
Mybatis學習記錄(四)--高階查詢和快取
這些都是連貫的學習筆記,所以有的地方因為之前都說過,所以也就沒怎麼寫詳細了,看不太明白的可以看看之前的筆記.
一.高階查詢
高階查詢主要是一對一查詢,一對多查詢,多對多查詢
1.一對一查詢
有使用者和訂單兩個表,使用者對訂單是1對1查詢.也就是訂單中有一個外來鍵是指向使用者的.
先建立實體類:
User.java
public class User {
private int id;
private String username;
private String password;
private String nickname;
private Orders.java
public class Orders {
private int id;
private Date buy_date;
private Date pay_date;
private Date confirm_date;
private int status;
private int user_id;//外來鍵,指向使用者
//省略get和set方法
}1.使用resultType
這種方式對映的話,我們需要一個pojo的包裝類,在包裝類裡面增加我們要關聯的屬性,這裡增加使用者名稱和暱稱,把要關聯的屬性聚集在一起.具體如下,
OrdersCustorm.java
public class OrdersCustorm extends Orders {
private String username;
private String nickname;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getNickname() {
return 接下來SQL語句就可以使用內連線查詢.不過返回的型別是寫好的pojo包裝類,這樣的方法使用起來省事
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="orders">
<select id="findOrderAndUser" parameterType="int" resultType="com.aust.model.OrdersCustorm">
SELECT t_orders.*,user.username,user.nickname
FROM t_orders,user
WHERE user_id = user.id AND user_id=#{id}
</select>
</mapper>junit測試
@Before
public void init(){
InputStream is = null;
try {
is = Resources.getResourceAsStream("SqlMapperConfig.xml");
} catch (IOException e) {
e.printStackTrace();
}
factory = new SqlSessionFactoryBuilder().build(is);
}
//測試取出單個
@Test
public void findOrderAndUserTest(){
//獲取sqlsession
SqlSession session = factory.openSession();
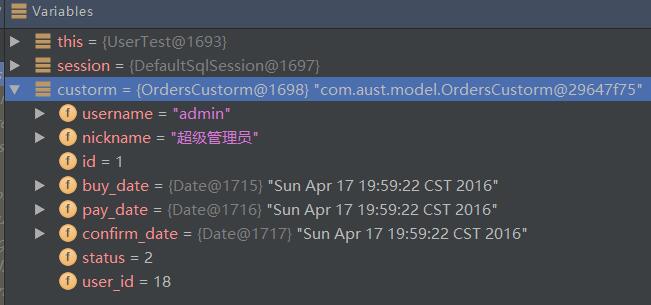
OrdersCustorm custorm = session.selectOne("orders.findOrderAndUser",18);
session.close();
System.out.println(custorm.toString());
}測試結果
2.使用resultMap
使用resultMap的話,就需要在Orders裡面定義一個User屬性,用於關聯查詢,具體如下:
Orders.java
public class Orders {
private int id;
private Date buy_date;
private Date pay_date;
private Date confirm_date;
private int status;
private int user_id;//外來鍵,指向使用者
private User user;//用於關聯查詢
}然後定義resultMap
autoMapping=”true”這個是開啟自動對映,不然只會對映你配置的那些屬性
association property=”user” javaType=”com.aust.model.User”這句話就是關聯到屬性user,也就是在Orders裡面新增加的關聯變數,對映型別為com.aust.model.User這個類.
