
python爬蟲——爬取汽車之家新聞
阿新 • • 發佈:2019-01-10
按F12審查一下元素:找到了對應的資訊。而且發現要爬取的圖片都在id=auto-channel-lazyload-article的div標籤下的li標籤裡。
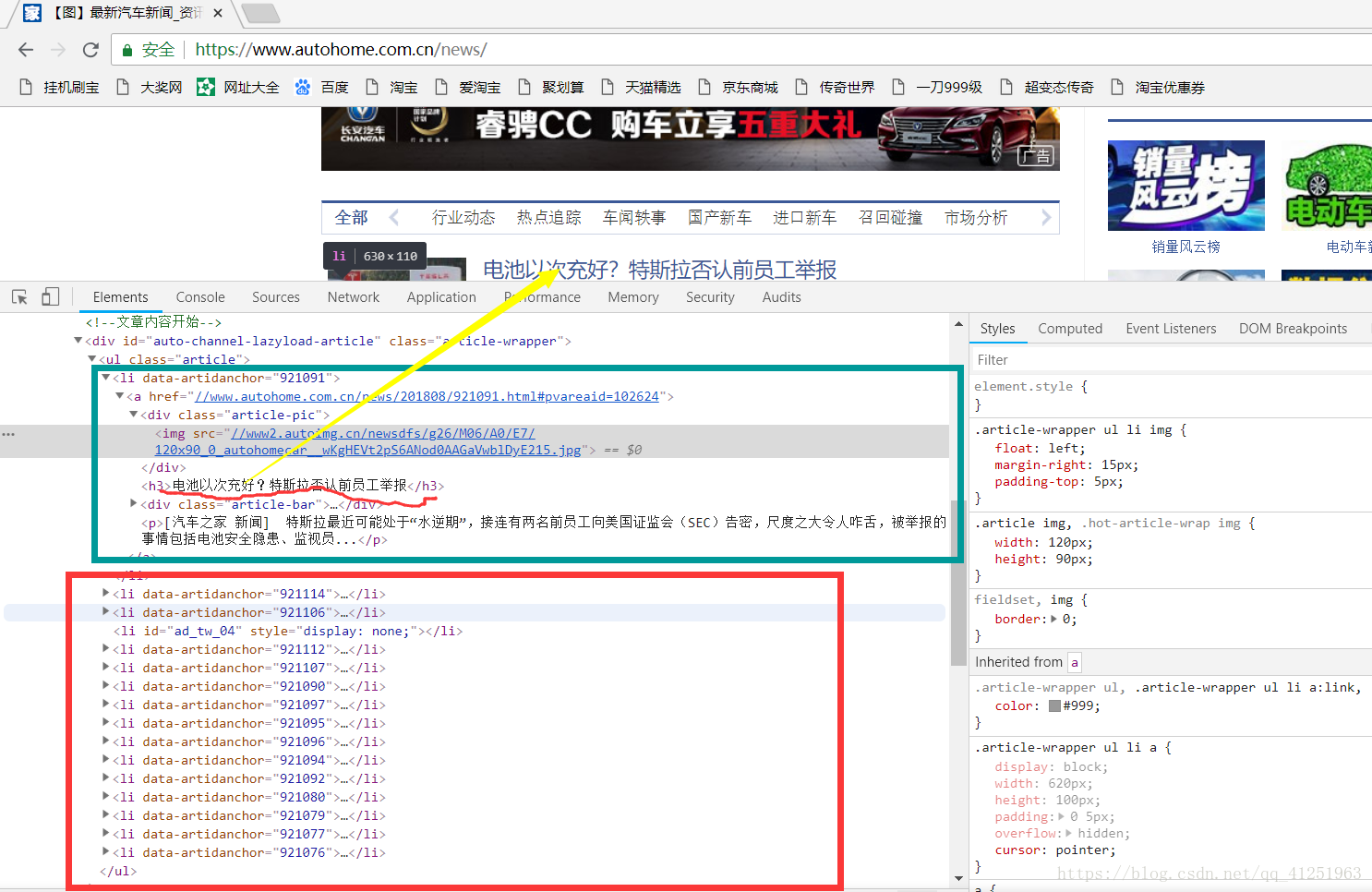
li標籤下的a標籤就是新聞的url;image標籤,src就是獲取圖片的url;
請求圖片地址,將獲取到的內容寫成二進位制檔案,儲存下來。
這就是完整的思路,接下來看一下程式碼:
完整程式碼:
import requests
from bs4 import BeautifulSoup
url='https://www.autohome.com.cn/news/'
response=requests.get(url)
response.encoding=response.apparent_encoding
soup=BeautifulSoup(response.text 這裡用到了uuid模組,是用來生成唯一識別碼的。具有多種演算法。
UUID 是 通用唯一識別碼(Universally Unique Identifier)的縮寫,是一種軟體建構的標準,亦為開放軟體基金會組織在分散式計算環境領域的一部分。其目的,是讓分散式系統中的所有元素,都能有唯一的辨識資訊,而不需要通過中央控制端來做辨識資訊的指定。如此一來,每個人都可以建立不與其它人衝突的UUID。在這樣的情況下,就不需考慮資料庫建立時的名稱重複問題。目前最廣泛應用的UUID,是微軟公司的全域性唯一識別符號(GUID),而其他重要的應用,則有Linux ext2/ext3檔案系統、LUKS加密分割槽、GNOME、KDE、Mac OS X等等。另外我們也可以在e2fsprogs包中的UUID庫找到實現。
python中的uuid模組
uuid模組在Python 2.5以後引入,介面包括:不可變物件UUID(UUID類)和函式uuid1()、uuid3()、uuid4()和uuid5(),後面的四個函式用於生成 RFC 4122 規範中指定的第1、3、4、5版UUID。使用uuid1()或uuid4()可以獲得一個唯一的ID,uuid1()包含了主機的網路名稱,uuid4()不涉及網路主機名,僅生成一個隨機UUID,因此從隱私保護角度uuid4()更加安全。
此文程式碼中使用的就是uuid4()。