
Scrapy入門教程之詳細介紹和一個很好的例子
Scrapy入門教程之詳細介紹和一個很好的例子
Scrapy,Python開發的一個快速、高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。
Scrapy吸引人的地方在於它是一個框架,任何人都可以根據需求方便的修改。它也提供了多種型別爬蟲的基類,如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支援。
Scrap,是碎片的意思,這個Python的爬蟲框架叫Scrapy。
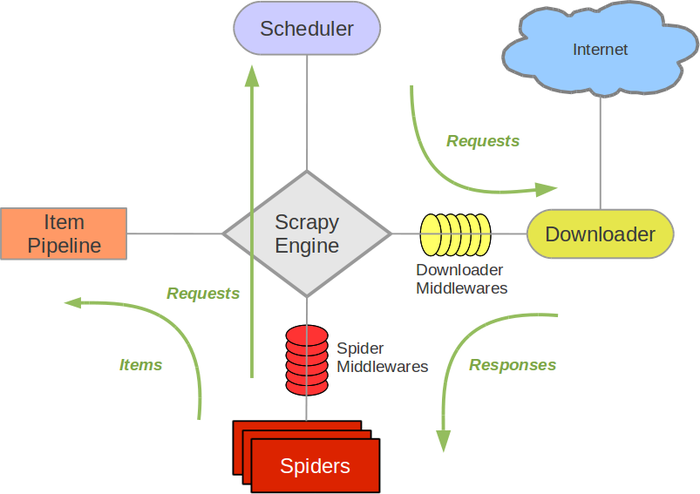
Scrapy架構圖(綠線是資料流向)
-
Scrapy Engine(引擎)
: 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等。 -
Scheduler(排程器): 它負責接受引擎傳送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。
-
Downloader(下載器):負責下載Scrapy Engine(引擎)傳送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
-
Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器).
-
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、儲存等)的地方。
-
Downloader Middlewares(下載中介軟體):你可以當作是一個可以自定義擴充套件下載功能的元件。
-
Spider Middlewares(Spider中介軟體):你可以理解為是一個可以自定擴充套件和操作引擎和Spider中間通訊的功能元件(比如進入Spider的Responses;和從Spider出去的Requests)
Scrapy的運作流程
程式碼寫好,程式開始執行...
- 1 引擎:Hi!Spider, 你要處理哪一個網站?
- 2 Spider:老大要我處理xxxx.com。
- 3 引擎:你把第一個需要處理的URL給我吧。
- 4 Spider:給你,第一個URL是xxxxxxx.com。
- 5 引擎:Hi!排程器,我這有request請求你幫我排序入隊一下。
- 6 排程器:好的,正在處理你等一下。
- 7 引擎:Hi!排程器,把你處理好的request請求給我。
- 8 排程器:給你,這是我處理好的request
- 9 引擎:Hi!下載器,你按照老大的下載中介軟體的設定幫我下載一下這個request請求
- 10 下載器:好的!給你,這是下載好的東西。(如果失敗:sorry,這個request下載失敗了。然後引擎告訴排程器,這個request下載失敗了,你記錄一下,我們待會兒再下載)
- 11 引擎:Hi!Spider,這是下載好的東西,並且已經按照老大的下載中介軟體處理過了,你自己處理一下(注意!這兒responses預設是交給def parse()這個函式處理的)
- 12 Spider:(處理完畢資料之後對於需要跟進的URL),Hi!引擎,我這裡有兩個結果,這個是我需要跟進的URL,還有這個是我獲取到的Item資料。
- 13 引擎:Hi !管道 我這兒有個item你幫我處理一下!排程器!這是需要跟進URL你幫我處理下。然後從第四步開始迴圈,直到獲取完老大需要全部資訊。
- 14 管道排程器:好的,現在就做!
