅耗時數分鐘就完成了,當其它傳統資料平臺還在為千萬級或億級規模的表關聯效能發愁時,Greenplum已經一騎絕塵,在百億級規模以上表關聯中展示出上佳的表現。
Greenplum建立在Share-nothing無共享架構上,讓每一顆CPU和每一塊磁碟IO都運轉起來,無共享架構將這種並行處理髮揮到極致。相比一些其它傳統資料倉庫的Sharedisk架構,後者最大瓶頸就是在IO吞吐上,在大規模資料處理時,IO無法及時feed資料給到CPU,CPU資源處於wait 空轉狀態,無法充分利用系統資源,導致SQL效率低下:
一臺內建16塊SAS盤的X86伺服器,每秒的IO資料掃描效能約在2000MB/s左右,可以想象,20臺這樣的伺服器構成的機群IO效能是40GB/s,這樣超大的IO吞吐是傳統的 Storage難以達到的。
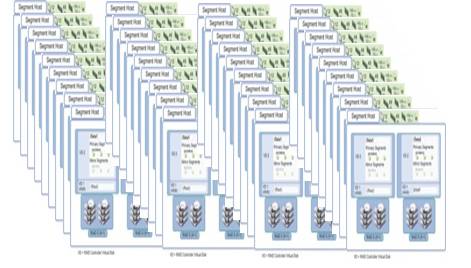
(MPP Share-nothing架構實現超大IO吞吐能力)
另外,Greenplum還是建立在例項級別上的平行計算,可在一次SQL請求中利用到每個節點上的多個CPU CORE的計算能力,對X86的CPU超執行緒有很好的支援,提供更好的請求響應速度。在PoC中接觸到其它一些國內外基於開放平臺的MPP軟體,大都是建立在節點級的並行,單個或少量的任務時無法充分利用資源,導致系統載入和SQL執行效能不高。
記憶較深的一次PoC公開測試中,有廠商要求在測試中關閉CPU超執行緒,估計和這個原因有關(因為沒有辦法利用到多個CPU core的計算能力,還不如關掉超執行緒以提高單core的能力),但即使是這樣,在那個測試中,測試效能也大幅低於Greenplum(那個測試中,各廠商基於客戶提供的完全相同的硬體環境,Greenplum是唯一一家完成所有測試的,特別在混合負載測試中,Greenplum的80併發耗時3個多小時就成功完成了,其它廠商大都沒有完成此項測試,唯一完成的一家耗時40多小時)
前文提到,得益於Postgresql的良好擴充套件性(這裡是extension,不是scalability),Greenplum 可以採用各種開發語言來擴充套件使用者自定義函式(UDF)(我個人是Python和C的fans,後續章節與大家分享)。這些自定義函式部署到Greenplum後可用充分享受到例項級別的並行效能優勢,我們強烈建議使用者將庫外的處理邏輯,部署到用MPP資料庫的UDF這種In-Database的方式來處理,你將獲得意想不到的效能和方便性;例如我們在某客戶實現的資料轉碼、資料脫敏等,只需要簡單的改寫原有程式碼後部署到GP中,通過平行計算獲得數十倍效能提高。
另外,GPTEXT(lucent全文檢索)、Apache Madlib(開源挖掘演算法)、SAS algorithm、R都是通過UDF方式實現在Greenplum叢集中分散式部署,從而獲得庫內計算的並行能力。這裡可以分享的是,SAS曾經做過測試,對1億條記錄做邏輯迴歸,採用一臺小型機耗時約4個多小時,通過部署到Greenplum叢集中,耗時不到2分鐘就全部完成了。以GPEXT為例,下圖展現了Solr全文檢索在Greenplum中的並行化風格。
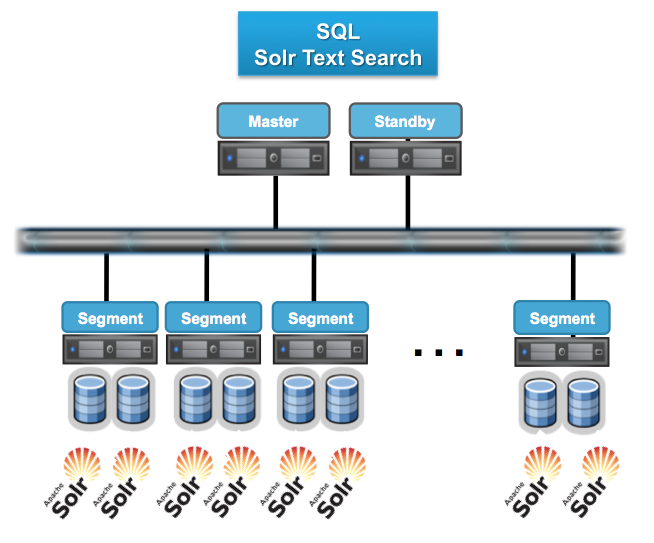
最後,也許有同學會有問題,Greenplum採用Master-slave架構,Master是否會成為瓶頸?完全不用擔心,Greenplum所有的並行任務都是在Segment資料節點上完成後,Master只負責生成和優化查詢計劃、派發任務、協調資料節點進行平行計算。
