
Flume環境部署和配置詳解及案例大全
一、什麼是Flume?
flume 作為 cloudera 開發的實時日誌收集系統,受到了業界的認可與廣泛應用。Flume 初始的發行版本目前被統稱為 Flume OG(original generation),屬於 cloudera。但隨著 FLume 功能的擴充套件,Flume OG 程式碼工程臃腫、核心元件設計不合理、核心配置不標準等缺點暴露出來,尤其是在 Flume OG 的最後一個發行版本 0.94.0 中,日誌傳輸不穩定的現象尤為嚴重,為了解決這些問題,2011 年 10 月 22 號,cloudera 完成了 Flume-728,對
Flume 進行了里程碑式的改動:重構核心元件、核心配置以及程式碼架構,重構後的版本統稱為 Flume NG(next generation);改動的另一原因是將 Flume 納入 apache 旗下,cloudera Flume 改名為 Apache Flume。
flume的特點:
flume是一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的系統。支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(比如文字、HDFS、Hbase等)的能力 。
flume的資料流由事件(Event)貫穿始終。事件是Flume的基本資料單位,它攜帶日誌資料(位元組陣列形式)並且攜帶有頭資訊,這些Event由Agent外部的Source生成,當Source捕獲事件後會進行特定的格式化,然後Source會把事件推入(單個或多個)Channel中。你可以把Channel看作是一個緩衝區,它將儲存事件直到Sink處理完該事件。Sink負責持久化日誌或者把事件推向另一個Source。
flume的可靠性
當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:end-to-end(收到資料agent首先將event寫到磁碟上,當資料傳送成功後,再刪除;如果資料傳送失敗,可以重新發送。),Store on failure(這也是scribe採用的策略,當資料接收方crash時,將資料寫到本地,待恢復後,繼續傳送),Besteffort(資料傳送到接收方後,不會進行確認)。
flume的可恢復性:
還是靠Channel。推薦使用FileChannel,事件持久化在本地檔案系統裡(效能較差)。
flume的一些核心概念:
Agent使用JVM 執行Flume。每臺機器執行一個agent,但是可以在一個agent中包含多個sources和sinks。
Client生產資料,執行在一個獨立的執行緒。
Source從Client收集資料,傳遞給Channel。
Sink從Channel收集資料,執行在一個獨立執行緒。
Channel連線 sources 和 sinks ,這個有點像一個佇列。
Events可以是日誌記錄、 avro 物件等。
Flume以agent為最小的獨立執行單位。一個agent就是一個JVM。單agent由Source、Sink和Channel三大元件構成,如下圖:
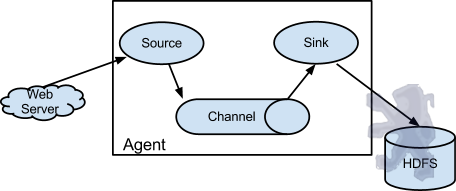
值得注意的是,Flume提供了大量內建的Source、Channel和Sink型別。不同型別的Source,Channel和Sink可以自由組合。組合方式基於使用者設定的配置檔案,非常靈活。比如:Channel可以把事件暫存在記憶體裡,也可以持久化到本地硬碟上。Sink可以把日誌寫入HDFS, HBase,甚至是另外一個Source等等。Flume支援使用者建立多級流,也就是說,多個agent可以協同工作,並且支援Fan-in、Fan-out、Contextual Routing、Backup Routes,這也正是NB之處。如下圖所示:
三、在哪裡下載?
四、如何安裝?
1)將下載的flume包,解壓到/home/hadoop目錄中,你就已經完成了50%:)簡單吧
2)修改 flume-env.sh 配置檔案,主要是JAVA_HOME變數設定
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
[email protected]:/home/hadoop/flume-1.5.0-bin# cp conf/flume-env.sh.template conf/flume-env.sh
[email protected]:/home/hadoop/flume-1.5.0-bin# vi conf/flume-env.sh
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# If this file is placed at FLUME_CONF_DIR/flume-env.sh, it will be sourced
# during Flume startup.
# Enviroment variables can be set here.
JAVA_HOME=/usr/lib/jvm/java-7-oracle
# Give Flume more memory and pre-allocate, enable remote monitoring via JMX
#JAVA_OPTS="-Xms100m -Xmx200m -Dcom.sun.management.jmxremote"