注意!只有當排程器中不存在任何request了,整個程式才會停止,(也就是說,對於下載失敗的URL,Scrapy也會重新下載。)
製作 Scrapy 爬蟲 一共需要4步:
- 新建專案 (scrapy startproject xxx):新建一個新的爬蟲專案
- 明確目標 (編寫items.py):明確你想要抓取的目標
- 製作爬蟲 (spiders/xxspider.py):製作爬蟲開始爬取網頁
- 儲存內容 (pipelines.py):設計管道儲存爬取內容
安裝
Windows 安裝方式
升級 pip 版本:
pip install --upgrade pip通過 pip 安裝 Scrapy 框架:
pip install ScrapyUbuntu 安裝方式
安裝非 Python 的依賴:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev通過 pip 安裝 Scrapy 框架:
sudo pip install scrapyMac OS 安裝方式
對於Mac OS系統來說,由於系統本身會引用自帶的python2.x的庫,因此預設安裝的包是不能被刪除的,但是你用python2.x來安裝Scrapy會報錯,用python3.x來安裝也是報錯,我最終沒有找到直接安裝Scrapy的方法,所以我用另一種安裝方式來說一下安裝步驟,解決的方式是就是使用virtualenv來安裝。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy- 前提條件:你需要有 pip python管理器
- pip 是一個現代的,通用的 Python 包管理工具。提供了對 Python 包的查詢、下載、安裝、解除安裝的功能。
- 你可以使用 Mac brew 安裝 python 3 - 命令 'brew install python'。因為Mac預設安裝2.7版本,系統會自動生成python3的命令字首,python3自帶pip模組,命令字首是pip3
- Mac python3 安裝 scrapy的命令是
pip3 install scrapy
- 如果執行'brew install python'失敗,並且是由於github防火牆的問題,可以使用以下方法更改Homebrew的清華國內映象
cd "$(brew --repo)" git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core" git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git brew update
或者按照下列步驟進行本地安裝
###########安裝步驟#############
###刪除已經存在的Homebrew資料夾
sudo rm -rf /usr/local/Homebrew
sudo rm -rf /Library/Caches/Homebrew###獲取install檔案並編輯
curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install >> brew_install###編輯brew_install檔案
#BREW_REPO = "https://github.com/Homebrew/brew".freeze
BREW_REPO = "https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew".freeze
#CORE_TAP_REPO = "https://github.com/Homebrew/homebrew-core".freeze
CORE_TAP_REPO = "https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core".freeze###執行brew_install進行安裝
/usr/bin/ruby ./brew_install
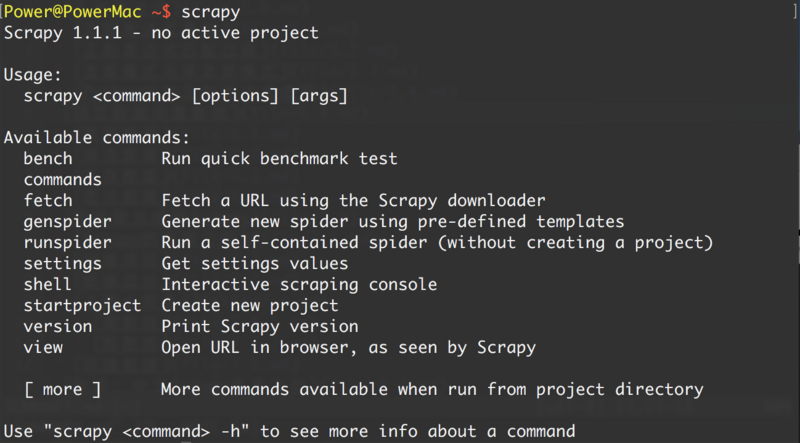
安裝後,只要在命令終端輸入 scrapy,提示類似以下結果,代表已經安裝成功。
入門案例
學習目標
- 建立一個Scrapy專案
- 定義提取的結構化資料(Item)
- 編寫爬取網站的 Spider 並提取出結構化資料(Item)
- 編寫 Item Pipelines 來儲存提取到的Item(即結構化資料)
一. 新建專案(scrapy startproject)
在開始爬取之前,必須建立一個新的Scrapy專案。進入自定義的專案目錄中,執行下列命令:
scrapy startproject itcastSpider其中, itcastSpider 為專案名稱,可以看到將會建立一個 itcastSpider 資料夾,目錄結構大致如下:
下面來簡單介紹一下各個主要檔案的作用:
itcastSpider/
scrapy.cfg
itcastSpider/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
__init__.py
...這些檔案分別是:
- scrapy.cfg: 專案的配置檔案。
- itcastSpider/: 專案的Python模組,將會從這裡引用程式碼。
- itcastSpider/items.py: 專案的目標檔案。
- itcastSpider/pipelines.py: 專案的管道檔案。
