
已有CM叢集環境中新增kafka元件---Kafka記憶體溢位
感謝分享:http://blog.csdn.net/pengych_321/article/details/52539932
參考
場景
怎麼區域性升級當前cm叢集呢,比如新增kafka元件、Spark元件等
分析
一、升級原因
1、 現有叢集元件只能做一些離線類統計分析,無法滿足當前實時類業務計算的需求。
2、 現有叢集計算引擎是基於MR2,計算能力相對較弱。
綜合以上因素,決定在已有的叢集元件中新增 : flume、kafka 與 spark 元件,以期提升叢集的計算能力,滿足當前實時計算的業務需求。
二、升級過程
1 、spark元件的新增
在叢集的每個節點上安裝 spark 元件,以YARN模式管理計算資源
1.1 在 CM主頁選擇新增服務
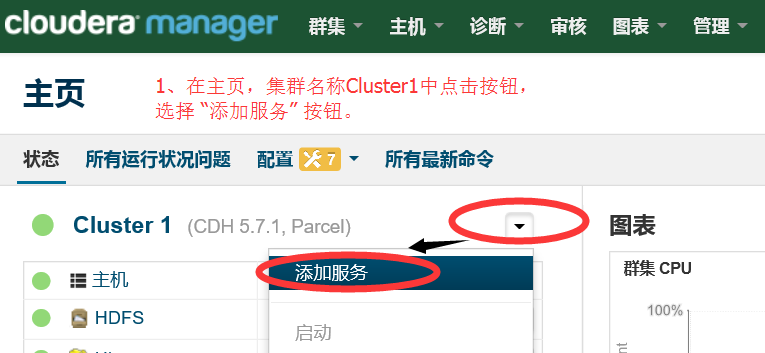
1.2 新增spark元件

1.3 選擇要安裝spark服務的節點
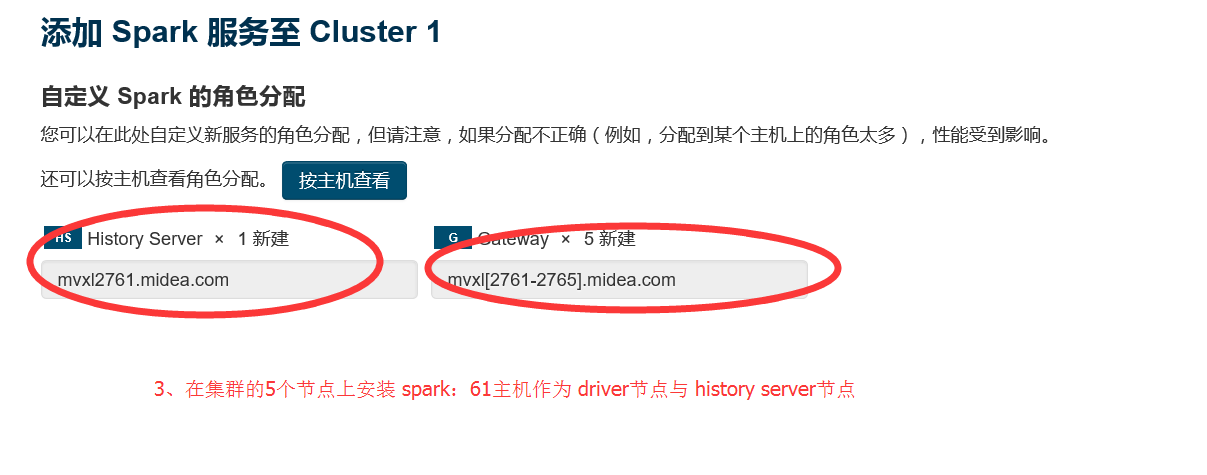
1.4 安裝完畢
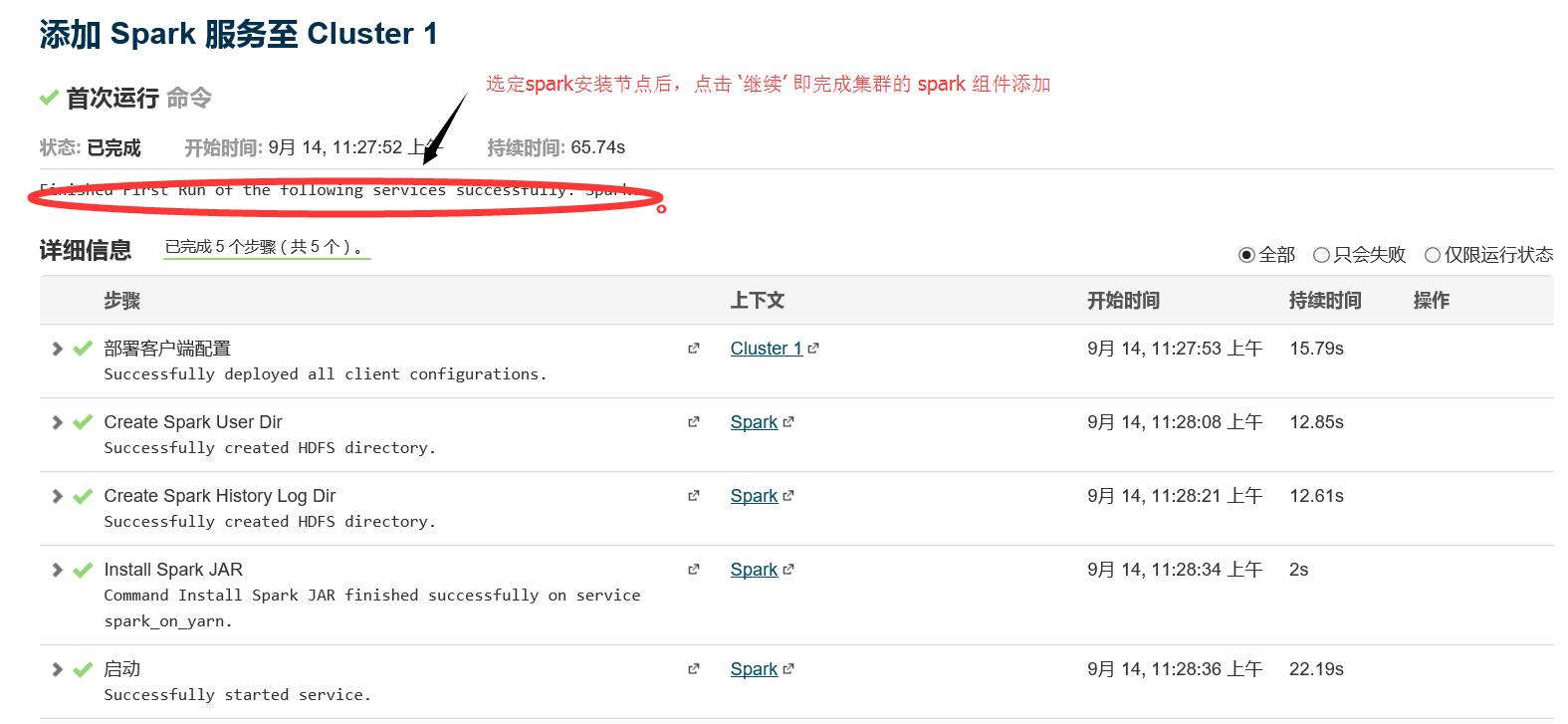
2、 kafka元件的新增
