
mysql主從複製、讀寫分離到資料庫水平拆分及庫表雜湊
web專案最原始的情況是一臺伺服器只能連線一個mysql伺服器(c3p0只能配置一個mysql),但隨著專案的增大,這種方案明顯已經不能滿足需求了。
Mysql主從複製,讀寫分離:
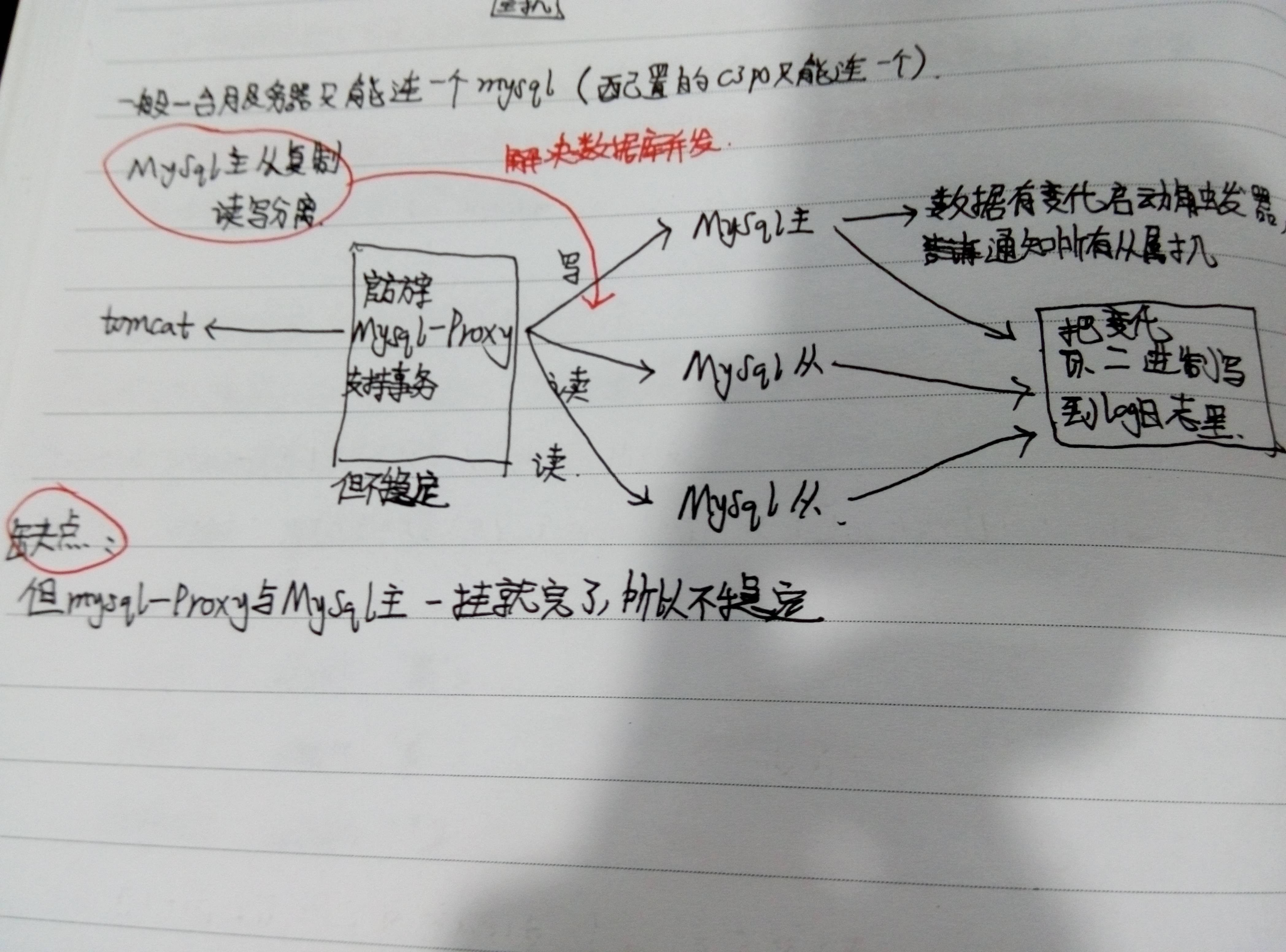
上面的方案使用mysql-Proxy代理,分發讀寫請求,寫操作轉發到Mysql主伺服器,讀操作轉發到Mysql從伺服器(多個),Mysql主伺服器資料有變動時,會把變化以二進位制的形式寫入到log日誌裡,然後Mysql從伺服器再從log日誌中讀取變化資料,以完成資料同步。
缺點:因為Mysql分發代理和Mysql主伺服器都只有一臺,一旦宕機就不行了,即很不穩定。
改進方案:
1,把tomcat和mysql代理放一臺伺服器上,比如一個專案有10臺App伺服器,每臺伺服器上都有tomat和Mysql-Proxy,進行資料庫操作時,tomcat先連線本機上的myql代理,代理幫忙轉發到各個mysql
2,同時,為了使mysql主機可靠,mysql主機也要配置多臺,為了實現這種功能,要在多臺myql主機之前配置負載均衡伺服器,同時為了保證負載均衡伺服器的可靠性,還要配置負載均衡—備機。雖然mysql主機有多臺,但要保證只有一臺會把資料變化寫入到log日誌裡。
缺點:
1,會有資料延遲,比如mysql主機被寫入修改了資料,但mysql從機還需要時間進行同步
2,比如執行一年之後,mysql主機上已經有了1千萬條資料,並且這些資料都會被同步到所有從屬mysql上,因為mysql對千萬級別資料查詢會變慢,導致mysql叢集效能都會大大降低。
進一步改進方案,即資料庫水平拆分及庫表雜湊:
水平拆分一種方案:
比如有3個分片資料庫伺服器,每一個都有一個備機,每一組主機和備機資料都會同步。(至少一半的伺服器效率浪費了)
(當資源有限時,可以把A分片資料庫和B分片資料庫的備機放在同一個伺服器上,B資料庫和C資料庫的備機放到同一個伺服器上....這樣穩定性雖然降低了,伺服器使用效率提高了)
然後一個使用者表,因為id經常是資料庫自動生成的,所以在新增使用者資料的時候id是未知,不能根據id進行水平拆分。
可以根據使用者用欄位username.hashCode()返回一個int型資料,然後Math.abs()取絕對值,然後再% 1024取餘數,這樣獲得的結果result就是0~1023
然後當0 <= result && result < 333時,把資料存放到第一個資料庫,當333 <= result && result < 666時,把資料存放到第二個資料庫,當666 <= result && result < 1024時,把資料存放到第三個資料庫。
具體一些的程式碼:
①首先在spring配置檔案application-context.xml中配置6個數據源:
- <!-- 資料來源1 -->
- <bean id="dataSource1"class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <property name="driverClass" value="${jdbc.driverClassName}" />
- <property name="jdbcUrl" value="${jdbc1.url}" />
- <property name="user" value="${jdbc1.username}" />
- <property name="password" value="${jdbc1.password}" />
- <property name="autoCommitOnClose" value="true"/>
- <property name="initialPoolSize" value="${cpool.minPoolSize}"/>
- <property name="minPoolSize" value="${cpool.minPoolSize}"/>
- <property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
- <property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
