
LR和SVM、線性迴歸的聯絡與區別
LR和SVM的聯絡:
- 都是監督的分類演算法
- 都是線性分類方法 (不考慮核函式時)
- 都是判別模型
判別模型和生成模型是兩個相對應的模型。
判別模型是直接生成一個表示P(Y|X)P(Y|X)或者Y=f(X)Y=f(X)的判別函式(或預測模型)
生成模型是先計算聯合概率分佈P(Y,X)P(Y,X)然後通過貝葉斯公式轉化為條件概率。
SVM和LR,KNN,決策樹都是判別模型,而樸素貝葉斯,隱馬爾可夫模型是生成模型。
LR和SVM的不同
1、損失函式的不同
LR是cross entropy
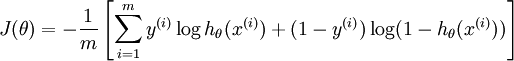
SVM的損失函式是最大化間隔距離
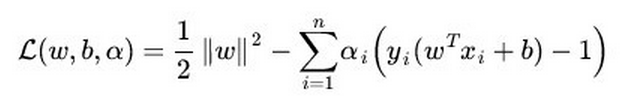
邏輯迴歸方法基於概率理論,假設樣本為1的概率可以用sigmoid函式來表示,然後通過極大似然估計的方法估計出引數的值
支援向量機基於幾何間隔最大化原理,認為存在最大幾何間隔的分類面為最優分類面
2、SVM不能產生概率,LR可以產生概率
LR本身就是基於概率的,所以它產生的結果代表了分成某一類的概率,而SVM則因為優化的目標不含有概率因素,所以其不能直接產生概率。
3、SVM自帶結構風險最小化,LR則是經驗風險最小化
在假設空間、損失函式和訓練集確定的情況下,經驗風險最小化即最小化損失函式
結構最小化是為了防止過擬合,在經驗風險的基礎上加上表示模型複雜度的正則項
4、SVM會用核函式而LR一般不用核函式
SVM轉化為對偶問題後,分類只需要計算與少數幾個支援向量的距離,這個在進行復雜核函式計算時優勢很明顯,能夠大大簡化模型和計算量。
5、LR和SVM在實際應用的區別
根據經驗來看,對於小規模資料集,SVM的效果要好於LR,但是大資料中,SVM的計算複雜度受到限制,而LR因為訓練簡單,可以線上訓練,所以經常會被大量採用
6、SVM的處理方法是隻考慮support vectors,也就是和分類最相關的少數點,去學習分類器。而邏輯迴歸通過非線性對映,大大減小了離分類平面較遠的點的權重,相對提升了與分類最相關的資料點的權重。
參考:https://blog.csdn.net/haolexiao/article/details/70191667
@AntZ: LR工業上一般指Logistic Regression(邏輯迴歸)而不是Linear Regression(線性迴歸). LR線上性迴歸的實數範圍輸出值上施加sigmoid函式將值收斂到0~1範圍, 其目標函式也因此從差平方和函式變為對數損失函式, 以提供最優化所需導數(sigmoid函式是softmax函式的二元特例, 其導數均為函式值的f*(1-f)形式)。請注意, LR往往是解決二元0/1分類問題的, 只是它和線性迴歸耦合太緊, 不自覺也冠了個迴歸的名字(馬甲無處不在). 若要求多元分類,就要把sigmoid換成大名鼎鼎的softmax了。
@nishizhen:個人感覺邏輯迴歸和線性迴歸首先都是廣義的線性迴歸,
其次經典線性模型的優化目標函式是最小二乘,而邏輯迴歸則是似然函式,
另外線性迴歸在整個實數域範圍內進行預測,敏感度一致,而分類範圍,需要在[0,1]。邏輯迴歸就是一種減小預測範圍,將預測值限定為[0,1]間的一種迴歸模型,因而對於這類問題來說,邏輯迴歸的魯棒性比線性迴歸的要好。
@乖乖癩皮狗:邏輯迴歸的模型本質上是一個線性迴歸模型,邏輯迴歸都是以線性迴歸為理論支援的。但線性迴歸模型無法做到sigmoid的非線性形式,sigmoid可以輕鬆處理0/1分類問題。