
Storm學習筆記(6)- Stream Grouping概述
阿新 • • 發佈:2019-01-10
文章目錄
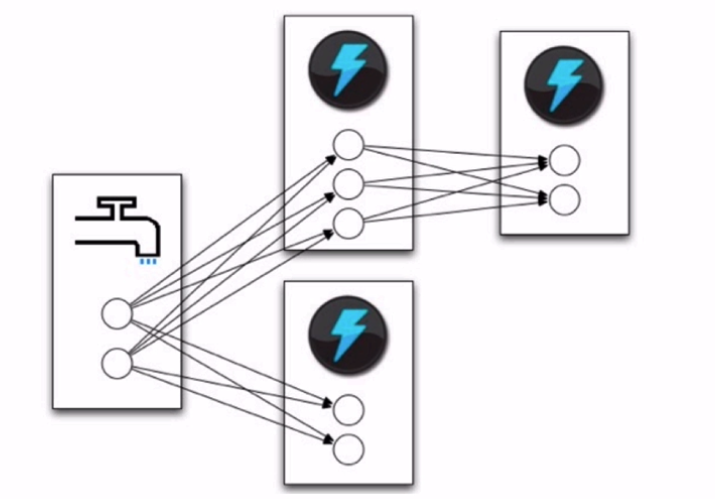
定義topology 的一部分是為每個bolt 指定它應該接收哪些Stream作為輸入。Stream Grouping定義瞭如何在bolt的任務之間劃分該Stream。
Storm中有8個內建的流分組,您可以通過實現 CustomStreamGrouping來實現自定義流分組:
- Shuffle grouping:元組(Tuples )在bolt的任務中是隨機分佈的,這樣每個bolt都可以保證得到相等數量的元組。
- Fields grouping:根據分組中指定的欄位對流進行分割槽。例如,如果流按“user-id”欄位分組,那麼具有相同“user-id”的元組將始終指向相同的任務,但是具有不同“user-id”的元組可能指向不同的任務。
- Partial Key grouping:流按照分組中指定的欄位進行分割槽,就像欄位分組一樣,但是在兩個下游bolt之間進行負載平衡,當傳入資料傾斜時,可以更好地利用資源。本文很好地解釋了它的工作原理及其優點。
- All grouping: 跨所有bolt任務複製流。小心使用這個分組。
- Global grouping: 整個流只用於bolt的一個任務。具體來說,它使用id最低的任務。
- None grouping:此分組指定您不關心流如何分組。目前,沒有分組等同於洗牌分組。最終,Storm將按下沒有分組的bolt,以便在與bolt相同的執行緒中執行,或者在可能的情況下,按下它們訂閱的bolt。
- Direct grouping: 這是一種特殊的分組。以這種方式分組的流意味著元組的生產者將決定使用者的哪個任務將接收這個元組。直接分組只能在已宣告為直接流的流上宣告。向直接流發出的元組必須使用[emitDirect](javadocs/org/apache/storm/task/OutputCollector)之一發出。方法。bolt可以通過使用提供的TopologyContext或跟蹤OutputCollector中emit方法的輸出(該方法返回元組傳送給它的任務id)來獲得其使用者的任務id。
- Local or shuffle grouping:如果目標bolt在同一工作程序中有一個或多個任務,元組將被洗牌到那些程序內任務。否則,這就像一個普通的洗牌分組。
Shuffle grouping
元組(Tuples )在bolt的任務中是隨機分佈的,這樣每個bolt都可以保證得到相等數量的元組。
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm實現積累求和的操作
*/
public class ClusterSumShuffleGroupingStormTopology {
/**
* Spout需要繼承BaseRichSpout
* 資料來源需要產生資料併發射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只會被呼叫一次
* @param conf 配置引數
* @param context 上下文
* @param collector 資料發射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 會產生資料,在生產上肯定是從訊息佇列中獲取資料
*
* 這個方法是一個死迴圈,會一直不停的執行
*/
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("Spout: " + number);
// 防止資料產生太快
Utils.sleep(1000);
}
/**
* 宣告輸出欄位
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
/**
* 資料的累積求和Bolt:接收資料並處理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,會被執行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其實也是一個死迴圈,職責:獲取Spout傳送過來的資料
* @param input
*/
public void execute(Tuple input) {
// Bolt中獲取值可以根據index獲取,也可以根據上一個環節中定義的field的名稱獲取(建議使用該方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
System.out.println("Thread id: " + Thread.currentThread().getId() + " , rece data is : " + value);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根據Spout和Bolt來構建出Topology
// Storm中任何一個作業都是通過Topology的方式進行提交的
// Topology中需要指定Spout和Bolt的執行順序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt(), 3).shuffleGrouping("DataSourceSpout");
// 程式碼提交到Storm叢集上執行
String topoName = ClusterSumShuffleGroupingStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包放到伺服器測試
shuffleGrouping:
builder.setBolt("CountBolt", new CountBolt(),3).shuffleGrouping("SplitBolt");
隨機分發到3個執行緒裡。
FieldGrouping
根據分組中指定的欄位對流進行分割槽。例如,如果流按“user-id”欄位分組,那麼具有相同“user-id”的元組將始終指向相同的任務,但是具有不同“user-id”的元組可能指向不同的任務。
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm實現積累求和的操作
*/
public class ClusterSumFieldGroupingStormTopology {
/**
* Spout需要繼承BaseRichSpout