按照我們在使用者現場觀察到的,Master上的資源消耗很少有超過20%情況發生,因為Segment才是計算和載入發生的場所(當然,在HA方面,Greenplum提供Standby Master機制進行保證)。
再進一步看,Master-Slave架構在業界的大資料分散式計算和雲端計算體系中被廣泛應用,大家可以看到,現在主流分散式系統都是採用Master-Slave架構,包括:Hadoop FS、Hbase、MapReduce、Storm、Mesos……無一例外都是Master-Slave架構。相反,採用Multiple Active Master 的軟體系統,需要消耗更多資源和機制來保證元資料一致性和全域性事務一致性,特別是在節點規模較多時,將導致效能下降,嚴重時可能導致多Master之間的腦裂引發嚴重系統故障。
Greenplum不能做什麼?
Greenplum最大的特點總結就一句話:基於低成本的開放平臺基礎上提供強大的並行資料計算效能和海量資料管理能力。這個能力主要指的是平行計算能力,是對大任務、複雜任務的快速高效計算,但如果你指望MPP並行資料庫能夠像OLTP資料庫一樣,在極短的時間處理大量的併發小任務,這個並非MPP資料庫所長。請牢記,並行和併發是兩個完全不同的概念,MPP資料庫是為了解決大問題而設計的平行計算技術,而不是大量的小問題的高併發請求。
再通俗點說,Greenplum主要定位在OLAP領域,利用Greenplum MPP資料庫做大資料計算或分析平臺非常適合,例如:資料倉庫系統、ODS系統、ACRM系統、歷史資料管理系統、電信流量分析系統、移動信令分析系統、SANDBOX自助分析沙箱、資料集市等等。
而MPP資料庫都不擅長做OLTP交易系統,所謂交易系統,就是高頻的交易型小規模資料插入、修改、刪除,每次事務處理的資料量不大,但每秒鐘都會發生幾十次甚至幾百次以上交易型事務 ,這類系統的衡量指標是TPS,適用的系統是OLTP資料庫或類似Gemfire的記憶體資料庫。
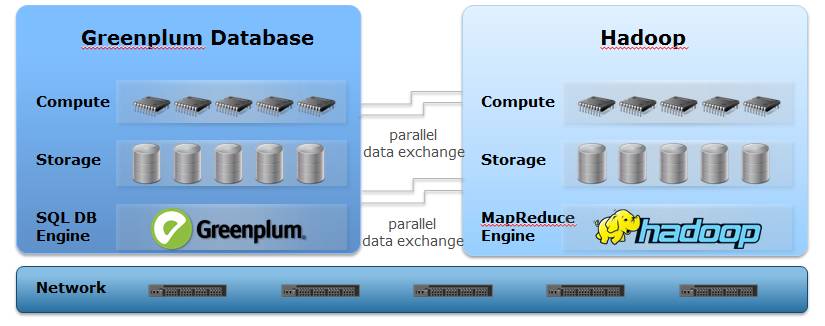
Greenplum MPP 與 Hadoop
MPP和Hadoop都是為了解決大規模資料的平行計算而出現的技術,兩種技術的相似點在於:
-
分散式儲存資料在多個節點伺服器上
-
採用分散式平行計算框架
-
支援橫向擴充套件來提高整體的計算能力和儲存容量
-
都支援X86開放叢集架構
但兩種技術在資料儲存和計算方法上,也存在很多顯而易見的差異:
-
MPP按照關係資料庫行列表方式儲存資料(有模式),Hadoop按照檔案切片方式分散式儲存(無模式)
-
兩者採用的資料分佈機制不同,MPP採用Hash分佈,計算節點和儲存緊密耦合,資料分佈粒度在記錄級的更小粒度(一般在1k以下);Hadoop FS按照檔案切塊後隨機分配,節點和資料無耦合,資料分佈粒度在檔案塊級(預設64MB)。
-
MPP採用SQL並行查詢計劃,Hadoop採用Mapreduce框架
基於以上不同,體現在效率、功能等特性方面也大不相同:
1.計算效率比較:
先說說Mapreduce技術,Mapreduce相比而言是一種較為蠻力計算方式(業內曾經甚至有聲音質疑MapReduce是反潮流的),資料處理過程分成Map-〉Shuffle-〉Reduce的過程,相比MPP 資料庫平行計算而言,Mapreduce的資料在計算前未經整理和組織(只是做了簡單資料分塊,資料無模式),而MPP預先會把資料有效的組織(有模式),例如:行列表關係、Hash分佈、索引、分割槽、列儲存等、統計資訊收集等,這就決定了在計算過程中效率大為不同:
1
MAP效率對比:
-
Hadoop的MAP階段需要對資料的再解析,而MPP資料庫直接取行列表,效率高
-
Hadoop按照64MB分拆檔案,而且資料不能保證在所有節點均勻分佈,因此MAP過程的並行化程度低;MPP資料庫按照資料記錄拆分和Hash分佈,粒度更細,資料分佈在所有節點中非常均勻,並行化程度很高
-
Hadoop HDFS沒有靈活的索引、分割槽、列儲存等技術支援,而MPP通常利用這些技術大幅提高資料的檢索效率;
Shuffle效率對比:(Hadoop Shuffle 對比MPP計算中的重分佈)
-
由於Hadoop資料與節點的無關性,因此Shuffle是基本避免不了的;而MPP資料庫對於相同Hash分佈資料不需要重分佈,節省大量網路和CPU消耗;
-
Mapreduce沒有統計資訊,不能做基於cost-base的優化;MPP資料庫利用統計資訊可以很好的進行平行計算優化,例如,對於不同分佈的資料,可以在計算中基於Cost動態的決定最優執行路徑,如採用重分佈還是小表廣播
Reduce效率對比:(對比於MPP資料庫的SQL執行器-executor)
-
Mapreduce缺乏靈活的Join技術支援,MPP資料庫可以基於COST來自動選擇Hash join、Merger join和Nestloop join,甚至可以在Hash join通過COST選擇小表做Hash,在Nestloop Join中選擇index提高join效能等等;
-
MPP資料庫對於Aggregation(聚合)提供Multiple-agg、Group-agg、sort-agg等多種技術來提供計算效能,Mapreuce需要開發人員自己實現;
另外,Mapreduce在整個MAP->Shuffle->Reduce過程中通過檔案來交換資料,效率很低,MapReduce要求每個步驟間的資料都要序列化到磁碟,這意味著MapReduce作業的I/O成本很高,導致互動分析和迭代演算法開銷很大,MPP資料庫採用Pipline方式在記憶體資料流中處理資料,效率比檔案方式高很多;
總結以上幾點,MPP資料庫在計算並行度、計算演算法上比Hadoop更加SMART,效率更高;在客戶現場的測試對比中,Mapreduce對於單表的計算尚可,但對於複雜查詢,如多表關聯等,效能很差,效能甚至只有MPP資料庫的幾十分之一甚至幾百分之一,下圖是基於MapReduce的Hive和Greenplum MPP在TPCH 22個SQL測試效能比較:(相同硬體環境下)
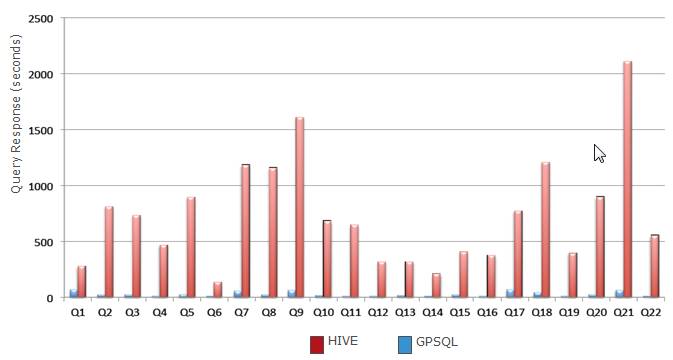
還有,某國內知名電商在其資料分析平臺做過驗證,同樣硬體條件下,MPP資料庫比Hadoop效能快12倍以上。
2.功能上的對比
MPP資料庫採用SQL作為主要互動式語言,SQL語言簡單易學,具有很強資料操縱能力和過程語言的流程控制能力,SQL語言是專門為統計和資料分析開發的語言,各種功能和函式琳琅滿目,SQL語言不僅適合開發人員,也適用於分析業務人員,大幅簡化了資料的操作和互動過程。
而對MapReduce程式設計明顯是困難的,在原生的Mapreduce開發框架基礎上的開發,需要技術人員諳熟於JAVA開發和並行原理,不僅業務分析人員無法使用,甚至技術人員也難以學習和操控。為了解決易用性的問題,近年來SQL-0N-HADOOP技術大量湧現出來,幾乎成為當前Hadoop開發使用的一個技術熱點趨勢。