<resultMap id="OrderAndUserMap" type="com.aust.model.Orders" autoMapping="true">
<id column="id" property="id"/>
<association property="user" javaType="com.aust.model.User">
<id column="user_id" property="id"/>
<result column="username" property="username"/>
<result column="nickname" property="nickname"/>
</association>
</resultMap>junit測試
@Before
public void init(){
InputStream is = null;
try {
is = Resources.getResourceAsStream("SqlMapperConfig.xml");
} catch (IOException e) {
e.printStackTrace();
}
factory = new SqlSessionFactoryBuilder().build(is);
}
//測試取出單個
@Test
public void findOrderAndUserTest(){
//獲取sqlsession
SqlSession session = factory.openSession();
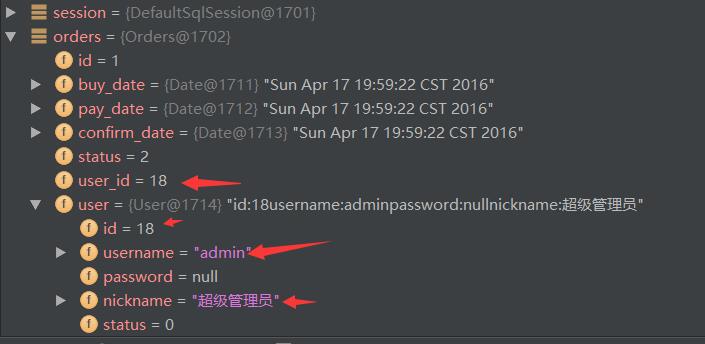
Orders orders = session.selectOne("orders.findOrderAndUserMap",18);
session.close();
System.out.println(orders.toString());
}
2.一對多查詢
現在的需求是查詢使用者和地址,一個使用者對應多個地址.一對多查詢只能使用resultMap了,不然會出現很多重複資料.使用前,需要修改User實體類,增加一個集合儲存多條地址資訊
User.java
public class User {
private int id;
private String username;
private String password;
private String nickname;
private int status;
private List<Adress> adresses;//用於儲存使用者的多個地址資訊
}然後定義resultMap
collection property=”adresses” ofType=”com.aust.model.Adress”:
collection標籤用於對映到一個集合的資訊,property要對映的屬性,也就是user裡面的List adresses,ofType要對映到集合裡面的pojo型別,這裡是com.aust.model.Adress
<resultMap id="userMap" type="com.aust.model.User" autoMapping="true">
<id column="userid" property="id"/>
<collection property="adresses" ofType="com.aust.model.Adress" autoMapping="true">
<id column="id" property="id"/>
</collection>
</resultMap>接著寫sql語句,仍然使用內連線
<select id="findUserAndAddress" parameterType="int" resultMap="userMap">
SELECT user.id userid,user.username,user.nickname,t_address.*
from user,t_address
WHERE t_address.user_id = user.id AND user.id=#{id};
</select>junit測試
@Before
public void init(){
InputStream is = null;
try {
is = Resources.getResourceAsStream("SqlMapperConfig.xml");
} catch (IOException e) {
e.printStackTrace();
}
factory = new SqlSessionFactoryBuilder().build(is);
}
@Test
public void findAddressAndUserTest(){
//獲取sqlsession
SqlSession session = factory.openSession();
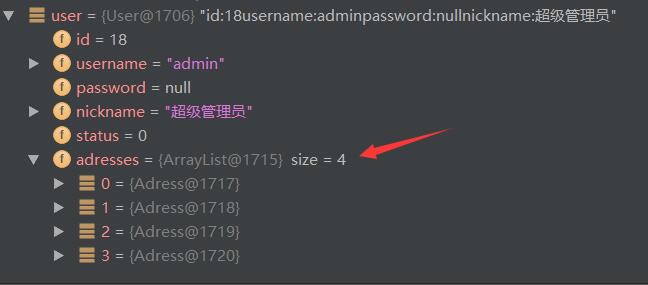
User user = session.selectOne("UserMapper.findUserAndAddress",18);
session.close();
System.out.println(user.toString());
}測試結果,成功取出多條地址資訊
3.多對多查詢
手頭上沒有很好的例子,所以也就直接說說思路.通過上面的1對1和1對n兩個可以看出,n對n無非就是collection,association的巢狀使用,每一個collection,association實際上就相當於一個區域性的resultMap,只要明白這一點的話,多對多實現是也就很簡單了.
