
多表連線的三種方式詳解 HASH JOIN MERGE JOIN NESTED LOOP
在多表聯合查詢的時候,如果我們檢視它的執行計劃,就會發現裡面有多表之間的連線方式。 之前打算在sqlplus中用執行計劃的,但是格式看起來有點亂,就用Toad 做了3個截圖。

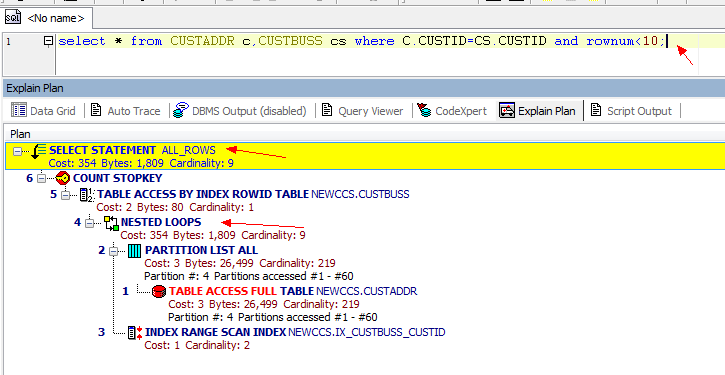
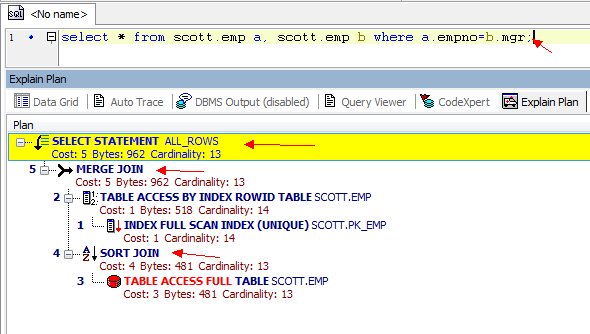
從3張圖裡我們看到了幾點資訊:
1.CBO 使用的ALL_ROWS模式
Oracle Optimizer CBO RBO
2.表之間的連線用了hash Join, Nested loops,Sort Merge Join
多表之間的連線有三種方式:Nested Loops,Hash Join 和 Sort Merge Join. 下面來介紹三種不同連線的不同:
一.
NESTED LOOP:
對於被連線的資料子集較小的情況,巢狀迴圈連線是個較好的選擇。在巢狀迴圈中,內表被外表驅動,外表返回的每一行都要在內表中檢索找到與它匹配的行,因此整個查詢返回的結果集不能太大(大於1 萬不適合),要把返回子集較小表的作為外表(CBO 預設外表是驅動表),而且在內表的連線欄位上一定要有索引。當然也可以用ORDERED 提示來改變CBO預設的驅動表,使用USE_NL(table_name1 table_name2)可是強制CBO 執行巢狀迴圈連線。
Nested loop一般用在連線的表中有索引,並且索引選擇性較好的時候.
步驟:確定一個驅動表(outer table),另一個表為inner
table
cost = outer access cost + (inner access cost * outer cardinality)
| 2 | NESTED LOOPS | | 3 | 141 | 7 (15)|
| 3 | TABLE ACCESS FULL | EMPLOYEES | 3 | 60 | 4 (25)|
| 4 | TABLE ACCESS BY INDEX ROWID| JOBS | 19 | 513 | 2 (50)|
| 5 | INDEX UNIQUE SCAN | JOB_ID_PK | 1 | | |
EMPLOYEES為outer table, JOBS為inner table.
二. HASH JOIN :
雜湊連線是CBO 做大資料集連線時的常用方式,優化器使用兩個表中較小的表(或資料來源)利用連線鍵在記憶體中建立散列表,然後掃描較大的表並探測散列表,找出與散列表匹配的行。
這種方式適用於較小的表完全可以放於記憶體中的情況,這樣總成本就是訪問兩個表的成本之和。但是在表很大的情況下並不能完全放入記憶體,這時優化器會將它分割成若干不同的分割槽,不能放入記憶體的部分就把該分割槽寫入磁碟的臨時段,此時要有較大的臨時段從而儘量提高I/O 的效能。
也可以用USE_HASH(table_name1 table_name2)提示來強制使用雜湊連線。如果使用雜湊連線HASH_AREA_SIZE 初始化引數必須足夠的大,如果是9i,Oracle建議使用SQL工作區自動管理,設定WORKAREA_SIZE_POLICY 為AUTO,然後調整PGA_AGGREGATE_TARGET 即可。
Hash join在兩個表的資料量差別很大的時候.
步驟:將兩個表中較小的一個在記憶體中構造一個HASH表(對JOIN
KEY),掃描另一個表,同樣對JOIN KEY進行HASH後探測是否可以JOIN。適用於記錄集比較大的情況。需要注意的是:如果HASH表太大,無法一次構造在記憶體中,則分成若干個partition,寫入磁碟的temporary
segment,則會多一個寫的代價,會降低效率。
cost = (outer access cost * # of hash partitions) + inner access cost
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 665 | 13300 | 8 (25)|
| 1 | HASH JOIN | | 665 | 13300 | 8 (25)|
| 2 | TABLE ACCESS FULL | ORDERS | 105 | 840 | 4 (25)|
| 3 | TABLE ACCESS FULL | ORDER_ITEMS | 665 | 7980 | 4 (25)|
--------------------------------------------------------------------------
ORDERS為HASH TABLE,ORDER_ITEMS掃描
三.SORT MERGE JOIN
通常情況下雜湊連線的效果都比排序合併連線要好,然而如果行源已經被排過序,在執行排序合併連線時不需要再排序了,這時排序合併連線的效能會優於雜湊連線。可以使用USE_MERGE(table_name1 table_name2)來強制使用排序合併連線.
Sort Merge join 用在沒有索引,並且資料已經排序的情況.
cost = (outer access cost * # of hash partitions) + inner access cost
步驟:將兩個表排序,然後將兩個表合併。通常情況下,只有在以下情況發生時,才會使用此種JOIN方式:
1.RBO模式
2.不等價關聯(>,<,>=,<=,<>)
3.HASH_JOIN_ENABLED=false
4.資料來源已排序
四. 三種連線工作方式比較:
Hash join的工作方式是將一個表(通常是小一點的那個表)做hash運算,將列資料儲存到hash列表中,從另一個表中抽取記錄,做hash運算,到hash 列表中找到相應的值,做匹配。
Nested loops 工作方式是從一張表中讀取資料,訪問另一張表(通常是索引)來做匹配,nested loops適用的場合是當一個關聯表比較小的時候,效率會更高。
Merge Join 是先將關聯表的關聯列各自做排序,然後從各自的排序表中抽取資料,到另一個排序表中做匹配,因為merge join需要做更多的排序,所以消耗的資源更多。 通常來講,能夠使用merge join的地方,hash join都可以發揮更好的效能。
整理自網路
------------------------------------------------------------------------------
QQ: 492913789
Email: [email protected]
Blog: http://www.cndba.cn/dave
網上資源: http://tianlesoftware.download.csdn.net
相關視訊:http://blog.csdn.net/tianlesoftware/archive/2009/11/27/4886500.aspx
DBA1 群:62697716(滿); DBA2 群:62697977(滿)
DBA3 群:63306533;聊天 群:40132017