- <property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
- <property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
- </bean>
- <!-- 資料來源2 -->
- <bean id="dataSource2"class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <property name="driverClass" value="${jdbc.driverClassName}" />
- <property name="jdbcUrl" value="${jdbc2.url}" />
- <property name="user" value="${jdbc2.username}" />
- <property name="password" value="${jdbc2.password}" />
- <property name="autoCommitOnClose" value="true"/>
- <property name="initialPoolSize" value="${cpool.minPoolSize}"/>
- <property name="minPoolSize" value="${cpool.minPoolSize}"/>
- <property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
- <property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
- <property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
- <property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
- </bean>
- 一共類似6個
②引入配置的6個數據源(3組,每組一個主資料庫一個備資料庫):
- <!-- 配置資料來源開始 -->
- <bean id="dataSources"class="com.caland.sun.client.datasources.DefaultDataSourceService">
- <property name="dataSourceDescriptors">
- <set>
- <bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
- <property name="identity" value="partition1"/>
- <!-- 指定資料來源1 -->
- <property name="targetDataSource" ref="dataSource1"/>
- <!-- 對資料來源1進行心跳檢測 -->
- <property name="targetDetectorDataSource" ref="dataSource1"/>
- <!-- 指定備機資料來源4 -->
- <property name="standbyDataSource" ref="dataSource4"/>
- <!-- 對備機進行心跳檢測 -->
- <property name="standbyDetectorDataSource" ref="dataSource4"/>
- </bean>
- <bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
- <property name="identity" value="partition2"/>
- <property name="targetDataSource" ref="dataSource2"/>
- <property name="targetDetectorDataSource" ref="dataSource2"/>
- <property name="standbyDataSource" ref="dataSource5"/>