- itcastSpider/settings.py: 專案的設定檔案。
- itcastSpider/middlewares.py: 專案的中介軟體檔案。
- itcastSpider/spiders/: 儲存爬蟲程式碼目錄。
二、明確目標(mySpider/items.py)
我們打算抓取 http://www.itcast.cn/channel/teacher.shtml 網站裡的所有講師的姓名、職稱和個人資訊。
接下來,建立一個 ItcastItem 類,和構建 item 模型(model)。
import scrapy
class ItcastspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
pass
-
開啟 itcastSpider 目錄下的 items.py。
-
Item 定義結構化資料欄位,用來儲存爬取到的資料,有點像 Python 中的 dict,但是提供了一些額外的保護減少錯誤。
-
可以通過建立一個 scrapy.Item 類, 並且定義型別為 scrapy.Field 的類屬性來定義一個 Item(可以理解成類似於 ORM 的對映關係)。
三、製作爬蟲 (spiders/itcast.py)
爬蟲功能要分兩步:
1. 爬資料
在當前目錄下輸入命令,將在itcastSpider/spider目錄下建立一個名為itcast的爬蟲,並指定爬取域的範圍:
scrapy genspider itcast "itcast.cn"開啟 itcastSpider/spider目錄裡的 itcast.py,預設增加了下列程式碼:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass其實也可以由我們自行建立itcast.py並編寫上面的程式碼,只不過使用命令可以免去編寫固定程式碼的麻煩
要建立一個Spider, 你必須用scrapy.Spider類建立一個子類,並確定了三個強制的屬性 和 一個方法。
name = "" :這個爬蟲的識別名稱,必須是唯一的,在不同的爬蟲必須定義不同的名字。
allow_domains = [] 是搜尋的域名範圍,也就是爬蟲的約束區域,規定爬蟲只爬取這個域名下的網頁,不存在的URL會被忽略。
start_urls = [] :爬取的URL元祖/列表。爬蟲從這裡開始抓取資料,所以,第一次下載的資料將會從這些urls開始。其他子URL將會從這些起始URL中繼承性生成。
parse(self, response) :解析的方法,每個初始URL完成下載後將被呼叫,呼叫的時候傳入從每一個URL傳回的Response物件來作為唯一引數,主要作用如下:
負責解析返回的網頁資料(response.body),提取結構化資料(生成item)
生成需要下一頁的URL請求。
將start_urls的值修改為需要爬取的第一個url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']修改parse()方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'wb+').write(response.body)然後執行一下看看,在itcastSpider目錄下執行:
scrapy crawl itcast是的,就是 itcast,看上面程式碼,它是 ItcastSpider 類的 name 屬性,也就是使用 scrapy genspider命令的唯一爬蟲名。
執行之後,如果列印的日誌出現 [scrapy.core.engine] INFO: Spider closed (finished),代表執行完成。 之後當前資料夾中就出現了一個 teacher.html 檔案,裡面就是我們剛剛要爬取的網頁的全部原始碼資訊。
注意: Python2.x預設編碼環境是ASCII,當和取回的資料編碼格式不一致時,可能會造成亂碼;我們可以指定儲存內容的編碼格式,一般情況下,我們可以在程式碼最上方新增
import sys
reload(sys)
sys.setdefaultencoding("utf-8")這三行程式碼是 Python2.x 裡解決中文編碼的萬能鑰匙,經過這麼多年的吐槽後 Python3 學乖了,預設編碼是Unicode了...(祝大家早日擁抱Python3)
2. 取資料
爬取整個網頁完畢,接下來的就是的取過程了,首先觀察頁面原始碼:
<div class="li_txt">
<h3> xxx </h3>
<h4> xxxxx </h4>
<p> xxxxxxxx </p>是不是一目瞭然?直接上 XPath 開始提取資料吧。
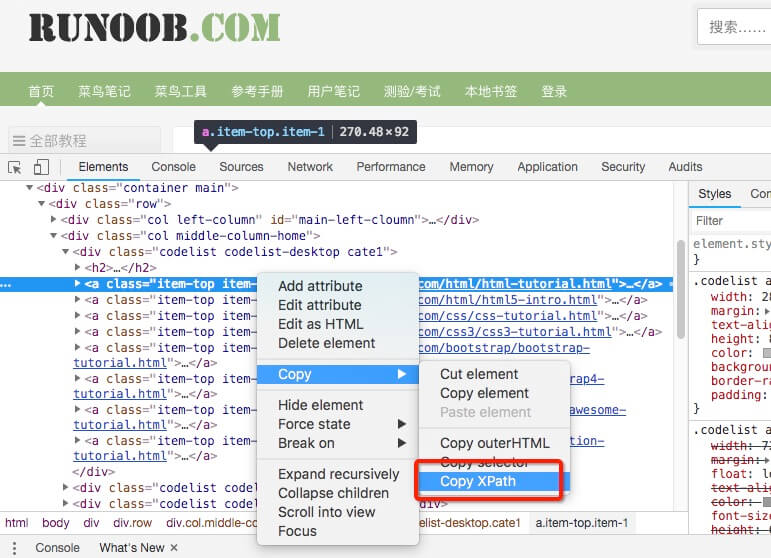
xpath 方法,我們只需要輸入的 xpath 規則就可以定位到相應 html 標籤節點,詳細內容可以檢視 xpath 教程。
不會 xpath 語法沒關係,Chrome 給我們提供了一鍵獲取 xpath 地址的方法(右鍵->檢查->copy->copy xpath),如下圖:
這裡給出一些 XPath 表示式的例子及對應的含義:
/html/head/title: 選擇HTML文件中<head>標籤內的<title>元素/html/head/title/text(): 選擇上面提到的<title>元素的文字//td: 選擇所有的<td>元素//div[@class="mine"]: 選擇所有具有class="mine"屬性的div元素
舉例我們讀取網站 http://www.itcast.cn/ 的網站標題,修改 itcast.py 檔案程式碼如下::
