
Opencv學習筆記_計算機視覺是什麼?Opencv的起源
從0開始學習“OPENCV”第一天-概述
在學習任何一門新的語言或者框架時都應該瞭解這個行業的背景知識,正所謂工欲善其事,必先利其器!
一、Opencv概述
1. 什麼是計算機視覺?計算機視覺有多難、
1.1 什麼是計算機視覺?
1.2
在說Opencv之前要說一下什麼是計算機視覺,計算機視覺是在影象基礎上發展起來的一門新興學科,計算機視覺是研究讓機器如何看世界,認識這個五彩繽紛的世界,就是讓攝像頭代替人眼來對目標進行識別,跟蹤和測量,並進一步對捕獲的影象資料(視訊資料)轉換成一種新的表達方式或者一個新的決策的過程!在轉換過程中進行的轉換都是為了達到某一目標。
舉個列子:通過輸入裝置(攝像頭、掃描器)將前方1米處發現的物體輸入到電腦中,並對這些資料進行處理,然後與資料庫裡的模型比對,那麼最後得到的決策可能是前方有一輛汽車或者站著一個人,處理的過程可能是把彩色影象轉換成單通道的灰色圖(灰色圖要比彩色圖容易處理後面會說為什麼),對影象降噪聲,或者通過影象序列分析去除攝像機晃動的影響,這些轉換過程/處理過程最終將會轉換成一種新的決策,表達方式!
這裡稍微補充一下什麼是影象序列分析,這裡說的影象序列分析和影象序列不同!
影象序列是就是一組影象(或者拍攝時的影象)的先後順序!
影象序列分析利用計算機視覺技術從一組影象序列中檢測運動及運動物體並對其進行運動分析、跟蹤或識別。影象序列分析在國民經濟和軍事領域的許多方面有著廣泛的應用。
隨著計算機視覺的誕生,人工智慧技術也隨著和誕生,其中人工智慧技術中生物識別技術能從計算機處理的影象資料(多維資料)中獲取資訊,並對這個資訊進行識別,並做相應的處理,人工智慧領域下有很多技術比如最著名的機器學習等等這裡就不做太多的詳細介紹,後面學到機器學習時會和大家詳細介紹人工智慧技術下各個領域作用!
因為計算機視覺是計算機學科所以在、工程、訊號處理、物理學、應用數學和統計學、神經生理學和認知科學等都有研究方面,在製造業、檢驗、文件分析、醫療診斷、和軍事等領域等各種智慧/自主應用方面,都有非常廣闊的前景發展!
1.2計算機視覺實現起來難嗎?
人類本身是視覺動物,所以覺得人類覺得可以很容易實現計算機視覺,假如說讓你從一個場景中找到一輛汽車,顯然很容易,因為汽車本身較大,容易被眼睛所捕獲,但是其中在捕獲的過程中有著很複雜的過程:
所以我們要想真正的實現一個人工智慧產品的話就要把人類自己本身的所有資訊模擬到計算機上,比如大腦=CPU,眼睛=攝像頭,感官=感測器,並且要讓之間協調工作,相對來說是非常複雜的!
其次計算機接受到的資料主要來源於攝像頭,磁碟檔案中的數值矩陣!
圖1.1(取之“學習Opencv“)中的汽車有一個反光鏡但是計算機只看到一組數值矩陣:
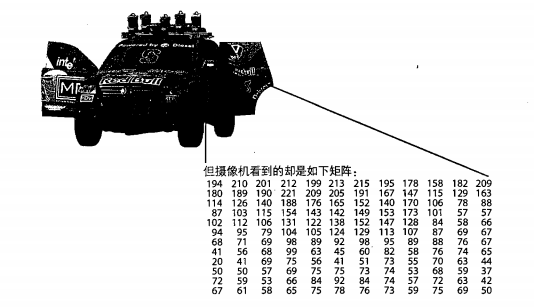
由於該圖是單通道(黑白圖)所以一個矩陣數值就可以表示一個畫素點,如果是多通道的RGB顏色就需要三個數值表示,比如194 210 201表示一個畫素點,而單通道194就可以表示畫素點!