# Note that the Flume conf directory is always included in the classpath.
#FLUME_CLASSPATH=""
|
3)驗證是否安裝成功
?| 1 2 3 4 5 6 7 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng version
Flume 1.5.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 8633220df808c4cd0c13d1cf0320454a94f1ea97
Compiled by hshreedharan on Wed May 7 14:49:18 PDT 2014
From source
with checksum a01fe726e4380ba0c9f7a7d222db961f
[email protected]:/home/hadoop#
|
出現上面的資訊,表示安裝成功了
五、flume的案例
1)案例1:Avro
Avro可以傳送一個給定的檔案給Flume,Avro 源使用AVRO RPC機制。
a)建立agent配置檔案
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[email protected]:/home/hadoop#vi /home/hadoop/flume-1.5.0-bin/conf/avro.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type
= avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type
= logger
# Use a channel which buffers events in memory
a1.channels.c1.type
= memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
b)啟動flume agent a1
?| 1 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng agent -c . -f /home/hadoop/flume-1.5.0-bin/conf/avro.conf -n a1
-Dflume.root.logger=INFO,console
|
c)建立指定檔案
?| 1 |
[email protected]:/home/hadoop# echo "hello world" > /home/hadoop/flume-1.5.0-bin/log.00
|
d)使用avro-client傳送檔案
?| 1 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng avro-client -c . -H m1 -p 4141 -F /home/hadoop/flume-1.5.0-bin/log.00
|
f)在m1的控制檯,可以看到以下資訊,注意最後一行:
?| 1 2 3 4 5 6 7 8 9 10 |
[email protected]:/home/hadoop/flume-1.5.0-bin/conf# /home/hadoop/flume-1.5.0-bin/bin/flume-ng
agent -c . -f /home/hadoop/flume-1.5.0-bin/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console
Info: Sourcing environment configuration script
/home/hadoop/flume-1.5.0-bin/conf/flume-env.sh
Info: Including Hadoop libraries found via (/home/hadoop/hadoop-2.2.0/bin/hadoop)
for HDFS access
Info: Excluding
/home/hadoop/hadoop-2.2.0/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding
/home/hadoop/hadoop-2.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath
...
-08-10 10:43:25,112 (New I/O
worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x92464c4f, /192.168.1.50:59850 :> /192.168.1.50:4141] UNBOUND
-08-10 10:43:25,112 (New I/O
worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x92464c4f, /192.168.1.50:59850 :> /192.168.1.50:4141] CLOSED
-08-10 10:43:25,112 (New I/O
worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.channelClosed(NettyServer.java:209)] Connection to /192.168.1.50:59850 disconnected.
-08-10 10:43:26,718 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C
64 hello world }
|
2)案例2:Spool
Spool監測配置的目錄下新增的檔案,並將檔案中的資料讀取出來。需要注意兩點:
1) 拷貝到spool目錄下的檔案不可以再開啟編輯。
2) spool目錄下不可包含相應的子目錄
a)建立agent配置檔案
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[email protected]:/home/hadoop# vi /home/hadoop/flume-1.5.0-bin/conf/spool.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type
= spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir =
/home/hadoop/flume-1.5.0-bin/logs
a1.sources.r1.fileHeader =
true
# Describe the sink
a1.sinks.k1.type
= logger
# Use a channel which buffers events in memory
a1.channels.c1.type
= memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
b)啟動flume agent a1
| 1 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng agent -c . -f /home/hadoop/flume-1.5.0-bin/conf/spool.conf -n a1
-Dflume.root.logger=INFO,console
|
c)追加檔案到/home/hadoop/flume-1.5.0-bin/logs目錄
| 1 |
[email protected]:/home/hadoop# echo "spool test1" > /home/hadoop/flume-1.5.0-bin/logs/spool_text.log
|
d)在m1的控制檯,可以看到以下相關資訊:
| 1 2 3 4 5 6 7 8 9 10 11 |
/08/10 11:37:13 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:13 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:14 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /home/hadoop/flume-1.5.0-bin/logs/spool_text.log to /home/hadoop/flume-1.5.0-bin/logs/spool_text.log.COMPLETED
/08/10 11:37:14 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:14 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:14 INFO sink.LoggerSink: Event: { headers:{file=/home/hadoop/flume-1.5.0-bin/logs/spool_text.log} body: 73 70 6F 6F 6C 20 74 65 73 74 31 spool test1 }
/08/10 11:37:15 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:15 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:16 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:16 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
/08/10 11:37:17 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
|
3)案例3:Exec
EXEC執行一個給定的命令獲得輸出的源,如果要使用tail命令,必選使得file足夠大才能看到輸出內容
a)建立agent配置檔案
