
Storm(四):容錯機制
Apache Storm分散式叢集主要節點由控制節點(Nimbus節點)和工作節點(Supervisor節點),在叢集下,怎麼保證拓撲的可靠性,storm提供哪些容錯機制?
我們部署了兩臺(Master、Salve2),然後啟動了兩個Supervisor和對應兩個worker


一、Nimbus節點出現故障(程序掛掉)
Nimbus節點出現故障,Supervisor節點還正常執行對應的worker也是正常工執行,只是Supervisor不能接受Nimbus新任務的分配。
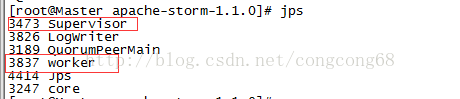
Master伺服器中的Nimbus程序掛掉了,對Supervisor、worker程序不影響。

二、Supervisor節點出現故障(程序掛掉)
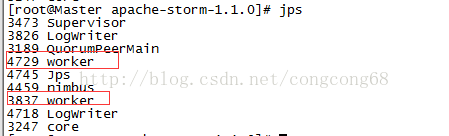
出故障的Supervisor節點對應的worker也就掛掉了,但Nimbus節點監控把對應的worker的重新分配到其他的Supervisor節點上執行。
我們把對應的Salve2中的supervisor程序掛掉

Nimbus節點監控把對應的worker的重新分配到Master的Supervisor節點上執行。

三、Nimbus和Supervisor節點都出現故障
Nimbus節點出現故障並某其中一個
四、Worker 程序掛掉
因拓撲記憶體溢位或者其它導致Worker 掛掉,Supervisor會重新啟動Worker。
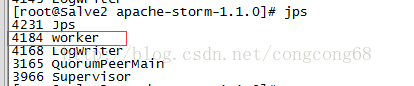
我們對Salve2的Worker程序掛掉,

然後等了一會,Supervisor會重新啟動Worker
總結:
Nimbus和Supervisor被設計成是快速失敗且無狀態的,他們的狀態都儲存在