- <property name="standbyDetectorDataSource" ref="dataSource5"/>
- </bean>
- <bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
- <property name="identity" value="partition3"/>
- <property name="targetDataSource" ref="dataSource3"/>
- <property name="targetDetectorDataSource" ref="dataSource3"/>
- <property name="standbyDataSource" ref="dataSource6"/>
- <property name="standbyDetectorDataSource" ref="dataSource6"/>
- </bean>
- </set>
- </property>
- <!-- HA配置,對資料庫傳送SQL語句:update caland set timeflag=CURRENT_TIMESTAMP()進行資料庫狀態檢測 -->
- <property name="haDataSourceCreator">
- <bean class="com.caland.sun.client.datasources.ha.FailoverHotSwapDataSourceCreator">
- <property name="detectingSql" value="update caland set timeflag=CURRENT_TIMESTAMP()"/>
- </bean>
- </property>
- </bean>
- <!-- 配置路由規則開始 -->
- <!-- hash演算法實現類 -->
- <bean id="hashFunction"class="com.caland.core.dao.router.HashFunction"/>
- <bean id="internalRouter"
- class="com.caland.sun.client.router.config.InteralRouterXmlFactoryBean">
- <!-- functionsMap是在使用自定義路由規則函式的時候使用 -->
- <property name="functionsMap">
- <map>
- <entry key="hash" value-ref="hashFunction"></entry>
- </map>
- </property>
- <property name="configLocations">
- <list>
- <!-- 路由規則檔案 -->
- <value>classpath:/dbRule/sharding-rules-on-namespace.xml</value>
- </list>
- </property>
- </bean>
- <rules>
- <rule>
- <namespace>User</namespace>
- <!--
- 對使用者名稱username呼叫自定義路由規則,如果返回的結果為1,則進入分片資料庫1,以此類推1,2,3
- 表示式如果不使用自定義路由規則函式,而是直接使用 taobaoId%2==0這種的話就不用在檔案
- 中配置<property name="functionsMap">中了
- -->
- <shardingExpression>hash.applyUser(username) == 1</shardingExpression>
- <shards>partition1</shards>
- </rule>
- <rule>
- <namespace>User</namespace>
- <shardingExpression>hash.applyUser(username) == 2</shardingExpression>
- <shards>partition2</shards>
- </rule>
- <rule>
- <namespace>User</namespace>
