
解決Scrapy效能問題——案例五(Item併發太多導致溢位)
阿新 • • 發佈:2019-01-09
症狀:爬蟲對於每個Response都產生了多個Item,系統的吞吐量比期望的要低,並且可能會出現和前一個案例相同的下載器開/關現象。
示例:這裡我們假設有1000個請求,每個返回的頁面有100個Item,響應時間為0.25s,Item在pipeline中的處理時間為3s。分別把CONCURRENT_ITEMS設定成從10到150的值來執行爬蟲:
for concurrent_items in 10 20 50 100 150; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=100000 -s \
SPEED_T_RESPONSE=0.25 -s SPEED_ITEMS_PER_DETAIL=100 結果如下:
s/edule d/load scrape p/line done mem
952 16 32 180 0 243714
920 16 64 640 0 487426
888 16 96 960 0 731138
...
討論:需要再次提醒一下的是,這隻適於用你的爬蟲對每個響應都會產生很多Item的情況。如果不是這種情況,把CONCURRENT_ITEMS設定成1就相當於這種情況了。
第一個注意到的是,p/line列的數值和scape
p/line = CONCURRENT_ITEMS · scape,這種我們所期望的一樣,因為scape表示的是Response的數目而p/line表示的是Item的數目。
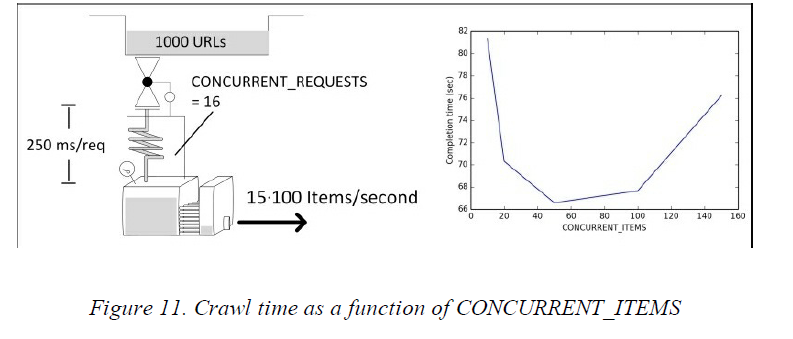
第二個有趣的事是圖11中的效能曲線,雖然圖的縱軸已經經過了縮放,以便更好地展示不同設定之間的差別,但是實際上差別並沒有那麼大。從圖上可以看出,在座標軸左側的延遲很高,因為Item不能及時地處理導致Response物件積壓以致於達到了記憶體的限制(前一個案例講過);而在座標軸的右邊是因為併發的數目太多,使用了太多的CPU。不過把效能正好高估在某個最優點上也不是那麼重要,因為在實際使用中,很容易地就往左或者往右偏移了一點。
解決方法:如果CPU的使用率很高,那就減小CONCURRENT_ITEMS的值;如果達到了Response物件的5MB的記憶體限制,說明你的pipeline的吞吐量跟不上下載器的吞吐量了,那就增加CONCURRENT_ITEMS的值,以加快處理Response的速度。如果設定這個CONCURRENT_ITEMS的值還是沒有作用,那就看一下前一個案例中的建議,並仔細地分析一下你的scraper的吞吐量是否能被其餘的系統所支撐。