4.總結
resultType:
作用:
將查詢結果按照sql列名pojo屬性名一致性對映到pojo中。
場合:
常見一些明細記錄的展示,比如使用者購買商品明細,將關聯查詢資訊全部展示在頁面時,此時可直接使用resultType將每一條記錄對映到pojo中,在前端頁面遍歷list(list中是pojo)即可。
resultMap:
使用association和collection完成一對一和一對多高階對映(對結果有特殊的對映要求)。
association:
作用:
將關聯查詢資訊對映到一個pojo物件中。
場合:
為了方便查詢關聯資訊可以使用association將關聯訂單資訊對映為使用者物件的pojo屬性中,比如:查詢訂單及關聯使用者資訊。
使用resultType無法將查詢結果對映到pojo物件的pojo屬性中,根據對結果集查詢遍歷的需要選擇使用resultType還是resultMap。
collection:
作用:
將關聯查詢資訊對映到一個list集合中。
場合:
為了方便查詢遍歷關聯資訊可以使用collection將關聯資訊對映到list集合中,比如:查詢使用者許可權範圍模組及模組下的選單,可使用collection將模組對映到模組list中,將選單列表對映到模組物件的選單list屬性中,這樣的作的目的也是方便對查詢結果集進行遍歷查詢。
如果使用resultType無法將查詢結果對映到list集合中。
5.補充例子(javaType和ofType)
最近做到一個聯合查詢,使用者登入後要把其完成的題目一起查詢出來,只需要查詢題目的id,也就是映射出private List<Integer> pro_ac;這樣的形式,
對應的對映就如下,利用javaType來對映,而不是ofType
<resultMap id="userMap" type="com.aust.model.CumUser" autoMapping="true">
<id column="id" property="id"/>
<collection property="pro_ac" javaType="java.util.List" ofType="java.lang.Integer" autoMapping="true">
<id column="pro_id" javaType="java.lang.Integer"/>
</collection>
</resultMap>ofType 是物件的所屬型別 javaType :collection 的型別
如:
<collection property="questions" ofType="map" javaType="list">對應的java 形態為 :List<Map<String,Object>>
二 .延遲載入
關於延遲載入,百度搜了好多,但是都亂七八糟的資訊.延遲載入解決的是N+1問題,所謂N+1問題舉個例子,
mybatis不推薦使用巢狀的select查詢,如下面所述,
select * from teacher此時可查詢出多條(記為N)教師記錄。為了進一步查詢出教師指導的學生的資訊,需要針對每一條教師記錄,生成一條SQL語句
select * from student where supervisor_id=?
以上SQL語句中的“?”就代表了每個教師的id。顯而易見,這樣的語句被生成了N條(“N+1問題”中的N)。這樣在整個過程中,就總共執行了N+1條SQL語句,即N+1次資料庫查詢。而資料庫查詢通常是應用程式效能的瓶頸,一般應儘量減少資料庫查詢的次數,那麼這種方式就會大大降低系統的效能。
解決方案:
第一種方法是使用一條SQL語句,把教師及其指導的學生的資訊一次性地查詢出來。
第二種方法是使用MyBatis的延遲載入機制.