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[email protected]:/home/hadoop# vi /home/hadoop/flume-1.5.0-bin/conf/exec_tail.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type
= exec
a1.sources.r1.channels = c1
a1.sources.r1.command
= tail
-F /home/hadoop/flume-1.5.0-bin/log_exec_tail
# Describe the sink
a1.sinks.k1.type
= logger
# Use a channel which buffers events in memory
a1.channels.c1.type
= memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
b)啟動flume agent a1
| 1 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng agent -c . -f /home/hadoop/flume-1.5.0-bin/conf/exec_tail.conf
-n a1 -Dflume.root.logger=INFO,console
|
c)生成足夠多的內容在檔案裡
| 1 |
[email protected]:/home/hadoop# for i in {1..100};do echo "exec tail$i" >> /home/hadoop/flume-1.5.0-bin/log_exec_tail;echo $i;sleep 0.1;done
|
e)在m1的控制檯,可以看到以下資訊:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
-08-10 10:59:25,513 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 20
74 65 73 74 exec tail test }
-08-10 10:59:34,535 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 20
74 65 73 74 exec tail test }
-08-10 11:01:40,557 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 31
exec tail1 }
-08-10 11:01:41,180 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 32
exec tail2 }
-08-10 11:01:41,180 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 33
exec tail3 }
-08-10 11:01:41,181 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 34
exec tail4 }
-08-10 11:01:41,181 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 35
exec tail5 }
-08-10 11:01:41,181 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C 36
exec tail6 }
....
....
....
-08-10 11:01:51,550 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C
39 36 exec tail96 }
-08-10 11:01:51,550 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C
39 37 exec tail97 }
-08-10 11:01:51,551 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C
39 38 exec tail98 }
-08-10 11:01:51,551 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C
39 39 exec tail99 }
-08-10 11:01:51,551 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 65 78 65 63 20 74 61 69 6C
31 30 30 exec tail100 }
|
4)案例4:Syslogtcp
Syslogtcp監聽TCP的埠做為資料來源
a)建立agent配置檔案
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[email protected]:/home/hadoop# vi /home/hadoop/flume-1.5.0-bin/conf/syslog_tcp.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type
= syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.host = localhost
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type
= logger
# Use a channel which buffers events in memory
a1.channels.c1.type
= memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
b)啟動flume agent a1
| 1 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng agent -c . -f /home/hadoop/flume-1.5.0-bin/conf/syslog_tcp.conf
-n a1 -Dflume.root.logger=INFO,console
|
c)測試產生syslog
| 1 |
[email protected]:/home/hadoop# echo "hello idoall.org syslog" | nc localhost 5140
|
d)在m1的控制檯,可以看到以下資訊:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
/08/10 11:41:45 INFO node.PollingPropertiesFileConfigurationProvider: Reloading configuration file:/home/hadoop/flume-1.5.0-bin/conf/syslog_tcp.conf
/08/10 11:41:45 INFO conf.FlumeConfiguration: Added sinks: k1 Agent: a1
/08/10 11:41:45 INFO conf.FlumeConfiguration: Processing:k1
/08/10 11:41:45 INFO conf.FlumeConfiguration: Processing:k1
/08/10 11:41:45 INFO conf.FlumeConfiguration: Post-validation flume configuration contains configuration for agents: [a1]
/08/10 11:41:45 INFO node.AbstractConfigurationProvider: Creating channels
/08/10 11:41:45 INFO channel.DefaultChannelFactory: Creating instance of channel c1 type memory
/08/10 11:41:45 INFO node.AbstractConfigurationProvider: Created channel c1
/08/10 11:41:45 INFO source.DefaultSourceFactory: Creating instance of source r1, type syslogtcp
/08/10 11:41:45 INFO sink.DefaultSinkFactory: Creating instance of sink: k1, type: logger
/08/10 11:41:45 INFO node.AbstractConfigurationProvider: Channel c1 connected to [r1, k1]
/08/10 11:41:45 INFO node.Application: Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.SyslogTcpSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner:
{ policy:[email protected] counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
/08/10 11:41:45 INFO node.Application: Starting Channel c1
/08/10 11:41:45 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
/08/10 11:41:45 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started
/08/10 11:41:45 INFO node.Application: Starting Sink k1
/08/10 11:41:45 INFO node.Application: Starting Source r1
/08/10 11:41:45 INFO source.SyslogTcpSource: Syslog TCP Source starting...