* 資料來源需要產生資料併發射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只會被呼叫一次
* @param conf 配置引數
* @param context 上下文
* @param collector 資料發射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 會產生資料,在生產上肯定是從訊息佇列中獲取資料
*
* 這個方法是一個死迴圈,會一直不停的執行
*/
public void nextTuple() {
this.collector.emit(new Values(number%2, ++number));
System.out.println("Spout: " + number);
// 防止資料產生太快
Utils.sleep(1000);
}
/**
* 宣告輸出欄位
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("flag","num"));
}
}
/**
* 資料的累積求和Bolt:接收資料並處理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,會被執行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其實也是一個死迴圈,職責:獲取Spout傳送過來的資料
* @param input
*/
public void execute(Tuple input) {
// Bolt中獲取值可以根據index獲取,也可以根據上一個環節中定義的field的名稱獲取(建議使用該方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
System.out.println("Thread id: " + Thread.currentThread().getId() + " , rece data is : " + value);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根據Spout和Bolt來構建出Topology
// Storm中任何一個作業都是通過Topology的方式進行提交的
// Topology中需要指定Spout和Bolt的執行順序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt(), 3)
.fieldsGrouping("DataSourceSpout", new Fields("flag"));
// 程式碼提交到Storm叢集上執行
String topoName = ClusterSumFieldGroupingStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包伺服器測試
Fields grouping:
builder.setBolt("CountBolt", new CountBolt(),3).fieldsGrouping("SplitBolt");
只有兩個執行緒在處理;因為是按照基數和偶數來分組的。
AllGrouping
跨所有bolt任務複製流。小心使用這個分組。
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm實現積累求和的操作
*/
public class ClusterSumAllGroupingStormTopology {
/**
* Spout需要繼承BaseRichSpout
* 資料來源需要產生資料併發射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只會被呼叫一次
* @param conf 配置引數
* @param context 上下文
* @param collector 資料發射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 會產生資料,在生產上肯定是從訊息佇列中獲取資料
*
* 這個方法是一個死迴圈,會一直不停的執行
*/
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("Spout: " + number);
// 防止資料產生太快
Utils.sleep(1000);
}
/**
* 宣告輸出欄位
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
/**
* 資料的累積求和Bolt:接收資料並處理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,會被執行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其實也是一個死迴圈,職責:獲取Spout傳送過來的資料
* @param input
*/
public void execute(Tuple input) {
// Bolt中獲取值可以根據index獲取,也可以根據上一個環節中定義的field的名稱獲取(建議使用該方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
System.out.println("Thread id: " + Thread.currentThread().getId() + " , rece data is : " + value);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根據Spout和Bolt來構建出Topology
// Storm中任何一個作業都是通過Topology的方式進行提交的
// Topology中需要指定Spout和Bolt的執行順序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt(), 3)
.allGrouping("DataSourceSpout");
// 程式碼提交到Storm叢集上執行
String topoName = ClusterSumAllGroupingStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包上傳伺服器
有幾個task就會處理幾次-會以副本的形式執行;每個執行緒都會處理同一個數。
這個分組其實沒什麼意義