1.延遲載入的配置
在SqlMapConfig.xml中配置
//開啟熱部署
<setting name="lazyLoadingEnabled" value="true"/>
//關閉積極載入,也就是設定為按需要載入
<setting name="aggressiveLazyLoading" value="false"/>2.寫sql查詢
還用的是使用者和地址之間的查詢
//根據使用者id查詢
<select id="findUser" resultMap="userMap">
SELECT * FROM user;
</select>
//根據使用者id查詢訂單
<select id="findAddress" parameterType="int" resultType="com.aust.model.Adress">
SELECT * FROM t_address WHERE t_address.user_id=#{id}
</select>
//resultMap對映
<resultMap id="userMap" type="com.aust.model.User" autoMapping="true">
<id column="id" property="id"/>
//這裡可以看到多了兩個屬性select表示要呼叫的那個statement的id
//column表示要傳入的引數
<collection property="adresses" ofType="com.aust.model.Adress" autoMapping="true" select="findAddress" column="id">
</collection>
</resultMap>上面sql意思是,加入我們要取出全部使用者,使用findUserById,然後當我們呼叫使用者的user.getAdresses()取出地址的時候,mybatis就會把該使用者的id傳入findAddress作為輸入引數,然後執行查詢,也就是說假設我們沒取出地址,則不會執行這個查詢
junit測試
@Before
public void init(){
InputStream is = null;
try {
is = Resources.getResourceAsStream("SqlMapperConfig.xml");
} catch (IOException e) {
e.printStackTrace();
}
factory = new SqlSessionFactoryBuilder().build(is);
}
@Test
public void findAddressAndUserTest(){
//獲取sqlsession
SqlSession session = factory.openSession();
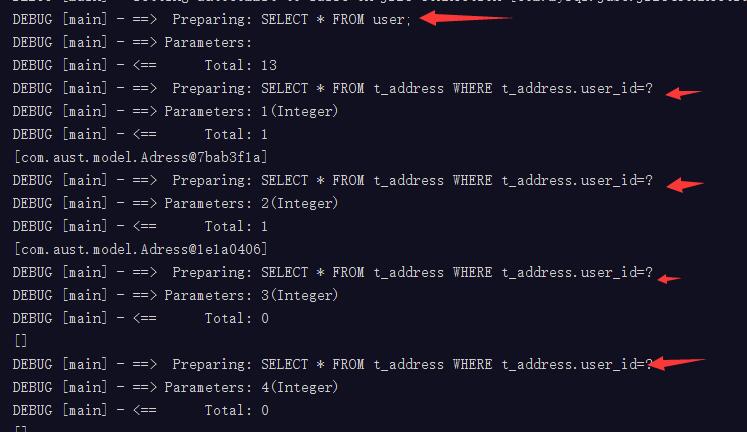
List<User> users = session.selectList("UserMapper.findUser");
//迴圈取出地址.這個時候mybatis就會自動呼叫findAddress取出地址
for (User user:users) {
System.out.println(user.getAdresses().toString());//在這裡打個斷點測試
}
session.close();
}測試如下,可以看出,取出全部使用者後如果遍歷則會一條一條的執行取出地址的sql語句.
所以這裡如果你使用延遲載入後,遍歷一個有很多記錄的表的話,反而會影響效能,因為每遍歷一次就會執行一條sql,最終得不償失.
那麼延遲載入在什麼時候用呢?我認為在很多記錄中,你已經知道了要具體取出的使用者的時候用,這個時候就只需要執行取出你指定使用者的地址,就一條sql
三.查詢快取
快取就是指把資料庫取出的結果暫時儲存起來,這個可以儲存在記憶體或者硬碟再或者就是伺服器,然後再次執行相同的sql語句的時候,就會先去快取裡面找,找到的話就避免了再次從資料庫中取出,因為從資料庫取出花費往往是巨大的.
1.一級快取
原理圖如下,一級快取是SqlSession級別的快取,也就是說,SqlSession一旦關閉則一級快取就會自動清空了.一級快取是mybatis自動啟用的,無需配置.