kafka元件的安裝,可分為線上與離線安裝,這裡採用線上安裝的方式進行,具體安裝步驟如下:
2.1 進入 Parcel 主頁
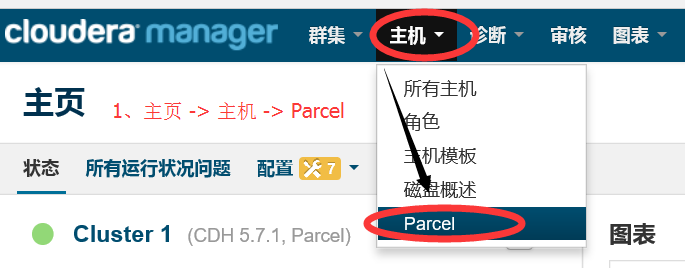
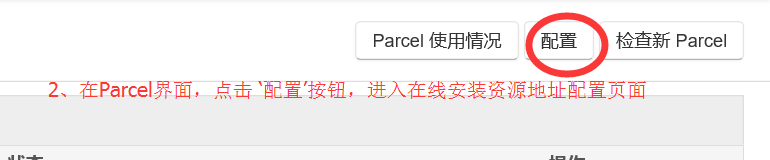
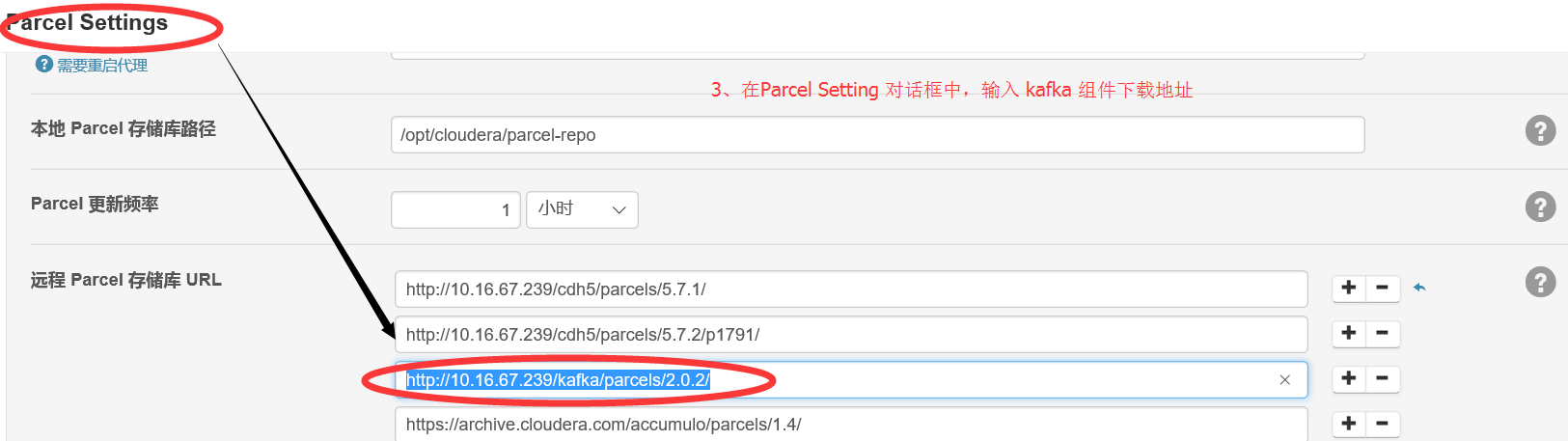
2.2 與 2.3 進入 Parcel配置介面
2.4 在Parcel主介面點選 ‘檢查更新Parcel’

2.5 啟用 kafka 元件

2.6 在CM主頁新增 kafka服務