這些技術包括:Hive、Pivotal HAWQ、SPARK SQL、Impala、Prest、Drill、Tajo等等很多,這些技術有些是在Mapreduce上做了優化,例如Spark採用記憶體中的Mapreduce技術,號稱效能比基於檔案的的Mapreduce提高10倍;有的則採用C/C++語言替代Java語言重構Hadoop和Mapreuce(如MapR公司及國內某知名電商的大資料平臺);而有些則直接繞開了Mapreduce另起爐灶,如Impala、hawq採用借鑑MPP計算思想來做查詢優化和記憶體資料Pipeline計算,以此來提高效能。
雖然SQL-On-Hadoop比原始的Mapreduce雖然在易用上有所提高,但在SQL成熟度和關係分析上目前還與MPP資料庫有較大差距:
-
上述系統,除了HAWQ外,對SQL的支援都非常有限,特別是分析型複雜SQL,如SQL 2003 OLAP WINDOW函式,幾乎都不支援,以TPC-DS測試(用於評測決策支援系統(大資料或資料倉庫)的標準SQL測試集,99個SQL)為例,包括SPARK、Impala、Hive只支援其中1/3左右;
-
由於HADOOP 本身Append-only特性,SQL-On-Hadoop大多不支援資料區域性更新和刪除功能(update/delete);而有些,例如Spark計算時,需要預先將資料裝載到DataFrames模型中;
-
基本上都缺少索引和儲存過程等等特徵
-
除HAWQ外,大多對於ODBC/JDBC/DBI/OLEDB/.NET介面的支援有限,與主流第三方BI報表工具相容性不如MPP資料庫
-
SQL-ON-HADOOP不擅長於互動式(interactive)的Ad-hoc查詢,多通過預關聯的方式來規避這個問題;另外,在併發處理方面能力較弱,高併發場景下,需要控制計算請求的併發度,避免資源過載導致的穩定性問題和效能下降問題;
3.架構靈活性對比:
前文提到,為保證資料的高效能運算,MPP資料庫節點和資料之間是緊耦合的,相反,Hadoop的節點和資料是沒有耦合關係的。這就決定了Hadoop的架構更加靈活-儲存節點和計算節點的無關性,這體現在以下2個方面:
1
擴充套件性方面
-
Hadoop架構支援單獨增加資料節點或計算節點,依託於Hadoop的SQL-ON-HADOOP系統,例如HAWQ、SPARK均可單獨增加計算層的節點或資料層的HDFS儲存節點,HDFS資料儲存對計算層來說是透明的;
-
MPP資料庫擴充套件時,一般情況下是計算節點和資料節點一起增加的,在增加節點後,需要對資料做重分佈才能保證資料與節點的緊耦合(重新hash資料),進而保證系統的效能;Hadoop在增加儲存層節點後,雖然也需要Rebalance資料,但相較MPP而言,不是那麼緊迫。
節點退服方面
-
Hadoop節點宕機退服,對系統的影響較小,並且系統會自動將資料在其它節點擴充到3份;MPP資料庫節點宕機時,系統的效能損耗大於Hadoop節點。
Pivotal將GPDB 的MPP技術與Hadoop分散式儲存技術結合,推出了HAWQ高階資料分析軟體系統,實現了Hadoop上的SQL-on-HADOOP,與其它的SQL-on-HADOOP系統不同,HAWQ支援完全的SQL語法 和SQL 2003 OLAP 語法及Cost-Base的演算法優化,讓使用者就像使用關係型資料庫一樣使用Hadoop。底層儲存採用HDFS,HAWQ實現了計算節點和HDFS資料節點的解耦,採用MR2.0的YARN來進行資源排程,同時具有Hadoop的靈活伸縮的架構特性和MPP的高效能計算能力.