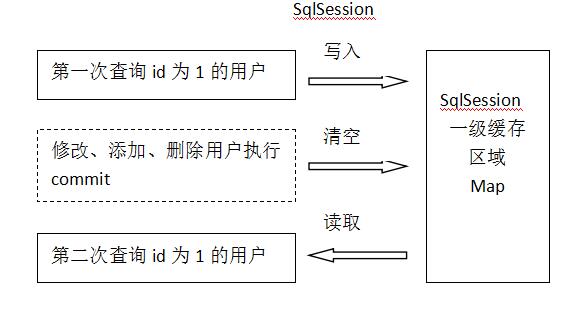
一級快取區域是根據SqlSession為單位劃分的。
每次查詢會先從快取區域找,如果找不到從資料庫查詢,查詢到資料將資料寫入快取。
Mybatis內部儲存快取使用一個HashMap,key為hashCode+sqlId+Sql語句。value為從查詢出來對映生成的java物件
sqlSession執行insert、update、delete等操作commit提交後會清空快取區域。
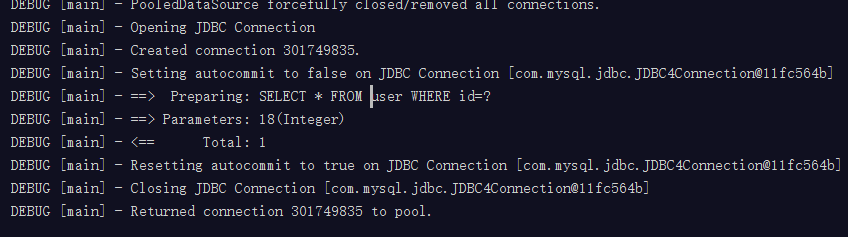
junit測試一級快取:
//前面init程式碼省略
@Test
public void findUserByIdTest(){
//獲取sqlsession
SqlSession session = factory.openSession();
//查詢18號
User user1 = session.selectOne("UserMapper.findUserById",18);
//再次查詢18號
User user2 = session.selectOne("UserMapper.findUserById",18);
session.close();
}從測試可以看出兩次查詢實際上只發出了一條sql語句.說明第二次查詢是從快取中找的,當然也可以跟蹤程式碼來看
2.二級快取
原理圖如下
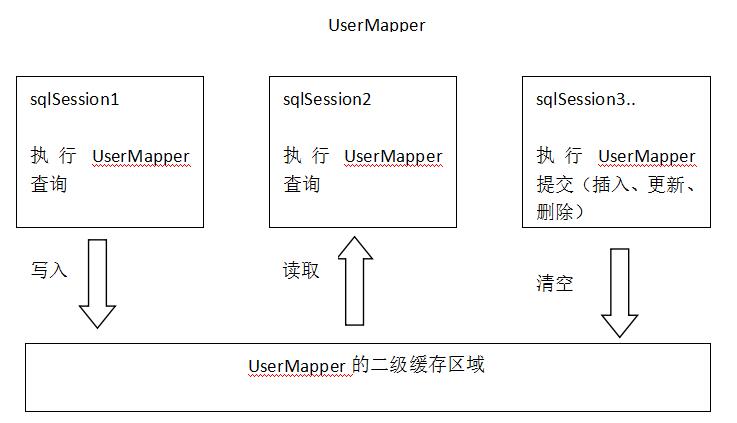
二級快取區域是根據mapper的namespace劃分的,相同namespace的mapper查詢資料放在同一個區域,如果使用mapper代理方法每個mapper的namespace都不同,此時可以理解為二級快取區域是根據mapper劃分。
每次查詢會先從快取區域找,如果找不到從資料庫查詢,查詢到資料將資料寫入快取。
Mybatis內部儲存快取使用一個HashMap,key為hashCode+sqlId+Sql語句。value為從查詢出來對映生成的java物件
sqlSession執行insert、update、delete等操作commit提交後會清空快取區域。
1.開啟二級快取
二級快取的開啟,不但要在SqlMapConfig.xml中配置,還需要在相應的Mapper.xml中配置
<!--開啟二級快取,預設也是開啟狀態的-->
<setting name="cacheEnabled" value="true"/>在Mapper.xml中配置如下:
<!--設定該mapper使用二級快取-->
<cache/>除此之外二級快取需要查詢結果對映的pojo物件實現java.io.Serializable介面實現序列化和反序列化操作,注意如果存在父類、成員pojo都需要實現序列化介面。
public class Orders implements Serializable
public class User implements Serializable
....2.二級快取測試
@Test
public void findUserByIdTest(){
//獲取sqlsession1
SqlSession session1 = factory.openSession();
//使用session1查詢