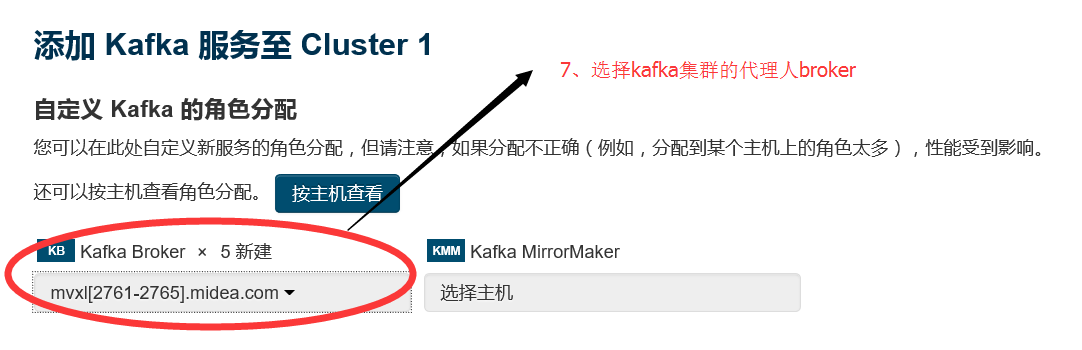
2.7 選擇需要安裝kafka元件的叢集節點 ,相關配置都選擇預設的
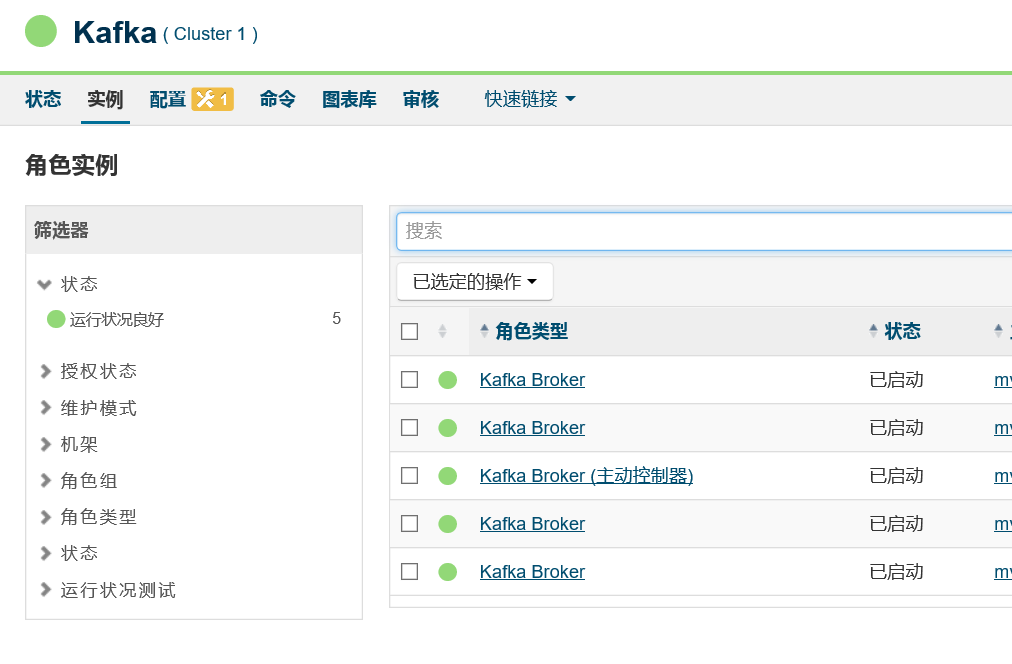
2.8 啟動 kafka 叢集
注意: 啟動kafka叢集的時候,可能出現如下異常 :
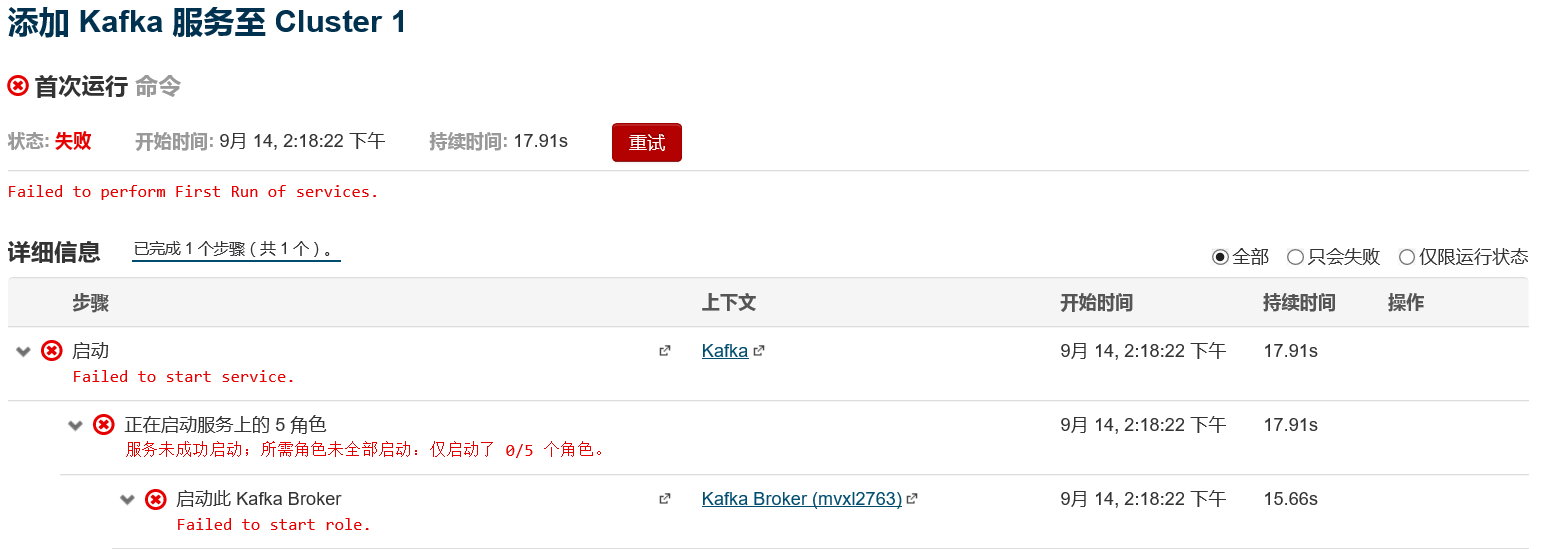
在CM 介面中檢視 broker的異常日誌後,發現:OutofMemeryException
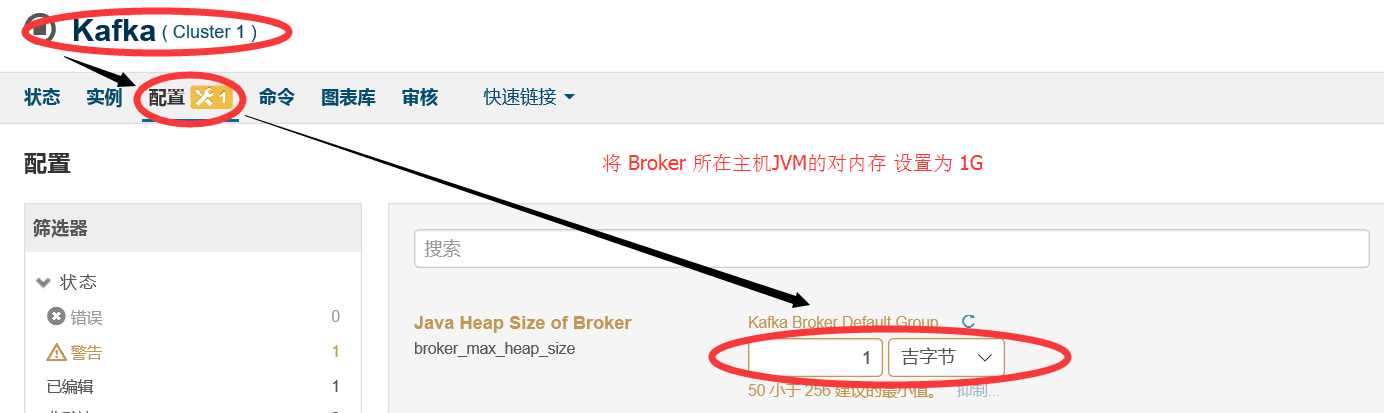
這是因為 Java Heap size of Broker這個選項預設配置是 50M ,需要將其修改成 256M 或者 更多,這裡修改成 1G ,儲存配置後,在啟動kafka叢集即可:
三、升級後的叢集元件配置狀況
生產環境 5 臺 32核 256G ,處理一般複雜度的spark作業,能處理的最大資料規模是多大呢? 這個沒法量化,以後遇到具體效能問題,再具體分析、優化。
以往的經驗:5臺8核16G的叢集資源,編寫一般複雜度的spark作業,處理 10G(大概一億行資料量)級別的資料量,處理時間是 10分鐘級別。
總結
開啟叢集資源管理之路,漫長啊 。。。