
python中的encode()和decode()函式
對於很多人來說,python的中字元轉碼是一件很頭疼的事情,本來期望結果輸出的是中文,結果來一段像這樣\xe4\xbd\xa0\xe5\xa5\xbd像是亂碼的字串。
由於學python沒多久,昨天使用python的時候,就遇到這種問題,現在來深入研究下與之相關的encode()和decode()函式,和如何把如亂碼般的字串轉成中文。
從英文意思上看,encode和decode分別指編碼和解碼。在python中,Unicode型別是作為編碼的基礎型別,即:
decode encode
str ---------> str(Unicode) ---------> str >>> u = '中文' # 指定字串型別物件u
>>> str1 = u.encode('gb2312') # 以gb2312編碼對u進行編碼,獲得bytes型別物件
>>> print(str1)
b'\xd6\xd0\xce\xc4'
>>> str2 = u.encode('gbk') # 以gbk編碼對u進行編碼,獲得bytes型別物件
>>> print(str2)
b'\xd6\xd0\xce\xc4'
>>> str3 = u.encode('utf-8' 簡要說下一般有哪些編碼格式。
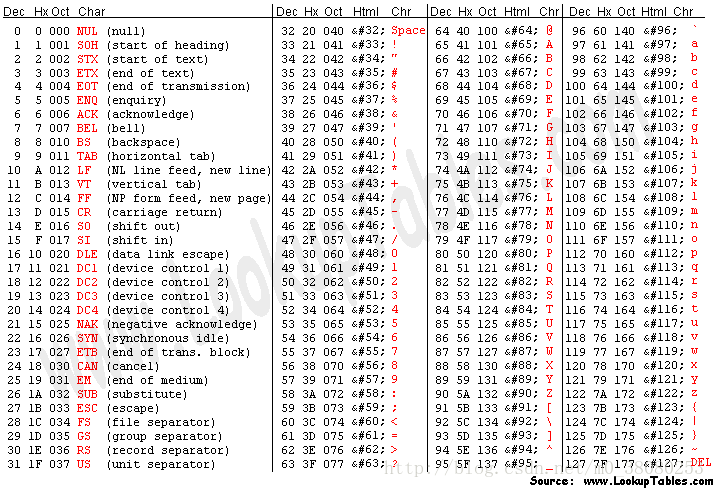
ASCII碼
ASCII碼是美國早期制定的編碼規範,只能表示128個字元,包括英文字元、阿拉伯數字、西文字元以及32個控制字元。簡單來說,就是下面這個表:
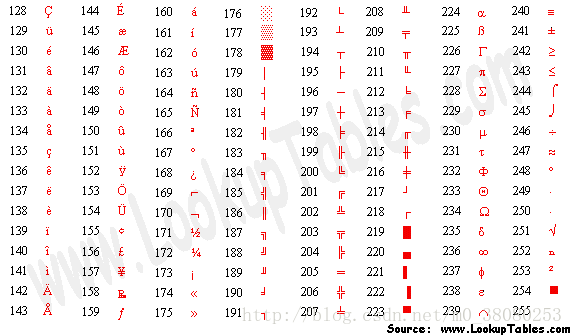
擴充套件ASCII碼(Extended ASCII)
簡單而言,擴充套件ASCII碼的出現是因為ASCII不夠用,所以向ASCII表繼續擴充到256個符號。
但是因為對於擴充套件ASCII,不同的國家有不同的標準,於是促使了Unicode編碼的誕生。
擴充套件ASCII碼錶如下:
Unicode
準確來說,Unicode不是編碼格式,而是字符集。這個字符集包含了世界上目前所有的符號。
另外,在原來有些字元可以用一個位元組即8位來表示的,在Unicode將所有字元的長度全部統一為16位,因此字元是定長的。
Unicode是長這樣的:
\u4f60\u597d\u4e2d\u56fd\uff01\u0068\u0065\u006c\u006c\u006f\uff0c\u0031\u0032\u0033上面這段Unicode的意思是“你好中國!hello,123”。
GB2312
當國人得到計算機後,那就要對漢字進行編碼。在ASCII碼錶的基礎上,小於127的字元意義與原來相同;而將兩個大於127的位元組連在一起,來表示漢字,前一個位元組從0xA1(161)到0xF7(247)共87個位元組,稱為高位元組,後一個位元組從0xA1(161)到0xFE(254)共94個位元組,稱為低位元組,兩者可組合出約8000種組合,用來表示6763個簡體漢字、數學符號、羅馬字母、日文字等。
在重新編碼的數字、標點、字母是兩位元組長的編碼,這些稱為“全形”字元;而原來在ASCII碼錶的127以下的稱為“半形”字元。
簡單而言,GB2312就是在ASCII基礎上的簡體漢字擴充套件。
GBK
簡單而言,GBK是對GB2312的進一步擴充套件(K是漢語拼音kuo zhan(擴充套件)中“擴”字的聲母),
收錄了21886個漢字和符號,完全相容GB2312。
GB18030
GB18030收錄了70244個漢字和字元,更加全面,與 GB 2312-1980 和 GBK 相容。
GB18030支援少數民族的漢字,也包含了繁體漢字和日韓漢字。
其編碼是單、雙、四位元組變長編碼的。
UTF(UCS Transfer Format)
UTF是在網際網路上使用最廣的一種Unicode的實現方式。我們最常用的是UTF-8,表示每次8個位傳輸資料,除此之外還有UTF-16。
UTF-8長這樣,“你好中國!hello,123”:
你好中国!hello,123簡單總結(來源於網路)
- 中國人民通過對 ASCII 編碼的中文擴充改造,產生了 GB2312 編碼,可以表示6000多個常用漢字。
- 漢字實在是太多了,包括繁體和各種字元,於是產生了 GBK 編碼,它包括了 GB2312 中的編碼,同時擴充了很多。
- 中國是個多民族國家,各個民族幾乎都有自己獨立的語言系統,為了表示那些字元,繼續把 GBK 編碼擴充為 GB18030 編碼。
- 每個國家都像中國一樣,把自己的語言編碼,於是出現了各種各樣的編碼,如果你不安裝相應的編碼,就無法解釋相應編碼想表達的內容。
- 終於,有個叫 ISO 的組織看不下去了。他們一起創造了一種編碼 UNICODE ,這種編碼非常大,大到可以容納世界上任何一個文字和標誌。所以只要電腦上有 UNICODE 這種編碼系統,無論是全球哪種文字,只需要儲存檔案的時候,儲存成 UNICODE 編碼就可以被其他電腦正常解釋。
- UNICODE 在網路傳輸中,出現了兩個標準 UTF-8 和 UTF-16,分別每次傳輸 8個位和 16個位。於是就會有人產生疑問,UTF-8 既然能儲存那麼多文字、符號,為什麼國內還有這麼多使用 GBK 等編碼的人?因為 UTF-8 等編碼體積比較大,佔電腦空間比較多,如果面向的使用人群絕大部分都是中國人,用 GBK 等編碼也可以。