User user1 = session1.selectOne("UserMapper.findUserById",18);
session1.close();
//獲取session2
SqlSession session2 = factory.openSession();
//使用session2查詢
User user = session2.selectOne("UserMapper.findUserById",18);
session2.close();
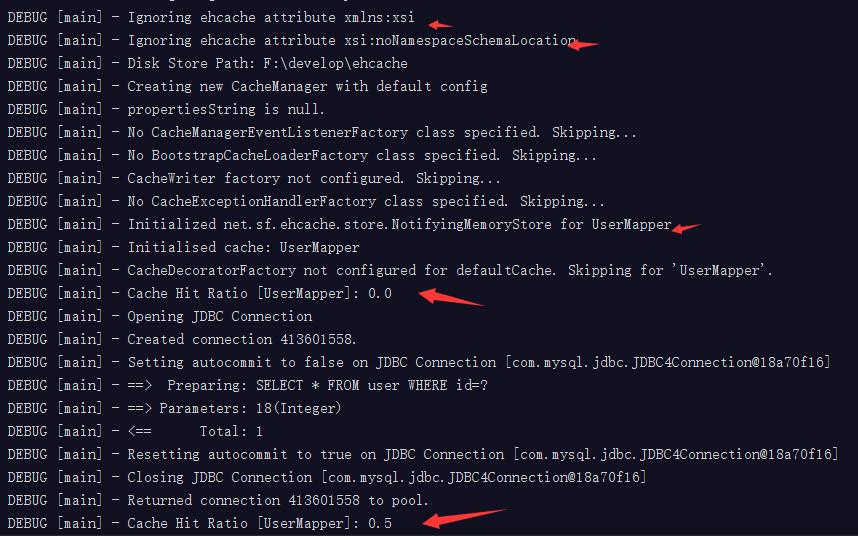
}從測試結果可以看出來,兩次查詢是不同的session,實際上只執行了一次sql語句,快取命中率,第一次為0,因為快取為空,第二次為0.5,因為在快取中找了兩次,找到了這個資料.

3.禁用二級快取
在statement中設定useCache=false可以禁用當前select語句的二級快取,即每次查詢都會發出sql去查詢,預設情況是true,即該sql使用二級快取。
<select id="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
4.重新整理快取
在mapper的同一個namespace中,如果有其它insert、update、delete操作資料後需要重新整理快取,如果不執行重新整理快取會出現髒讀。
設定statement配置中的flushCache=”true” 屬性,預設情況下為true即重新整理快取,如果改成false則不會重新整理。使用快取時如果手動修改資料庫表中的查詢資料會出現髒讀。
如下:
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User" flushCache="true">
5.mybatis二級快取引數
不過一般都是整合第三方快取框架來用
flushInterval(重新整理間隔)可以被設定為任意的正整數,而且它們代表一個合理的毫秒形式的時間段。預設情況是不設定,也就是沒有重新整理間隔,快取僅僅呼叫語句時重新整理。
size(引用數目)可以被設定為任意正整數,要記住你快取的物件數目和你執行環境的可用記憶體資源數目。預設值是1024。
readOnly(只讀)屬性可以被設定為true或false。只讀的快取會給所有呼叫者返回快取物件的相同例項。因此這些物件不能被修改。這提供了很重要的效能優勢。可讀寫的快取會返回快取物件的拷貝(通過序列化)。這會慢一些,但是安全,因此預設是false。
如下例子:
這個更高階的配置建立了一個 FIFO 快取,並每隔 60 秒重新整理,存數結果物件或列表的 512 個引用,而且返回的物件被認為是隻讀的,因此在不同執行緒中的呼叫者之間修改它們會導致衝突。可用的收回策略有, 預設的是 LRU:
1.LRU – 最近最少使用的:移除最長時間不被使用的物件。
2.FIFO – 先進先出:按物件進入快取的順序來移除它們。
3.SOFT – 軟引用:移除基於垃圾回收器狀態和軟引用規則的物件。
4.WEAK – 弱引用:更積極地移除基於垃圾收集器狀態和弱引用規則的物件。
3.整合ehcache
mybatis對於快取管理不是很好,一般都是用第三方快取代替,這裡使用ehcache,主要掌握整合快取的方法.