其中非常令人頭疼的問題就是影象噪聲
左:正常圖片右:帶影象噪聲的圖片

如果一張圖裡每個畫素點上都摻雜著影象噪聲的話會降低影象識別的準確率
影象噪聲產生的問題主要來自輸入裝置(攝像機),造成攝像機產生影象噪聲的幾種原因如下:
1. 外部噪聲:
即指系統外部干擾以電磁波或經電源串進系統內部而引起的噪聲。如電氣裝置,天體放電現象等引起的噪聲。
2. 內部噪聲(分為四種):
(1)由光和電的基本性質所引起的噪聲。如電流的產生是由電子或空穴粒子的集合,定向運動所形成。因這些粒子運動的隨機性而形成的散粒噪聲;導體中自由電子的無規則熱運動所形成的熱噪聲;根據光的粒子性,影象是由光量子所傳輸,而光量子密度隨時間和空間變化所形成的光量子噪聲等。
(2)電器的機械運動產生的噪聲。如各種接頭因抖動引起電流變化所產生的噪聲;磁頭、磁帶等抖動或一起的抖動等。
(3)器材材料本身引起的噪聲。如正片和負片的表面顆粒性和磁帶磁碟表面缺陷所產生的噪聲。隨著材料科學的發展,這些噪聲有望不斷減少,但在目前來講,還是不可避免的。
(4)系統內部裝置電路所引起的噪聲。如電源引入的交流噪聲;偏轉系統和箝位電路所引起的噪聲等。
3. 網路噪聲
這個只是簡單提一下一般的單機視覺開發一般用不到:網路噪聲就是在通過UDP傳輸影象資料時因為網路不穩定造成傳輸時出現丟包的現象,導致傳輸過去的矩陣數值與原數值不一樣,導致每個畫素點上的值出現損壞的情況,每個畫素點上就出現很多白色小斑點的圖狀物就叫影象噪聲!
TCP不會出現影象噪聲的問題,因為TCP為了確保資料的準確性,有重發機制,這裡不做詳細介紹,想詳細瞭解可以在我的分欄裡“網路層原理”這一欄中找到關於對TCP詳細介紹的文章!
如果一個視覺系統裡沒有模式識別系統,自動控制的對焦和光圈,沒有多年來的經驗累計的視覺系統通常屬於很低階的視覺系統!
4. 根據特徵切割場景
除了噪聲以外還有許多其他阻擋計算機視覺處理的難題,列如場景物體的干擾,在三維場景中重建二維圖
場景物體的干擾:
假如我們要做一個能夠自動把房間裡掉地上的書撿起來放到書架上,那麼我們需要從這個房間場景中找出我們所需要的目標物品:書。
假如說這個人的房間非常大或者在客廳,那麼時首先如果從右到左或者從左到右採用地毯式的搜尋的話會需要進行大量的分析演算法同時因為CPU/ALT運算單元會進行過多的演算法運算一直處於高電平狀態。
會加快消耗機器人的電能,在這樣的情況下我們可以告訴機器人書一般會在某個地方出現:書櫃、桌子、床上,沙發的周邊地區。
然後將這三個模型匯入到撿書機器人的比對資料庫裡,首先一點是在拍攝這些配對模型時,要將物品放到最能表現其特徵的地方:“正中心位置”。
為了讓撿書機器人在比對模型時準確率更高可以為其比對模型新增一些隱含的變數:大小,重力方向以及其他變數,然後在比對時將捕獲的床或者沙發進行分析推斷出物品體積並通過機器學習技術不停的根據上下文解釋資訊進行建模訓練,校正變數,讓其準確率更高!
(這裡說一下重力方向:給予重力方向的優點是可以通過目標物體的重力方向推斷出該物體會在那個位置出現,這樣在一個非常大的宮殿裡尋找一張床,有了這張床的重力方向,可以以自身為中心並根據床的重力方向推斷出大概會在那個方位!)
有了這些資訊之後那麼機器人可以很快的過濾掉場景中書籍不可能會掉落的地方,那麼機器人可以很快的找出書籍並放到書架上!當然你也可以給機器人安裝鐳射掃描器使其捕獲的物品體積使其在機器訓練時用捕獲的資料與模型資料進行校正時更加準確!
並且撿書機器人上的攝像機並非屬於固定攝像機,固定攝像機對場景約束較多,但是可以通過這些約束簡化問題,但是移動攝像機需要不停的變更場景,所以移動攝像機的場景約束較少,需要做更多的簡化工作!
重建二維圖
就像上面說的,要從一個房間裡找到書可以根據特徵來尋找加快尋找時間,那麼在找到一個目標時首先要將這個目標轉換成二維圖,也就是說三維圖是立體的,存在前後之分,而二維圖不存在前後之分,只有寬高,為什麼要轉換成二維圖?可以想一下圖1是三維圖圖二是二維圖(影象來源:http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_homography/feature_homography.html)這一部分不必管是如何實現的!