/08/10 11:42:15 WARN source.SyslogUtils: Event created from Invalid Syslog data.
/08/10 11:42:15 INFO sink.LoggerSink: Event: { headers:{Severity=0, flume.syslog.status=Invalid, Facility=0} body: 68 65 6C 6C 6F 20 69 64 6F 61 6C 6C 2E 6F 72 67 hello idoall.org }
|
5)案例5:JSONHandler
a)建立agent配置檔案
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[email protected]:/home/hadoop# vi /home/hadoop/flume-1.5.0-bin/conf/post_json.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type
= org.apache.flume.source.http.HTTPSource
a1.sources.r1.port = 8888
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type
= logger
# Use a channel which buffers events in memory
a1.channels.c1.type
= memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
b)啟動flume agent a1
| 1 |
[email protected]:/home/hadoop# /home/hadoop/flume-1.5.0-bin/bin/flume-ng agent -c . -f /home/hadoop/flume-1.5.0-bin/conf/post_json.conf
-n a1 -Dflume.root.logger=INFO,console
|
c)生成JSON 格式的POST request
| 1 |
[email protected]:/home/hadoop# curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "idoall.org_body"}]'
http://localhost:8888
|
d)在m1的控制檯,可以看到以下資訊:
/
| 1 2 3 4 5 6 7 8 9 10 11 |
08/10 11:49:59 INFO node.Application: Starting Channel c1
/08/10 11:49:59 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
/08/10 11:49:59 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started
/08/10 11:49:59 INFO node.Application: Starting Sink k1
/08/10 11:49:59 INFO node.Application: Starting Source r1
/08/10 11:49:59 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
/08/10 11:49:59 INFO mortbay.log: jetty-6.1.26
/08/10 11:50:00 INFO mortbay.log: Started [email protected]:8888
/08/10 11:50:00 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
/08/10 11:50:00 INFO instrumentation.MonitoredCounterGroup: Component type: SOURCE, name: r1 started
/08/10 12:14:32 INFO sink.LoggerSink: Event: { headers:{b=b1, a=a1} body: 69 64 6F 61 6C 6C 2E 6F 72 67 5F 62 6F 64 79 idoall.org_body }
|
6)案例6:Hadoop sink
其中關於hadoop2.2.0部分的安裝部署,請參考文章《ubuntu12.04+hadoop2.2.0+zookeeper3.4.5+hbase0.96.2+hive0.13.1分散式環境部署》
a)建立agent配置檔案
1
2
3
4
5
6
相關推薦Flume環境部署和配置詳解及案例大全一、什麼是Flume? flume 作為 cloudera 開發的實時日誌收集系統,受到了業界的認可與廣泛應用。Flume 初始的發行版本目前被統稱為 Flume OG(original generation),屬於 cloudera。但隨著 FLume 功能的擴 MySQL官方教程及各平臺的安裝教程和配置詳解入口www 官方 apt源 nbsp chrom 版本選擇 rom gui apt 官方文檔入口: https://dev.mysql.com/doc/ 一般選擇MySQL服務器版本入口: https://dev.mysql.com/doc/refman/en/ flutter環境配置詳解及開發第一個專案flutter環境配置的具體步驟如下: 1). 下載flutter 2).下載後的檔案解壓,放在你想指定的目錄下(我以放在桌面為例) 3).配置環境變數 vim ~/.bash_profile 輸入後,出現上圖介面,則表明已經存在,我們直接點選大寫字母Q退出就OK! Redis容災部署哨兵(sentinel)機制配置詳解及原理介紹1.