mybatis提供二級快取Cache介面
package org.apache.ibatis.cache;
import java.util.concurrent.locks.ReadWriteLock;
public interface Cache {
String getId();
void putObject(Object var1, Object var2);
Object getObject(Object var1);
Object removeObject(Object var1);
void clear();
int getSize();
ReadWriteLock getReadWriteLock();
}想要實現其他快取的話,需要繼承這個介面,當然第三方框架都幫我們寫好了,我們只需要拿來使用即可
首先匯入包,第一個是核心包,第二個是整合包,這裡面有實現了Cache介面的實現類,下面兩個是日誌包,ehcache依賴這個日誌包

接下來在classpath下配置ehcache.xml
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
>
<diskStore path="F:\develop\ehcache" />
<defaultCache
maxElementsInMemory="1000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
</defaultCache>
</ehcache>屬性說明:
1. diskStore:指定資料在磁碟中的儲存位置。
2. defaultCache:當藉助CacheManager.add(“demoCache”)建立Cache時,EhCache便會採用指定的的管理策略
以下屬性是必須的:
3. maxElementsInMemory - 在記憶體中快取的element的最大數目
4. maxElementsOnDisk - 在磁碟上快取的element的最大數目,若是0表示無窮大
5. eternal - 設定快取的elements是否永遠不過期。如果為true,則快取的資料始終有效,如果為false那麼還要根據timeToIdleSeconds,timeToLiveSeconds判斷
6. overflowToDisk - 設定當記憶體快取溢位的時候是否將過期的element快取到磁碟上
以下屬性是可選的:
7. timeToIdleSeconds - 當快取在EhCache中的資料前後兩次訪問的時間超過timeToIdleSeconds的屬性取值時,這些資料便會刪除,預設值是0,也就是可閒置時間無窮大
8. timeToLiveSeconds - 快取element的有效生命期,預設是0.,也就是element存活時間無窮大
diskSpoolBufferSizeMB 這個引數設定DiskStore(磁碟快取)的快取區大小.預設是30MB.每個Cache都應該有自己的一個緩衝區.
9. diskPersistent - 在VM重啟的時候是否啟用磁碟儲存EhCache中的資料,預設是false。
10. diskExpiryThreadIntervalSeconds - 磁碟快取的清理執行緒執行間隔,預設是120秒。每個120s,相應的執行緒會進行一次EhCache中資料的清理工作
11. memoryStoreEvictionPolicy - 當記憶體快取達到最大,有新的element加入的時候, 移除快取中element的策略。預設是LRU(最近最少使用),可選的有LFU(最不常使用)和FIFO(先進先出)
最後只需要在mapper.xml裡面設定快取類
<!--設定該mapper使用ehcache二級快取-->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>junit測試
@Test
public void findUserByIdTest(){
//獲取sqlsession
SqlSession session1 = factory.openSession();
User user1 = session1.selectOne("UserMapper.findUserById",18);
session1.close();
SqlSession session2 = factory.openSession();
User user = session2.selectOne("UserMapper.findUserById",18);
session2.close();
}
4.快取應用場景
對於訪問多的查詢請求且使用者對查詢結果實時性要求不高,此時可採用mybatis二級快取技術降低資料庫訪問量,提高訪問速度,業務場景比如:耗時較高的統計分析sql、電話賬單查詢sql等。
實現方法如下:通過設定重新整理間隔時間,由mybatis每隔一段時間自動清空快取,根據資料變化頻率設定快取重新整理間隔flushInterval,比如設定為30分鐘、60分鐘、24小時等,根據需求而定。
5.快取侷限性
mybatis二級快取對細粒度的資料級別的快取實現不好,比如如下需求:對商品資訊進行快取,由於商品資訊查詢訪問量大,但是要求使用者每次都能查詢最新的商品資訊,此時如果使用mybatis的二級快取就無法實現當一個商品變化時只重新整理該商品的快取資訊而不重新整理其它商品的資訊,因為mybaits的二級快取區域以mapper為單位劃分,當一個商品資訊變化會將所有商品資訊的快取資料全部清空。解決此類問題需要在業務層根據需求對資料有針對性快取。
專案示例: