
阿里輿情︱輿情熱詞分析架構簡述(Demo學習)
本節來源於阿里雲棲社群,同時正在開發一個輿情平臺,其中他們釋出了一篇他們所做的分析流程,感覺可以作為案例來學習。文章來源:覺民cloud/雲棲社群
一般熱詞分析歷經:分詞、關鍵詞提取、詞關聯計算、熱度計算
一、分詞
主要是詞包大法,你懂得,阿里詞包都不用自己寫,本身一大堆啊!!!厲害了word哥:公眾趨勢分析背後有百萬級的人名、品牌、地址、組織機構名、商品、品牌詞庫等做支撐。
萬能詞包啊!!!
.
.
二、關鍵詞提取
如何在一篇長文字中挑出關鍵詞呢? 在一定程度也就是等於找詞權重,一種衡量一個句子裡面詞語重要性指標,其他方法可見部落格:
NLP︱句子級、詞語級以及句子-詞語之間相似性(相關名稱:文件特徵、詞特徵、詞權重)
那麼,該輿情平臺使用的是:TextRank演算法為文字生成關鍵詞。
TextRank的演算法思想來源於PageRank,旨在通過文字中句子、詞之間的相互投票,為句子、詞進行權重的排序。PageRank假設一個網頁的入鏈越多,則其權重越高。隨機地為每個網頁分配一個初始權重,在每一輪投票中,每個網頁將其權重均勻地分配給其出鏈,收斂後(平穩馬爾科夫過程)每個網頁得到的權重值反映了其重要性,每輪投票的數學表述為:
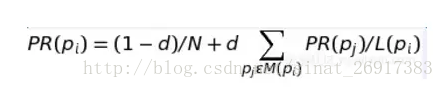
其中d為阻尼係數,(1-d)/N表示每次頁面轉移時有一定的概率會從全網隨機選擇url,這樣可以避免沒有外鏈的懸掛網頁讓所有權重收斂到0。
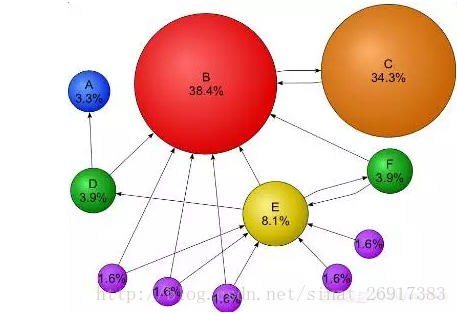
PageRank通過頁面之間的連結關係建立投票機制,TextRank以此為啟發,通過詞之間的鄰近關係建立詞權重投票機制,即假如兩個詞出現在同一個視窗中,則它們之間產生一次權重投票,這樣可以通過PageRank的求解方法,計算每個詞在文字中的權重。得到權重的排序之後,就可以挑選topN詞作為關鍵詞了。
.
.
三、詞關聯計算
該平臺使用的是互資訊.
詞關聯使用點互資訊PMI(pointwise mutual information)來表示,用資訊理論的語言來表述,點互資訊衡量的是“給定一個隨機變數後,另一個隨機變數不確定性的減少程度”。假設有兩個詞x和y,則x和y之間的點互資訊由下述公式表示:
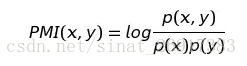
其中p(x,y)表示x和y同時出現的概率,p(x)和p(y)分別表示x和y單獨出現的概率。簡單粗暴地理解,就是說相對於單獨出現,某兩個詞更喜歡一起出現,則它們之間的關聯程度越高。
.
.