- <shardingExpression>hash.applyUser(username) == 3</shardingExpression>
- <shards>partition3</shards>
- </rule>
- </rules>
- publicclass HashFunction{
- /**
- * 對三個資料庫進行雜湊分佈
- * 1、返回其他值,沒有在配置檔案中配置的,如負數等,在預設資料庫中查詢
- * 2、比如現在配置檔案中配置有三個結果進行雜湊,如果返回為0,那麼apply方法只調用一次,如果返回為2,
- * 那麼apply方法就會被呼叫三次,也就是每次是按照配置檔案的順序依次的呼叫方法進行判斷結果,而不會快取方法返回值進行判斷
- * @param id
- * @return
- */
- publicint applyUser(String username) {
- //先從快取獲取 沒有則查詢資料庫
- //input 可能是id,拿id到快取裡去查使用者的DB座標資訊。然後把庫的編號輸出
- int result = Math.abs(username.hashCode() % 1024);//0---1023
-
相關推薦
mysql主從複製、讀寫分離到資料庫水平拆分及庫表雜湊
web專案最原始的情況是一臺伺服器只能連線一個mysql伺服器(c3p0只能配置一個mysql),但隨著專案的增大,這種方案明顯已經不能滿足需求了。Mysql主從複製,讀寫分離:上面的方案使用mysql-Proxy代理,分發讀寫請求,寫操作轉發到Mysql主伺服器,讀操作轉發
Mysql主從複製、讀寫分離+MyCat資料庫中介軟體
最近搭建了 MySQL 主從 並使用MyCat作為資料庫中介軟體 版本: Mysql 5.5.48 Linux :CentOS 6.8 MyCat : 1.4 節點: 192.168.152.11Cluster1 192.168.152.12Cluster2 192.1
mysql主從複製、讀寫分離、分庫分表、分片
第1章 引言 隨著網際網路應用的廣泛普及,海量資料的儲存和訪問成為了系統設計的瓶頸問題。對於一個大型的網際網路應用,每天幾十億的PV無疑對資料庫造成了相當高的負載。對於系統的穩定性和擴充套件性造成了極大的問題。通過資料切分來提高網站效能,橫向擴充套件資料層已經成為架構研發人員首選的方式。 水平切分資料庫:可
使用Mycat實現Mysql資料庫的主從複製、讀寫分離、分表分庫、負載均衡和高可用
Mysql叢集搭建 使用Mycat實現Mysql資料庫的主從複製、讀寫分離、分表分庫、負載均衡和高可用(Haproxy+keepalived),總體架構: 說明:資料庫的訪問通過keepalived的虛擬IP訪問HAProxy負載均衡器,實現HAProxy的高可用,HAProxy用於實
【Mycat】資料庫效能提升利器(三)——Mycat實現Mysql主從複製和讀寫分離
一、前言 在前一篇文章中,小編向大家 介紹了使用Mycat水平切分資料庫。可以說,使用了水平分庫後,資料庫提升還是很高的。如果想更高的提高資料庫效能,就可以考慮對Mysql進行主從複製和讀寫分離了。 在這篇部落格中,小編就向大家介紹基於Mycat的M
部署MySQL主從複製與讀寫分離
一、實驗壞境 1.一臺CentOS 7作為客戶端測試,對應的地址為:192.168.80.1202.一臺CentOS 7作為Amoeba前端代理伺服器,對應的地址為:192.168.80.1103.一臺CentOS 7作為mysql主伺服器,對應的地址為:192.168.80.1004.兩臺CentOS 7
Redis - 主從複製、讀寫分離
主從複製 Redis通過配置主從複製,主(master)進行寫操作,從(slave)進行讀操作,實現讀寫分離,這樣配置可以減輕redis的壓力,同時可以解決單點故障問題。 實現原理 slave啟動成功連線
Mysql主從複製實現讀寫分離
一:安裝mysql, 在這裡我是在兩臺server上安裝mysql5.7(安裝過程不在詳細介紹) 主:10.2.0.134 從:10.2.0.149 二:配置master伺服器 1.建立使用者 CREATE USER 'cosmos'@'10.2.0.%' ;
Redis 主從複製、讀寫分離、高可用(七)-part 1