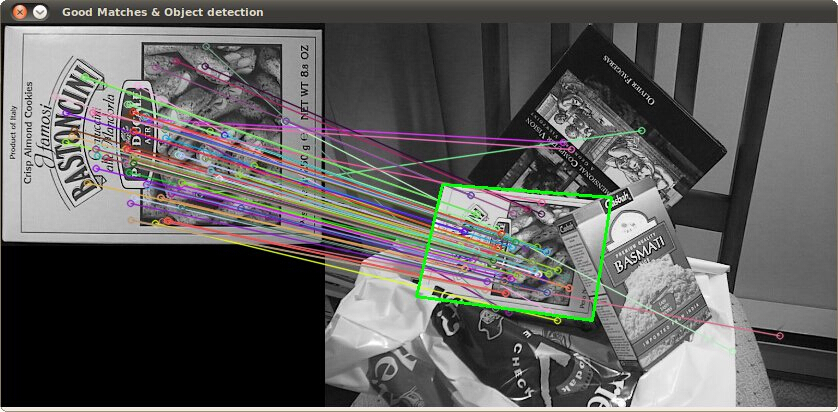
二維圖的方法就是從一個三維圖(立體)中根據二維特徵(平面)將二維資料提取出來並對映到另外一個影象資料上!
可以可看到二維圖可以更好的方便識別所需表面特徵!
1. opencv還可以很好的修復影象中的畸變
下圖列子展示了影象畸變和畸變後校正的影象(轉自:http://www.cnblogs.com/Lemon-Li/p/3283059.html)
圖一畸變影象

影象空間畸變圖:

圖二opencv畸變校正後的影象


現在先不管是如何利用opencv修復的,到後面的文章會慢慢和大家講解!
影象畸變會給人一種凹凸的感覺,所以在視覺上看起來並不是特別美觀!
二. Opencv發展歷程
1.
早期在做影象處理時所需要的演算法運算量是非常大的,所以那個時候在對影象做基礎處理都要耗費很長的時間,正因如此1996年時lntel釋出奔騰處理器時同時釋出MMX指令集“看過我那篇“深度理解指令集”的朋友應該都對這個指令集有所瞭解“,MMX(後來的SSE)這種單指令多資料的多媒體指令集在運算時運算速度要比平常的影象演算法快上幾倍甚至幾十倍,這才把影象處理從慢車道推向了快車道!
如果想深度瞭解MMX指令集的發展史可以去看我那篇“深度理解指令集”的最後一段!
可是如果想要使用MMX(SSE)指令集的話必須會組合語言才行,所以基於彙編的演算法開發和優化需要耗費時間比較長。
所以後來Intel基於MMX(SSE)指令集推出了IPL庫,IPL是基於MMX指令集,後來因為MMX指令集的缺陷推出SSE指令集同時推出封裝SSE指令集的IPP庫,換句話說IPP庫就是基於IPL庫的!
MMX(SSE)指令集裡包含的大多都是對影象處理的基礎函式,在對影象進行復雜處理時短時間裡比較難以實現,而且MMX(SSE)指令集是非開源的,在那個年代追求效率的企業都希望既能開發出效能優越的視覺系統,提高開發效率,降低開發成本,所以後來1999年Intenl啟動CLV專案主要目標是人機介面,能被UI呼叫的實時計算機視覺庫,為Intel處理器做了特定優化。
後來2000年6月正式釋出的第一個在Windows平臺下第一個Opencv開源版本“OpenCV alpha 3”同年12月釋出在Linux平臺下“OpenCV beta 1”開源版本。
Opencv不僅開源免費,內部對影象處理的函式非常豐富,內部函式的實現一般都使用IPP庫做優化,同上其實Opencv並不是完全開源,因為IPP庫是非開源的,所以內部使用IPP做優化的函式屬於非開源沒有使用IPP做優化的屬於開源,可以說Opencv屬於半開源的專案!
2. 可移植性
Opencv採用C/C++編寫在不同的系統環境上只要稍微修改一下程式碼就可以編譯通過,可以在Mac/Linux/Windows系統上執行,並且為python,Ruby,MATLAB等程式語言提供介面!
3. 執行效率
Opencv在設計時的目標就是執行速度儘量快所以內部函式都是標C函式來編寫的,如果想要起到硬體加速(內部函式用IPP優化)需要購買IPP庫,購買IPP庫後Opencv在執行時會自動呼叫IPP庫做優化!
4. 應用領域
目前Opencv應用領域非常廣泛,在醫療裝置、工廠檢驗、立體視覺、機器學習、人臉別識別、影象拼接、生物醫學分析、無人機、等人工智慧領域有廣泛應用!
