
Word2Vec原理分析
目錄
一、Doc2vec
可以直接將Sentence/Document中所有詞的向量取均值作為Sentence/Document的向量表示,但是這樣會忽略了單詞之間的排列順序對句子或文字資訊的影響。
1、DM模型在訓練時,首先將每個文件ID和語料庫中的所有詞初始化一個K維的向量,然後將文件向量和上下文詞的向量輸入模型,隱層將這些向量累加(或取均值、或直接拼接起來)得到中間向量,作為輸出層softmax的輸入。在一個文件的訓練過程中,文件ID保持不變,共享著同一個文件向量,相當於在預測單詞的概率時,都利用了真個句子的語義。
2、DBOW模型的輸入是文件的向量,預測的是該文件中隨機抽樣的詞。
二、Word2Vec
1、語言統計模型

用一句簡單的話說,就語言模型就是計算一個句子的概率大小的這種模型。有什麼意義呢?一個句子的打分概率越高,越說明他是更合乎人說出來的自然句子。
2、n-gram模型
預料足夠大時,利用Bayes,可近似為:

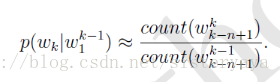
平滑處理:

假設一個詞至於它前面的 n-1 個詞有關。n-garm主要工作是統計詞串在預料出現在次數及平滑處理(加1)。概率值計算好後就儲存起來,下次要計算一個句子的概率時,只要找到相關的概率引數,提出來連乘即可。
3、Huffman樹
帶權路徑長度:從根節點到當前節點的路徑長度乘以當前節點的權值;
樹的帶權路徑為所有葉子節點的帶權路徑長度之和;
給定n個葉子節點n個權值,構造一棵二叉樹,若它的帶權路徑之和達到最小,則為最優二叉樹,即Huffman樹。

