
python正則表示式擴充套件符號擴充套件和一些訓練小mark
關於正則式的簡要介紹:
1.擴充套件符號
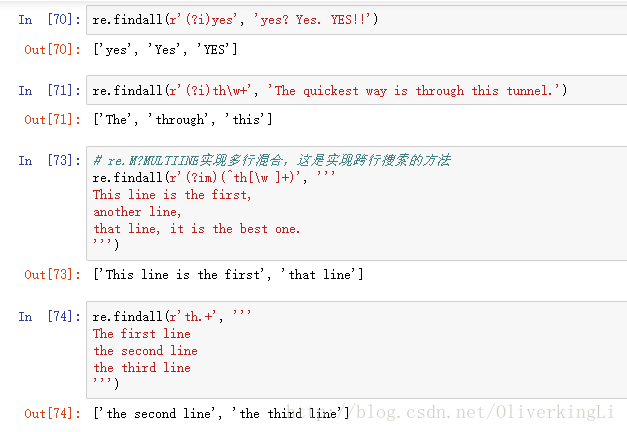

2.一些正則式訓練
# -*- coding: utf-8 -*- """ Created on Sat Jan 6 19:20:43 2018 @author: lisir """ ''' windows環境下列印使用者登陸資訊等 ''' import re import os with os.popen('tasklist /nh', 'r') as f: # \s\s+表示至少擁有兩個以上的空白符 for eachLine in f: print(re.split(r'\s\s+|\t', eachLine.strip()))
相關推薦
python正則表示式擴充套件符號擴充套件和一些訓練小mark
關於正則式的簡要介紹: 1.擴充套件符號 2.一些正則式訓練 # -*- coding: utf-8 -*- """ Created on Sat Jan 6 19:20:43 2018 @
Python正則表示式的簡單應用和示例演示
前一陣子小編給大家連續分享了十篇關於Python正則表示式基礎的文章,感興趣的小夥伴可以點選連結進去檢視。今天小編給大家分享的是Python正則表示式的簡單應用和示例演示,將前面學習的Python正則表示式做一個概括。 下面的栗子是用於提取高考日期,一般來說,我們填寫日期都會寫2018年6月7日,但
python正則表示式的懶惰匹配和貪婪匹配
第一次碰到這個問題的時候,確實不知道該怎麼辦,後來請教了一個大神,加上自己的理解,才瞭解是什麼意思,這個東西寫python的會經常用到,而且會特別頻繁,在此寫一篇部落格,希望可以幫到一些朋友。例:一個字串 “abcdacsdnd” ①懶惰匹配 regex
Python正則表示式--每日一點 檢索和替換
簡單的對上期的search和match進行一下簡單補充,兩者最大的區別在於match是從開始部分進行匹配,沒有匹配到就返回空,而search是整句掃描進行匹配 好了,開始今天的內容 大
Python正則表示式的貪婪模式和非貪婪模式
貪婪模式是把所有匹配的獲取到,非貪婪模式只取到第一個匹配到的字串,在python中findall和match的區別。 http://blog.csdn.net/qq_33447462/article/details/51485900 .*與.*?的區別:
Python正則表示式做文字預處理,去掉特殊符號
在進行文字訓練和處理之前難免要進行下預處理,過濾掉沒有用的符號等,簡單用python 的正則表示式過濾一下。 #!/usr/bin/python # encoding: UTF-8 import re # make English text clean def clean_en_text(te
Python正則表示式裡的單行re.S和多行re.M模式
Python正則表示式裡的單行re.S和多行re.M模式 Python 的re模組內建函式幾乎都有一個flags引數,以位運算的方式將多個標誌位相加。其中有兩個模式:單行(re.DOTALL, 或者re.S)和多行(re.MULTILINE, 或者re.M)模式。它們初看上去不好理解,但是有
正則表示式常用符號和字元
正則表示式 正則表示式是由一些字元和特殊符號組成的字串,他們描述了模式的重複或表述多個字元,於是正則表示式能按照某種模式匹配一系列有相似特徵的字串。也即它們能匹配多個字串。 常用特殊字元和符號 0.擇一匹配 (|) | 從多
Python正則表示式中的常用符號
Python正則表示式中常用的符號 簡介 正則表示式之所以叫做正則表示式,是因為他們可以識別正則字串;源字一本書中的定義是:“如果你給我的字串符合規則,我就返回它”,或者是“如果字串不符合規則,我就忽略它”。Python正則表示式在編寫網路爬蟲程式碼時使用可
正則表示式的基本語法和在Python下的使用
正則表示式基本語法 常用正則表示式符號 符號 說明 舉例 literal 匹配字串的值 Foo re1|re2 匹配正則表示式re1或re2 fo
Python正則表示式中的貪心模式和非貪心模式
宣告:最近發現有人利用我在百度雲盤裡免費分享的127課Python視訊盈利,並聲稱獲得我的授權。
python正則表示式二:literal、re1|re2 和 .
程式碼:import re #literal字面值 m=re.findall('a','abacd') print(m) #re1|re2或 m=re.findall('d|ac','abacd')
python正則表示式模組re中search和match方法的區別
re.search(pattern, string, flags=0)¶ Scan through string looking for the first location where the regular expression pattern produces a m
python 正則表示式注意事項和re.match()和re.search()區別
首先,正則我們一般用到re.match()和re.search() 其中re.match()是從開始進行匹配的,re.search()是從中間開始匹配. 另外關於懶惰匹配的問題,需要懶惰的地方加"?
python正則表示式re 中m.group和m.groups的解釋
先看程式碼 instance: 究其因: 正則表示式中的三組括號把匹配結果分成三組 m.group() == m.group(0) == 所有匹配的字元(即匹配正則表示式整體結果) group(1) 列出第一個括號匹配部分,group(2)
python 正則表示式 groups和group有什麼區別
p = re.compile(r'[ ]+(\w+)+[ ]+\1') 單個字元不需要[],可以簡化為 p = re.compile(r' +(\w+)+ +\1') (\w+)+這種寫法效率很低,而且容易引起誤會。表面上它匹配的是任意多個word(1個或更多),其實整體匹配的內容和一個word沒區別,只是
python 正則表示式點號與'\n'符號的問題
.匹配除了製表符和換行符之外的所有字元。*前面的元字元出現任意次,含0+前面的元字元出現一次或多次?非貪婪模式 .*? re.S可以匹配多行[\S\s]:匹配所有字元。所以(.*?)可以使用([\s\S]*?)取代 在Python中可以使用方法re.compile
Python正則表示式初識(九)
繼續分享Python正則表示式的基礎知識,今天給大家分享的特殊字元是[\u4E00-\u9FA5],這個特殊字元最好能夠記下來,如果記不得的話通過百度也是可以一下子查到的。 該特殊字元是固定的寫法,其代表的意思是漢字。換句話說,只要字元中是漢字,就可以通過該字元進行匹配,該特殊字元也是用中括號括起來的。
Python 正則表示式:compile,match
本文以匹配×××ID為例,介紹re模組的compile與match的用法 複雜匹配 = re.compile(正則表示式): 將正則表示式例項化 +
Python 正則表示式模組詳解
由於最近需要使用爬蟲爬取資料進行測試,所以開始了爬蟲的填坑之旅,那麼首先就是先系統的學習下關於正則相關的知識啦。所以將下面正則方面的知識點做了個整理。語言環境為Python。主要講解下Python的Re模組。 下面的語法我就主要列出一部分,剩下的在python官網直接查閱即可:docs.python.org