Redis主機資料更新後根據配置和策略,自動同步到備機的master/slaver機制,Master以寫為主,Slave以讀為主,這樣就可以減輕伺服器的壓力了。 redis主從複製之配置介紹 複製的原理介紹 slave啟動成功連線到master後會傳送一個sync命
mysql主從複製與讀寫分離
主從複製原理:在主資料庫執行後,都會寫入本地的日誌系統A中。假設,實時的將變化了的日誌系統中的資料庫事件操作,在主資料庫的3306埠,通過網路發給從資料。從資料庫收到後,寫入本地日誌系統B,然後一條條的將資料庫事件在資料庫中完成。那麼,主資料庫的變化,從資料庫
mysql主從複製與讀寫分離配置詳解
mysql主從複製與讀寫分離配置詳解 當網站達到一定規模時,資料庫最先出現壓力,這時候使用者會明顯感覺到卡頓,其原因是資料庫的寫入操作,影響了查詢的效率。這時可以考慮對資料庫配置主從複製和讀寫分離。設定多臺資料庫伺服器,包括一個主伺服器和n個從伺服器,主伺服器負責寫入資料,從伺服器負
SpringBoot微服務 +tomcat叢集+Ngnix負載均衡+Mysql主從複製,讀寫分離(4)
四:mysql主從複製,讀寫分離 1.首先把mysql原始碼包檔案拷到兩臺linux伺服器上,然後在兩臺伺服器上安裝Mysql資料庫 安裝 MySQL 1 安裝 ncurses Ncurses 提供字元終端處理庫,包括面板和選單。它提供了
CentOS6.5搭建MySQL主從複製,讀寫分離(冷月宮主親自整理,最簡單明瞭)
CentOS6.5搭建MySQL主從複製,讀寫分離MySQL主從複製的優點:1、 如果主伺服器出現問題, 可以快速切換到從伺服器提供的服務,保證高可用性2、 可以在從伺服器上執行查詢操作, 降低主伺服器的訪問壓力3、 可以在從伺服器上執行備份, 以避免備份期間影響主伺服器的服
實現在同一臺linux主機上mysql主從複製與讀寫分離
環境情況:由於資源有限,僅在一臺CentOS release 6.6上實現M-S主從複製與讀寫分離 一、mysql安裝與配置 具體安裝過程建議參考我的上篇一部落格文章 二、mysql主從複製 主從伺服器場景如下 主(m) :172.30.204.111:3307 從1
Redis哨兵模式(sentinel)學習總結及部署記錄(主從複製、讀寫分離、主從切換)
Redis的叢集方案大致有三種:1)redis cluster叢集方案;2)master/slave主從方案;3)哨兵模式來進行主
CentOS7,MySQL主從配置和讀寫分離(MySQL主從、讀寫分離、分散式、資料庫讀寫分離、主從配置)
一、實驗目標搭建兩臺MySQL伺服器,一臺作為主伺服器,一臺作為從伺服器,主伺服器進行寫操作,從伺服器進行讀操作。二、測試環境主資料庫: CentOS7, MySQL15.1 , 192.168.1.233從資料庫: CentOS7, MySQL15.1 , 192.168.
主從同步、讀寫分離、mysql性能調優(軟優化)
tab ren 主庫 its 使用命令 mysql lee 運行 lte 配置mysql主從同步1 主從同步的作用:讓slave身份的數據庫服務器自動同步 master身份的數據庫服務器上的數據。 一、主數據庫服務器的配置192.168.4.121 用戶授權mysql&g
MySQL高可用--主從複製與讀寫分離
一、Mysql高可用概念 二、MySQL主從複製原理 叢集目的,減輕單臺伺服器壓力 三、MySQL主從複製配置 實際操作mysql伺服器叢集,主從複製的過程 master 192.168.230.128 slav
MySQL的主從複製與讀寫分離
一、主從複製 1.伺服器資訊:主伺服器:192.168.48.4 從伺服器:192.168.48.5 均已安裝mysql 2.配置主伺服器中的 /etc/my.cnf 檔案,設定伺服器id和開啟日誌功能。設定完後儲存。進入mysql客戶端,通過show VARIAB
redis在Docker下的主從複製(讀寫分離)、哨兵(主從切換)
公司專案涉及到redis,最近不太忙於是準備仔細學習下,起初是直接在Windows下搭建,現在試試Docker下搭建redis然後試下哨兵配置,廢話不多說,直接搭建步驟: 1.Docker安裝redis 指令1)docker search redis 查詢