4、神經概率語言模型
1、詞向量:
one-hot representation 容易造成維數災難;
word2Vec採用 distributed representation: 將每一個詞對映成一個短向量(有很多非0分量,相對分散,相當於把詞的資訊分散到各個分量中去了),所有向量構成一個詞向量空間,每個向量可視為該空間中的一個點,然後可根據詞之間的距離來判斷相似性;
5、CBOW連續詞袋模型
輸入層是當前詞上下文視窗內的詞的詞向量(k維,隨機初始化);將向量加起來就是隱藏層的k個節點;輸出層是一個二叉樹( 哈夫曼樹Haffman),葉節點代表語料裡所有的詞(語料含V個詞,就有|V|個獨立節點),這樣,對於葉節點的每一個詞,就會有一個全域性唯一的編碼,形如"010011"。我們可以記左子樹為1,右子樹為0。接下來,隱層的每一個節點都會跟二叉樹的內節點有連邊,於是對於二叉樹的每一個內節點都會有K條連邊,每條邊上也會有權值;Haffman它以語料中出現過的詞當葉節點,以各詞在語料中出現的次數當權值構造。
訓練過程:
1、根據語料庫建立詞彙表V,V中的所有詞均初始化一個K維向量,並根據詞頻構建哈夫曼樹;
2、將語料庫中的文字依次進行訓練,以一個文字為例,輸入當前單詞Wi的上下文視窗內的詞的詞向量,由隱藏層累加求和得到k維中間向量Wnew,Wnew在哈夫曼樹種沿某個特定路徑到達某個葉子節點(即當前詞Wi);
3、由於知道Wi,根據其哈夫曼編碼,可以確定從根節點到葉子節點的正確路徑,也確定了路徑上所有分類器(非葉子節點)上應作出的預測概率,相乘就可得到Wi在當前網路下的概率,那麼殘差就是(1-P),於是可以採用梯度下降法調整路徑中非葉子節點的引數,以及最終上下文詞的向量,使得實際路徑向正確路徑靠攏,n次迭代後收斂,即可得到每個詞的詞向量表示。
總結:實際上我們知道要的是哪個詞(Wn),而Wn是肯定存在於二叉樹的葉子節點的,因此它必然有一個二進位制編號,如"010011",那麼接下來我們就從二叉樹的根節點一個個地去便利,而這裡的目標就是預測這個詞的二進位制編號的每一位!即對於給定的上下文,我們的目標是使得預測詞的二進位制編碼概率最大。
6、skip-gram 由當前詞預測上下文
輸入時一個詞的詞向量,不用累加;用當前詞預測上下視窗的每一個詞。過程類似cbow。
CBOW :已知目標詞的上下文,來預測目標詞;
Skip-gram:給定目標詞,預測上下文的詞;
1、CBOW
與神經網路語言模型(NNLM)的區別:
NNLM:輸入層、投影層、隱藏層、輸出層;
1)輸入:前者為向量的前後拼接,後者為求和;
2)前者有隱藏層,後者無;
3)輸出:前者是線性結構,後者是樹結構(Huffman樹);
因為模型的大部分計算集中在隱藏層與輸出層之間的矩陣向量的運算上,CBOW通過去掉隱藏層,,輸出改為Huffman樹,為hierarchical softmax(分層) 技術奠定了基礎;
五、基於隨機負取樣
六、總結
在文字分類中,傳統的將詞轉為詞向量的方法有:
(1)one-hot representation,大量0值,資料稀疏,且易造成維度爆炸;
(2)tfidf向量化:輸出的向量不包含次序資訊,深度神經網路學不到什麼東西,一般用ml的方法如貝葉斯,svn進行分類即可;
(3)word2vec:神經網路(可看成四層結構:輸入層、投影層、隱藏層、輸出層),因隱藏層到輸出層的計算量巨大,所以word2Vec省略了隱含層,僅包含輸入層、投影層、輸出層;
輸入向量為隨機初始化的詞向量;
兩種方法:CBOW、Skip-gram;以CBOW為例,樣本(Context(w),w),輸入為每個詞的詞向量v,在投影層向量累加x,輸出的是softmax(x);後提出兩種加速訓練的方法:softmax和隨機負梯度取樣;
CBOW:
1)已知目標詞的上下文詞,從而預測目標詞的概率;
2)層次softmax:輸出是haffman樹,每個節點是一個二分類,左邊為負樣本(1),右邊為正樣本(0),p(Context(w) | w)的概率為每個節點的概率之積,我們的目標是 p(Context(w) | w)越大越好,代入最大似然函式,得到目標函式:
用隨機梯度上升法更新引數(每次用一組樣本所有的引數),對輸入和非葉子結點向量
進行求導;對每個樣本(Context(w) , w),從根節點出發至節點(w)的所有節點依次進行二分類,由上往下更新引數
和
關於輸入的偏導數
,最後將梯度值貢獻到每個分量上去,以此對每一個上下文單詞Context(w)進行更新;
3)隨機負取樣:以(Context(w) , w)為正樣本,(Context(w) , u)為負樣本,u屬於字典D,每次取一個正樣本的同時要取一定數量的負樣本組成樣本集(選到自己就跳過去),每次一個樣本去更新引數。更新完畢後,對每個Context(w) 中詞的的詞向量更新;
Skip-gram:
1)已知目標詞,預測上下文的概率;
2)對每個上下文單詞,先依次遍歷結點進行引數更新,再更新目標詞的向量;
3)隨機負取樣類似word2vec;
隨機負取樣容易猜到高頻詞如:the、a、an....,就好比一個圓,高頻詞佔的面積會大一些,投飛鏢被刺中的概率也大一些,為解決這個問題,求某個詞的概率時上下取頻率的3/4次方來均衡;;
CBOW每次更新context(w)個詞的詞向量,skip-gram每次更新一個詞(目標詞)的詞向量;haffman樹在每個結點出更新引數,隨機負取樣是每次用一個樣本去更新引數;
glove
要講GloVe模型的思想方法,我們先介紹兩個其他方法:
一個是基於奇異值分解(SVD)的LSA演算法,該方法對term-document矩陣(矩陣的每個元素為tf-idf)進行奇異值分解,從而得到term的向量表示和document的向量表示。此處使用的tf-idf主要還是term的全域性統計特徵。
另一個方法是word2vec演算法,該演算法可以分為skip-gram 和 continuous bag-of-words(CBOW)兩類,但都是基於區域性滑動視窗計算的。即,該方法利用了局部的上下文特徵(local context)
LSA和word2vec作為兩大類方法的代表,一個是利用了全域性特徵的矩陣分解方法,一個是利用區域性上下文的方法。
GloVe模型就是將這兩中特徵合併到一起的,即使用了語料庫的全域性統計(overall statistics)特徵,也使用了局部的上下文特徵(即滑動視窗)。
Glove和skip-gram、CBOW模型對比
Cbow/Skip-Gram 是一個local context window的方法,比如使用NS來訓練,缺乏了整體的詞和詞的關係,負樣本採用sample的方式會缺失詞的關係資訊。
另外,直接訓練Skip-Gram型別的演算法,很容易使得高曝光詞彙得到過多的權重
Global Vector融合了矩陣分解Latent Semantic Analysis (LSA)的全域性統計資訊和local context window優勢。融入全域性的先驗統計資訊,可以加快模型的訓練速度,又可以控制詞的相對權重。
我的理解是skip-gram、CBOW每次都是用一個視窗中的資訊更新出詞向量,但是Glove則是用了全域性的資訊(共線矩陣),也就是多個視窗進行更新