甚至計算機視覺可以用在聲譜圖上,對聲音和音樂進行分析!
並且計算機視覺被廣泛應用於工廠檢驗,大規模的產品製造在流水線上的某一環節都使用計算機視覺做檢測!
5. Opencv目標
Opencv的目標是為解決計算機視覺提供基本工具,當然在有些情況下,Opencv還提供了許多高層函式用於解決複雜式影象處理,當然如果沒有這些高層函式也完全可以基於Opencv提供的基礎函式上建立一個完整的解決方案,在用Opencv建立一個解決方案時,儘管這個解決方案不是特別完美,但是有了第一個解決方案之後,便會從這個解決方案中找到許多不足的地方,但是可以基於這個解決方案之上來不停的對其優化整改,到一套完整的解決方案體系,雖然說很難達到十全十美但是達到十全九美就可以了,當然解決方案的不足也可以通過系統所使用的環境來解決,比如要識別出場景中這個人的身高,可以為計算機安裝鐳射紅外掃描器來精準的捕獲目標物體的身高並輸入到計算機裡更加方便的處理資料!
6. Opencv庫組成體系(取自:學習Opencv圖1-5)
這些體系可能與你當前使用的Opencv版本不同
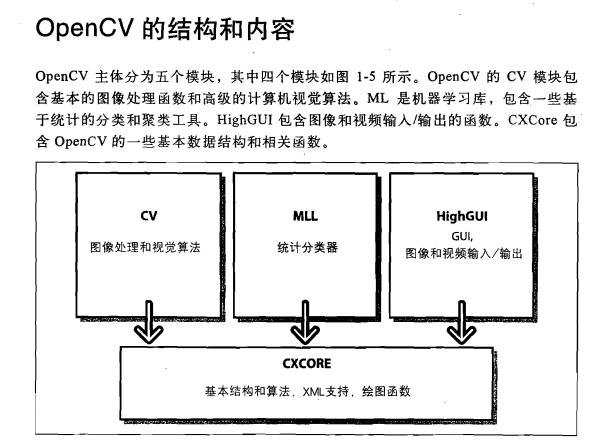
圖中沒用包含CvAux模組,因為該模組中一般包含一些即將淘汰的演算法和函式(比如基於嵌入式隱馬爾可夫模型的人臉識別等等),所以如果突然有一天你發現你要使用的基於某個演算法寫出來的函式不見了,可以到這個模組裡或許能找到!
1. 版權
Opencv開源協議允許你使用Opencv庫的全部程式碼,生成商業產品,並且不需要公開原始碼,或對Opencv庫中的演算法改善後的演算法!
2. 預備
在學習Opencv之前要懂得C/C++程式設計,和一些數學基礎!
3. 總結
1.Opencv第一個windows版本是2000年6月推出的,“OpenCV alpha 3”同年12月釋出在Linux平臺下!
2.Opencv第一個開源版本是OpenCV beta 1
3.Opencv是屬於Intel公司的一個開源專案(IPP不開源),
4.Opencv目前可以運用在製造業、機器學習、生物識別、檢驗、文件分析、醫療診斷、和軍事等領域等各種智慧/自主應用方面,應用範圍非常廣泛!
5.Opencv原始碼是C/C++編寫的,如果想要呼叫IPP庫加速內部函式程式碼需要購買!
6.Opencv庫可以在Windows、Linux、Mac平臺下執行,併為python,Ruby,MATLAB等流行程式語言提供介面
7.opencv是由cv(影象處理和視覺演算法),mll(統計分類器),highgui(GUI/影象和視訊輸入/輸出),cxcore(基本結構和演算法,xml支援,繪圖函式),五大模組組成!
8.影象識別令人最頭疼的地方是影象噪聲,場景重塑
9.影象噪聲產生原因由:外部噪聲,內部噪聲,還有網路噪聲。
10.影象序列是就是一組影象(或者拍攝時的影象)的先後順序!
11.影象序列分析是對一組已經排序好的影象進行運動分析!
12.影象分析分為兩種:實時分析,非實時分析
13.實時分析就是對輸入裝置裡的資料進行實施動作分析,而非實時分析就是對一組有序儲存於本地儲存器上的圖片進行動作分析!
14.想要真正實現一個完全人工智慧視覺產品是很複雜的,其中要考慮到很多複雜因素!
練習:安裝Opencv練習
有需要的可以去看下我的這篇安裝教程寫的非常詳細-點選開啟連結