當然,有得也有所失,HAWQ的架構比Greenplum MPP資料庫靈活,在獲得架構優越性的同時,其效能比Greenplum MPP資料庫要低一倍左右,但得益於MPP演算法的紅利,HAWQ效能仍大幅高於其它的基於MapReduce的SQL-on-HADOOP系統。
4.選擇MPP還是Hadoop
總結一下,Hadoop MapReduce和SQL-on-HADOOP技術目前都還不夠成熟,效能和功能上都有很多待提升的空間,相比之下,MPP資料在資料處理上更加SMART,要填平或縮小與MPP資料庫之間的效能和功能上的GAP,Hadoop還有很長的一段路要走。
就目前來看,個人認為這兩個系統都有其適用的場景,簡單來說,如果你的資料需要頻繁的被計算和統計、並且你希望具有更好的SQL互動式支援和更快計算效能及複雜SQL語法的支援,那麼你應該選擇MPP資料庫,SQL-on-Hadoop技術還沒有Ready。特別如資料倉庫、集市、ODS、互動式分析資料平臺等系統,MPP資料庫有明顯的優勢。
而如果你的資料載入後只會被用於讀取少數次的任務和用於少數次的訪問,而且主要用於Batch(不需要互動式),對計算效能不是很敏感,那Hadoop也是不錯的選擇,因為Hadoop不需要你花費較多的精力來模式化你的資料,節省資料模型設計和資料載入設計方面的投入。這些系統包括:歷史資料系統、ETL臨時資料區、資料交換平臺等等。
總之,Bear in mind,千萬不要為了大資料而大資料(就好像不要為了創新而創新一個道理),否則,你專案最後的產出與你的最初設想可能將差之千里,行業內不乏失敗案例。
最後,提一下,Greenplum MPP資料庫支援用“Hadoop外部表”方式來訪問、載入Hadoop FS的資料,雖然Greenplum的Hadoop外部表效能大幅低於MPP內部表,但比Hadoop 自身的HIVE要高很多(在某金融客戶的測試結果,比HIVE高8倍左右),因此可以考慮在專案中同時部署MPP資料庫和Hadoop,MPP用於互動式高效能分析,Hadoop用於資料Staging、MPP的資料備份或一些ETL batch的資料清洗任務,兩者相輔相成,在各自最擅長的場景中發揮其特性和優勢。
5.未來GP發展之路
過去十年,IT技術潮起潮落髮生著時刻不停的變化,而在這變化中的不變就是走向開放和開源的道路,即將到來的偉大變革是雲端計算時代的到來,任何IT技術,從硬體到軟體到服務,都逃不過要接受雲端計算的洗禮,不能趕上時代潮流的技術和公司都將被無情的淘汰。大資料也要擁抱雲端計算,大資料將作為一種資料服務來提供(DaaS-Data as A Service),依靠雲提供共享的、彈性、按需分配的大資料計算和儲存的服務。
Greenplum MPP資料庫從已一開始就是開放的技術,並且在2015年年底已經開源和成立社群(在開源第一天就有上千個Download),可以說,Greenplum已經不僅僅只是Pivotal公司一家的產品,我們相信越來越多組織和個人會成為Greenplum的Contributor貢獻者,隨著社群的發展將推動Greenplum MPP資料庫走向新的高速發展旅程。(分享一下開源的直接好處,最近我們某使用者的一個特殊需求,載入資料中有回車等特殊字元,我們下載了GP外部表gpfdist原始碼,不到一天就輕鬆搞定問題)
Greenplum也正在積極的擁抱雲端計算,Cloud Foundry的PaaS雲平臺正在技術考慮把Greenplum MPP做為DaaS服務來提供,對於Mesos或其它雲端計算技術的愛好者,也可以考慮採用容器映象技術+叢集資源框架管理技術來部署Greenplum,從而可以實現在公共計算資源叢集上的MPP敏捷部署和資源共享與分配。
總之,相信沿著開放、開源、雲端計算的路線繼續前行,Greenplum MPP資料庫在新的時代將保持旺盛的生命力,繼續高速發展。
原文來自http://dbaplus.cn/news-21-341-1.html