CentOS6.5虛擬機器下搭建Hadoop偽分散式環境
阿新 • • 發佈:2019-01-10
一、 實驗環境
- 作業系統:CentOS6.5
- Hadoop版本:hadoop-2.7.2
- JDK版本:jdk-8u73-linux-x64
二、 搭建步驟
1.安裝作業系統:使用VitualBox安裝CentOS6.5作業系統,安裝方式選擇為預設。(硬碟大小為20G,預設使用全部空間會對其做成LVM)。
2.通過以下命令修改當前主機名稱:
vim /etc/sysconfig/network修改完成後重啟機器。
3.配置網路:
① 開機不啟動NetworkManager服務:
chkconfig NetworkManager off② 停掉NetworkManager服務:
/etc/init.d/NetworkManager stop ③ 編輯網絡卡配置檔案
vim /etc/sysconfig/network-scripts/ifcfg-eth0 內容編輯如下:
DEVICE=eth0
HWADDR=08:00:27:71:30:C0
TYPE=Ethernet
UUID=af0e8611-c438-4aa6-923c-ab55b3380478
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.0.15
NETMASK=255.255.255.04.關閉防火牆並設為開機不啟動: ① 關閉防火牆服務:
/etc/init.d/iptables stop ② 開機不啟動防火牆:
chkconfig NetworkManager off5.配置JDK環境:
① 將jdk-8u73-linux-x64.tar.gz包解壓到/opt當中:
tar -xvf jdk-8u73-linux-x64.tar.gz -C /opt/ ② 配置系統環境變數:
vim /etc/profile 在/etc/profile檔案中新增如下行:
export JAVA_HOME=/opt/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME} 儲存退出,然後使用如下命令更新當前終端的環境變數配置
source /etc/profile 完成之後,使用如下命令來確認配置是否成功
java -version 若配置成功,則如下圖所示:

6.在/下依次建立新資料夾,並將hadoop程式壓縮包解壓到該資料夾當中。
mkdir -p /hadoop/program && tar -xvf hadoop-2.7.2.tar.gz -C /hadoop/program/7.將含有hadoop常用命令的目錄新增到環境變數中
vim /etc/profile 在最後新增如下欄位:
export HADOOP_HOME=/hadoop/program/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:${PATH}儲存重啟,然後使用source命令更新當前終端配置。
8.配置hadoop:
hadoop的配置檔案都在程式目錄下中的etc/hadoop資料夾當中,對應我當前機器的絕對路徑為/hadoop/program/hadoop-2.7.2/etc/hadoop資料夾。搭建hadoop偽分散式環境需要修改5個配置問價,如下:
① core-site.xml
*該配置檔案指定**NameNode地址**以及hadoop執行時產生檔案的的存放地址*。 修改configuration標籤:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
</configuration>
② hadoop-env.sh
該配置檔案主要指定hadoop執行時的環境變數,在該檔案中,修改預設的JAVA_HOME對應值:
export JAVA_HOME=/opt/jdk1.8.0_73 ③ hdfs-site.xml
通過該配置檔案指定檔案存放副本的數量,修改configuration標籤對應值(儲存1份副本):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> ④ mapred-site.xml
指定mapreduce的執行方法(YARN),修改configuration標籤如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>⑤ yarn-site.xml
通過該配置檔案指定NodeManager獲取資料的方式使shuffle,和指定YARN ResourceManager的地址,修改configuration標籤如下。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
</configuration>
三、 啟動Hadoop
1.初始化HDFS檔案系統:
hdfs namenode -format2.啟動HDFS和MapReduce,相應的啟動指令碼在hadoop程式目錄中的sbin資料夾中,分別執行start-hdfs.sh和start-yarn.sh指令碼。
四、 測試Hadoop
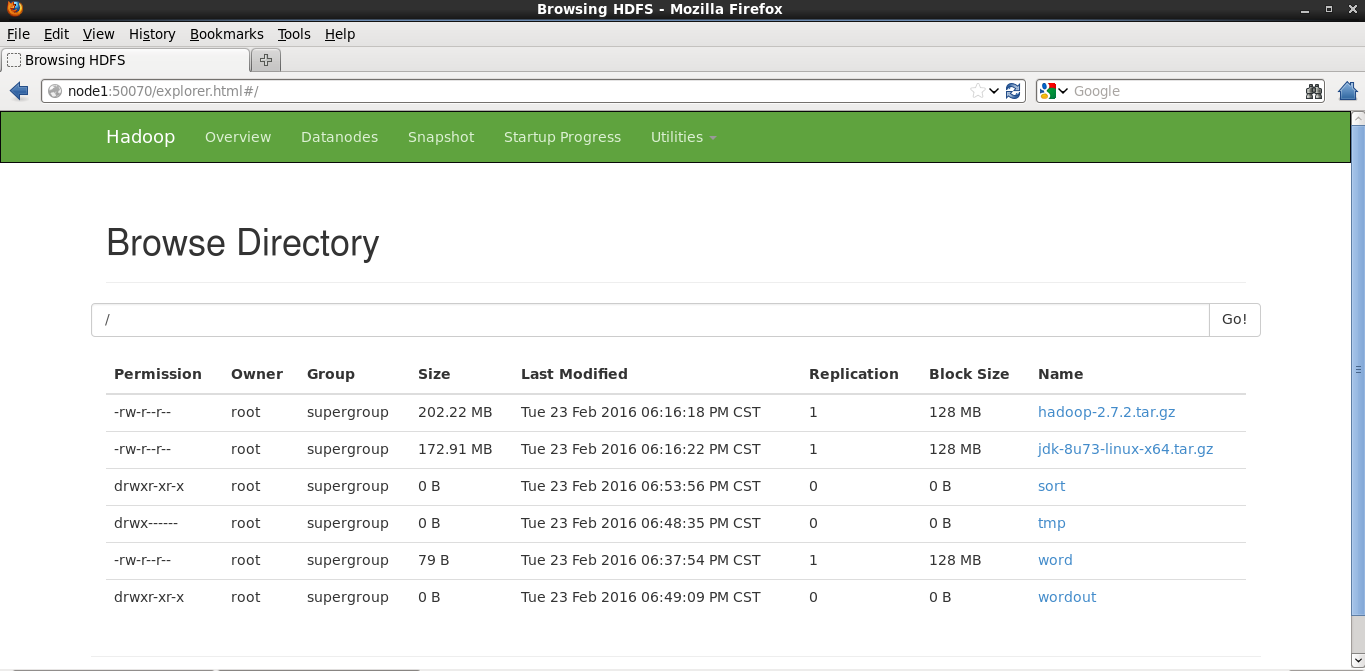
1.通過瀏覽器方式對HDFS和MapReduce進行訪問,HDFS預設的瀏覽器訪問埠為為50070,MapReduce預設的訪問埠為8088。訪問成功如圖所示:
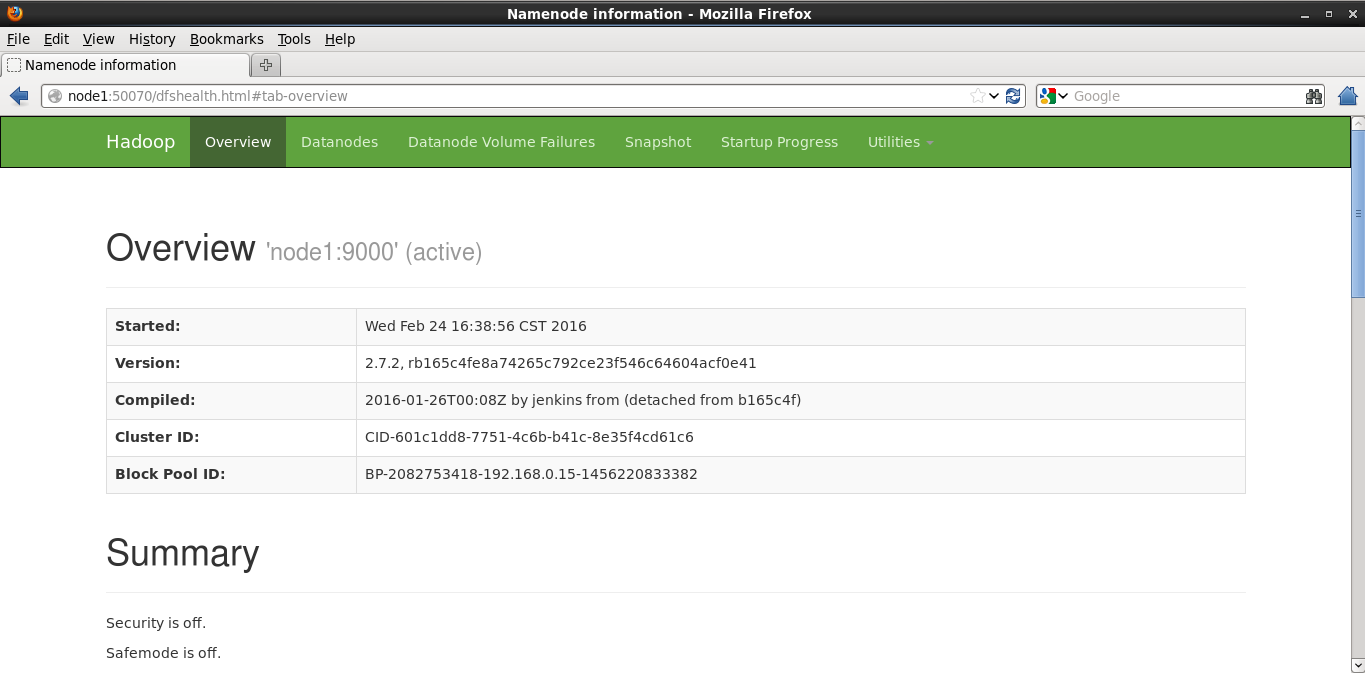
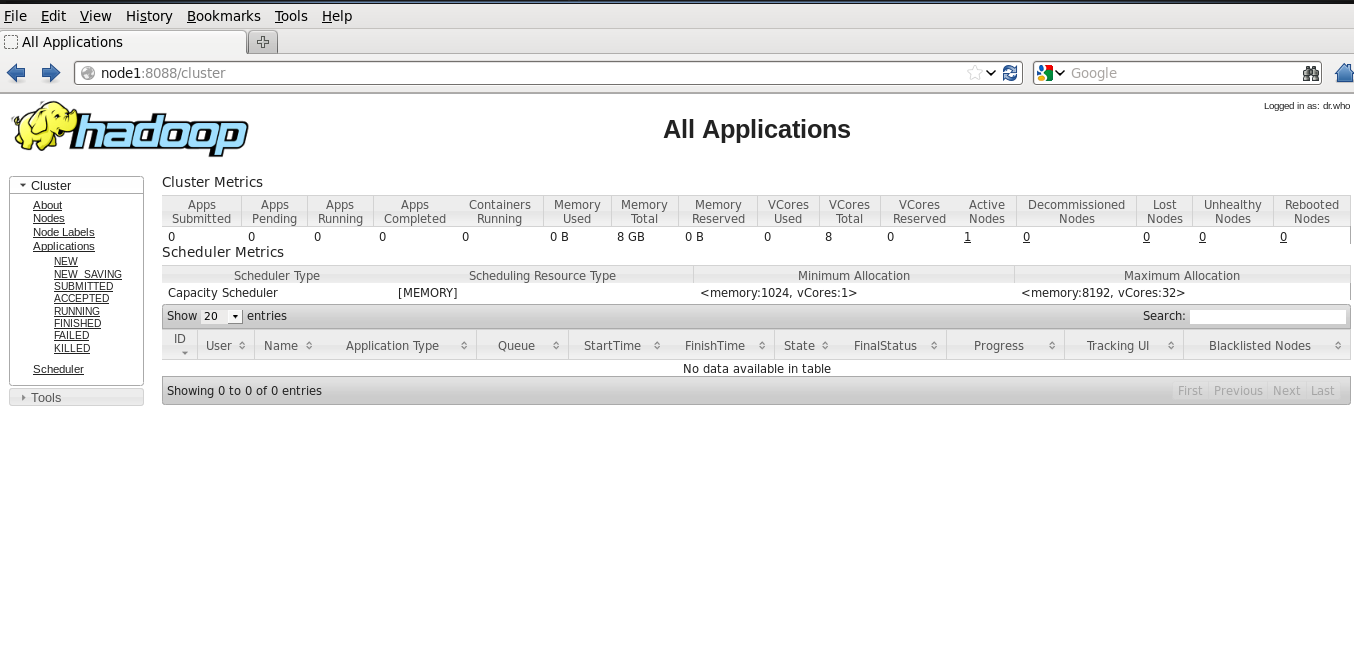
2.將檔案上傳到HDFS當中,使用命令:
hadoop fs -put 檔名稱 hdfs://node1:9000/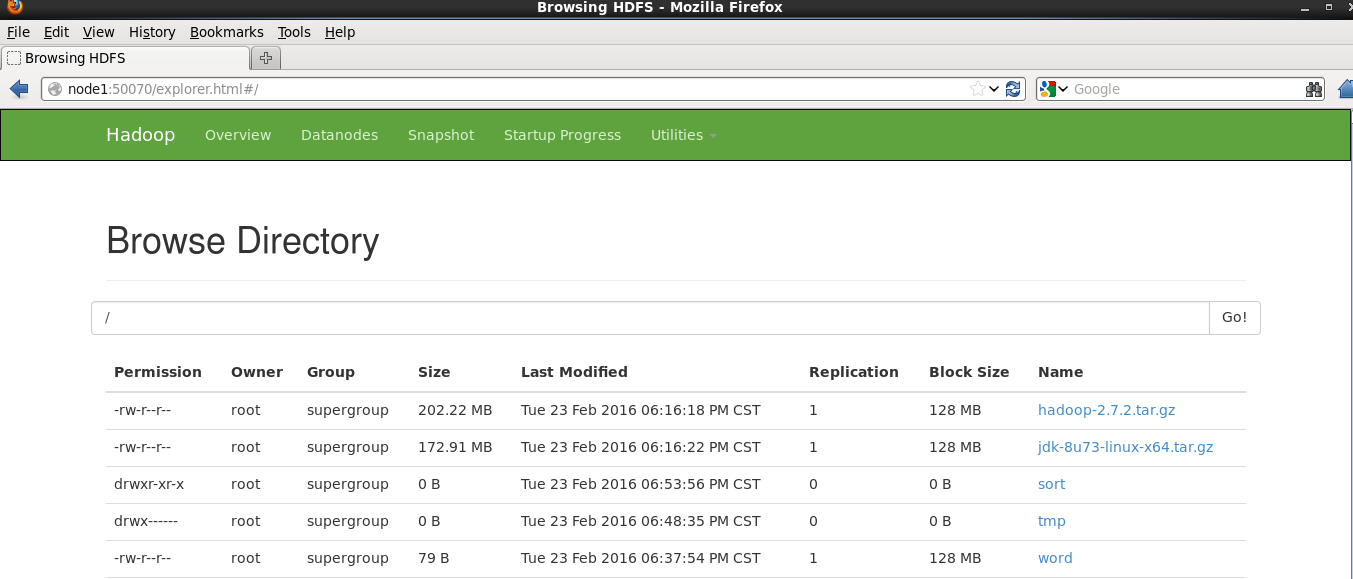
在Utilities標籤頁下可以看到上傳的檔案的資訊。
3.使用MapReduce進行簡單的資料分析,使用Hadoop程式目錄下的share/hadoop/mapreduce/中的測試jar檔案hadoop-mapreduce-examples進行測試:
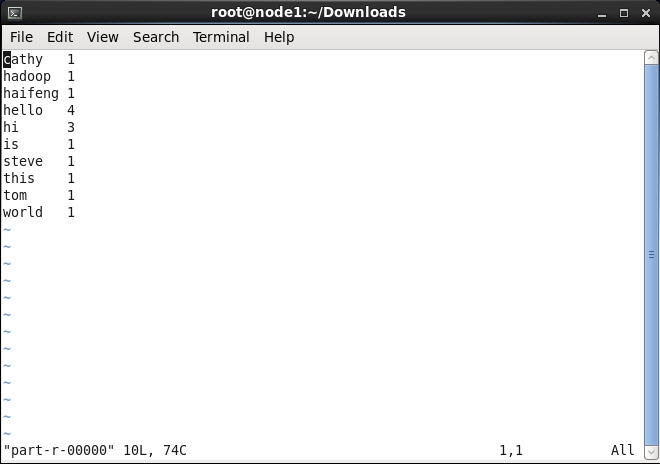
hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount hdfs://node1:word hdfs://node1:wordout執行成功後,可以看到在HDFS下有的wokdout檔案:
下載下來進行檢視,可以看到: