
深度學習筆記(六):Encoder-Decoder模型和Attention模型
這兩天在看attention模型,看了下知乎上的幾個回答,很多人都推薦了一篇文章Neural Machine Translation by Jointly Learning to Align and Translate 我看了下,感覺非常的不錯,裡面還大概闡述了encoder-decoder(編碼)模型的概念,以及傳統的RNN實現。然後還闡述了自己的attention模型。我看了一下,自己做了一些摘錄,寫在下面
1.Encoder-Decoder模型及RNN的實現
所謂encoder-decoder模型,又叫做編碼-解碼模型。這是一種應用於seq2seq問題的模型。
那麼seq2seq又是什麼呢?簡單的說,就是根據一個輸入序列x,來生成另一個輸出序列y。seq2seq有很多的應用,例如翻譯,文件摘取,問答系統等等。在翻譯中,輸入序列是待翻譯的文字,輸出序列是翻譯後的文字;在問答系統中,輸入序列是提出的問題,而輸出序列是答案。
為了解決seq2seq問題,有人提出了encoder-decoder模型,也就是編碼-解碼模型。所謂編碼,就是將輸入序列轉化成一個固定長度的向量;解碼,就是將之前生成的固定向量再轉化成輸出序列。
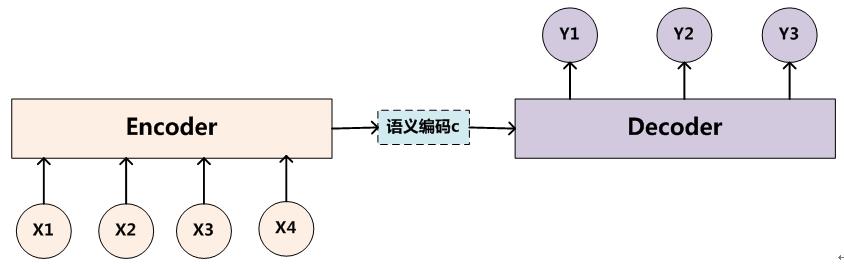
當然了,這個只是大概的思想,具體實現的時候,編碼器和解碼器都不是固定的,可選的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由組合。比如說,你在編碼時使用BiRNN,解碼時使用RNN,或者在編碼時使用RNN,解碼時使用LSTM等等。
這邊為了方便闡述,選取了編碼和解碼都是RNN的組合。在RNN中,當前時間的隱藏狀態是由上一時間的狀態和當前時間輸入決定的,也就是
獲得了各個時間段的隱藏層以後,再將隱藏層的資訊彙總,生成最後的語義向量
一種簡單的方法是將最後的隱藏層作為語義向量C,即
解碼階段可以看做編碼的逆過程。這個階段,我們要根據給定的語義向量C和之前已經生成的輸出序列
也可以寫作
而在RNN中,上式又可以簡化成
其中
encoder-decoder模型雖然非常經典,但是侷限性也非常大。最大的侷限性就在於編碼和解碼之間的唯一聯絡就是一個固定長度的語義向量C。也就是說,編碼器要將整個序列的資訊壓縮排一個固定長度的向量中去。但是這樣做有兩個弊端,一是語義向量無法完全表示整個序列的資訊,還有就是先輸入的內容攜帶的資訊會被後輸入的資訊稀釋掉,或者說,被覆蓋了。輸入序列越長,這個現象就越嚴重。這就使得在解碼的時候一開始就沒有獲得輸入序列足夠的資訊, 那麼解碼的準確度自然也就要打個折扣了
2.Attention模型
為了解決這個問題,作者提出了Attention模型,或者說注意力模型。簡單的說,這種模型在產生輸出的時候,還會產生一個“注意力範圍”表示接下來輸出的時候要重點關注輸入序列中的哪些部分,然後根據關注的區域來產生下一個輸出,如此往復。模型的大概示意圖如下所示
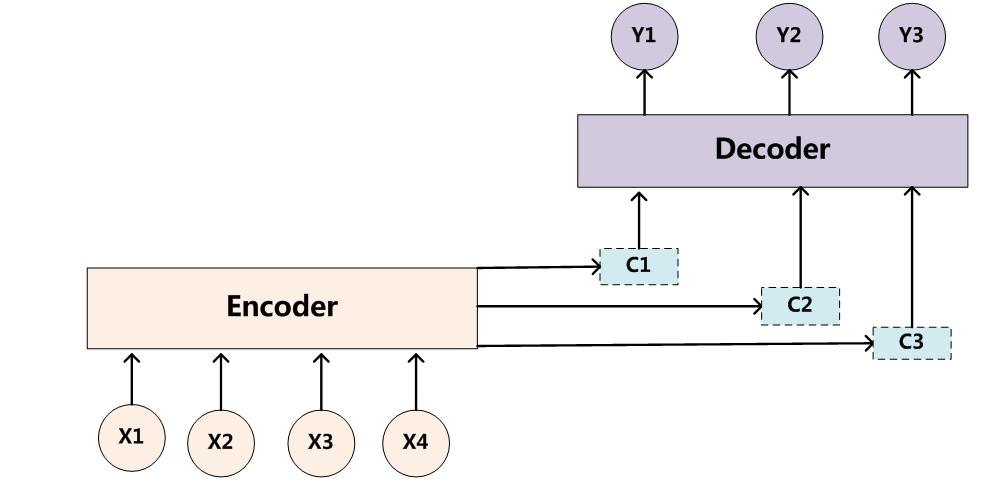
相比於之前的encoder-decoder模型,attention模型最大的區別就在於它不在要求編碼器將所有輸入資訊都編碼進一個固定長度的向量之中。相反,此時編碼器需要將輸入編碼成一個向量的序列,而在解碼的時候,每一步都會選擇性的從向量序列中挑選一個子集進行進一步處理。這樣,在產生每一個輸出的時候,都能夠做到充分利用輸入序列攜帶的資訊。而且這種方法在翻譯任務中取得了非常不錯的成果。
在這篇文章中,作者提出了一個用於翻譯任務的結構。解碼部分使用了attention模型,而在編碼部分,則使用了BiRNN(bidirectional RNN,雙向RNN)
2.1 解碼
我們先來看看解碼。解碼部分使用了attention模型。類似的,我們可以將之前定義的條件概率寫作
上式
注意這裡的條件概率與每個目標輸出
由於編碼使用了雙向RNN,因此可以認為