為什麼要用到哨兵 哨兵(Sentinel)主要是為了解決在主從複製架構中出現宕機的情況,主要分為兩種情況: 1.從Redis宕機 這個相對而言比較簡單,在Redis中從庫重新啟動後會自動加入到主從架構中,自動完成同步資料。在Redis2.8版本後, NFS服務器原理和安裝配置詳解附案例演練隨機選擇 span 通訊 操作系統 不同 網絡 定義 重新啟動 exportfs NFS服務器原理和安裝配置詳解附案例演練 1、什麽是NFS服務器 NFS就是Network File System的縮寫,它最大的功能就是可以通過網絡,讓不同的機器、不同的操作系統可以共享 DNS服務簡介和配置詳解dns基本原理 dns簡介 dns服務配置過程 DNS服務簡介和配置詳解1、什麽是DNS? DNS( Domain Name System)是“域名系統”的英文縮寫,是一種組織成域層次結構的計算機和網絡服務命名系統,使用的是UDP協議的53號端口,它用於TCP/IP網絡,它所提供的服務是用來將主機 ssh配置詳解及公私鑰批量分發www pass 自帶 ansi ble 配置詳解 ans nbsp ssh配置文件 第一:ssh配置文件詳解 第二:ssh公私密鑰的生成 第三:ssh公鑰分發之一:ssh自帶工具ssh-copy-id工具分發 第四:ssh公鑰分發之二:編寫sshpass腳本批量分發 Django 發送email配置詳解及各種錯誤類型cut disco nal tac and ucc odi 添加 bject 跟隨Django Book的內容發送郵件不成功,總結一下需要配置好settings.py文件,還要註意一些細節。 1、在settings文件最後添加以下內容,缺一不可! EMAIL_HOST= Android FileProvider 屬性配置詳解及FileProvider多節點問題眾所周知在android7.0,修改了對私有儲存的限制,導致在獲取資源的時候,不能通過Uri.fromFile來獲取uri了我們需要適配7.0+的機型需要這樣寫: 1:程式碼適配 if (Build.VERSION.SDK_INT > 23) {// 時間外掛--daterangepicker使用和配置詳解--------------------- 作者:呆呆_小茗 來源:CSDN 原文:https://blog.csdn.net/baidu_38990811/article/details/79509418 版權宣告:本文為博主原創文章,轉載請附上博文 Nginx反向代理和配置詳解(正向代理、反向代理、負載均衡原理、Nginx反向代理原理和配置講解)nginx概述 nginx是一款自由的、開源的、高效能的HTTP伺服器和反向代理伺服器;同時也是一個IMAP、POP3、SMTP代理伺服器;nginx可以作為一個HTTP伺服器進行網站的釋出處理,另外nginx可以作為反向代理進行負載均衡的實現。 Nginx是一款開原始碼的高效能HT Linux下MongoDB安裝和配置詳解1、建立MongoDB的安裝路徑 在/usr/local/ 建立資料夾mongoDB 2、上傳檔案到Linux上的/usr/local/source目錄下 3、解壓檔案 進入到/usr/local/source目錄,執行如下命令: tar -zxvf m http狀態碼301和302詳解及區別——辛酸的探索之路一直對http狀態碼301和302的理解比較模糊,在遇到實際的問題和翻閱各種資料瞭解後,算是有了一定的理解。這裡記錄下,希望能有新的認識。大家也共勉。 官方的比較簡潔的說明: 301 redirect: 301 代表永久性轉移(Permanently Cookie和Session詳解及區別目錄 Cookie機制 定義 原理 使用 建立Cookie,Cookies方法 訪問Cookie 刪除 Session機制 定義 執行機制 使用 建立Session,Session方法 訪問Session Java程式設計師從笨鳥到菜鳥之(七十四)細談Spring(六)spring之AOP基本概念和配置詳解也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興! 首先我們來看一下官方文件所給我們的關於AOP的一些概念性詞語的解釋:切面(Aspect):一個關注點的模組化,這個關注點可能會橫切多個物件。事務管 Linux下MongoDB安裝和配置詳解(一)一、MongoDB的安裝 1.下載安裝包 下載方式: curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.2.9.tgz 解壓縮壓縮包: tar zxvf mongodb-linux-x Ansible之playbook(劇本)介紹和配置詳解前言 在上篇博文中講解了ansible的多個常用的模組,這些模組讓ansible具有了管理,部署後端主機的能力,但是一個一個命令的執行明顯很浪費時間,那麼能不能有一個檔案類似於shell指令碼那樣可以把複雜的、重複的命令,簡單化、程式流程化起來呢?答案是肯定的,playbook劇本就 log4j2 配置詳解 及使用所以建議配置檔案為log4j2.xml,下面以此為例: 3使用步驟 3-1,匯入剛剛下載好的log4j jar 包。 3-2,建立log4j2.xml檔案並放置到專案的根目錄 3-2-1 配置詳解如下: <?xml version="1.0" encoding="UTF-8"?&g Flume資料採集各種配置詳解Flume簡介 Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統,Flume支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力。 系統功能 arcgis for js 從入門到放棄一:初識和配置詳解前言:去年因專案需要學習arcgis js,上手資料只有官網的api和demo,半年過去了資料還是很少,於是寫這個系列希望能幫助新手能快速入門。這東西我玩的時間也不長,各種不足和錯誤也希望大家能批評指正。 首先給出官網地址(https://developers. |