# -*- coding: utf-8 -*-
import scrapy
# 以下三行是在 Python2.x版本中解決亂碼問題,Python3.x 版本的可以去掉
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class itcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.com']
start_urls = ['http://www.itcast.cn/']
def parse(self, response):
# 獲取網站標題
context = response.xpath('/html/head/title/text()')
# 提取網站標題
title = context.extract_first()
print(title)
pass執行以下命令:
$ scrapy crawl itcast
...
...
傳智播客官網-好口碑IT培訓機構,一樣的教育,不一樣的品質
...
...我們之前在 itcastSpider/items.py 裡定義了一個 ItcastspiderItem 類。 這裡引入進來:
from itcastSpider.items import ItcastspiderItem然後將我們得到的資料封裝到一個 ItcastspiderItem 物件中,可以儲存每個老師的屬性:
# -*- coding: utf-8 -*-
import scrapy
from itcastSpider.items import ItcastspiderItem
# 以下三行是在 Python2.x版本中解決亂碼問題,Python3.x 版本的可以去掉
#import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
class itcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ["http://www.itcast.cn/channel/teacher.shtml"]
def parse(self, response):
#open("teacher.html","wb+").write(response.body).close()
# 存放老師資訊的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 將我們得到的資料封裝到一個 `ItcastItem` 物件
item = ItcastspiderItem()
#extract()方法返回的都是unicode字串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一個元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最後資料
return items我們暫時先不處理管道,後面會詳細介紹。
儲存資料
scrapy儲存資訊的最簡單的方法主要有四種,-o 輸出指定格式的檔案,命令如下:
scrapy crawl itcast -o teachers.jsonjson lines格式,預設為Unicode編碼
scrapy crawl itcast -o teachers.jsonlines注意:對於python3, xpath().extract()函式返回的是unicode字串,你需要在settings.py檔案中加入以下的一行設定就可以正確顯示中文
FEED_EXPORT_ENCODING = 'utf-8'
csv 逗號表示式,可用Excel開啟
scrapy crawl itcast -o teachers.csvxml格式
scrapy crawl itcast -o teachers.xml思考
如果將程式碼改成下面形式,結果完全一樣。
請思考 yield 在這裡的作用(Python yield 使用淺析):
# -*- coding: utf-8 -*-
import scrapy
from itcastSpider.items import ItcastspiderItem
# 以下三行是在 Python2.x版本中解決亂碼問題,Python3.x 版本的可以去掉
#import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
class itcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ["http://www.itcast.cn/channel/teacher.shtml"]
def parse(self, response):
#open("teacher.html","wb+").write(response.body).close()
# 存放老師資訊的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 將我們得到的資料封裝到一個 `ItcastItem` 物件
item = ItcastspiderItem()
#extract()方法返回的都是unicode字串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一個元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最後資料
return items