
Python資料分析視覺化Seaborn例項講解
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
%matplotlib inlinewarnings.filterwarnings('ignore')def convert_time(s):
h,m,s=map(int,s.split(':'))
return data=pd.read_csv('marathon-data.csv',converters={'split':convert_time,'final':convert_time})
data.head()| age | gender | split | final | |
|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 |
| 1 | 32 | M | 01:06:26 | 02:09:28 |
| 2 | 31 | M | 01:06:49 | 02:10:42 |
| 3 | 38 | M | 01:06:16 | 02:13:45 |
| 4 | 31 | M | 01:06:32 | 02:13:59 |
data.dtypesage int64 gender object split timedelta64[ns] final timedelta64[ns] dtype: object
新增一列,將時間換算成秒:
data['split_sec']=data['split'].map(lambda x:x.seconds)
data['final_sec']=data['final'].map(lambda x:x.seconds)data.head()| age | gender | split | final | split_sec | final_sec | |
|---|---|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 | 3938 | 7731 |
| 1 | 32 | M | 01:06:26 | 02:09:28 | 3986 | 7768 |
| 2 | 31 | M | 01:06:49 | 02:10:42 | 4009 | 7842 |
| 3 | 38 | M | 01:06:16 | 02:13:45 | 3976 | 8025 |
| 4 | 31 | M | 01:06:32 | 02:13:59 | 3992 | 8039 |
用sns.jointplot可以同時看到兩個變數的聯合分佈與單變數的獨立分佈,這個圖形中使用白色背景。
with sns.axes_style('white'):
g=sns.jointplot('split_sec','final_sec',data,kind='kde')
g.ax_joint.plot(np.linspace(4000,16000),np.linspace(8000,32000),':k')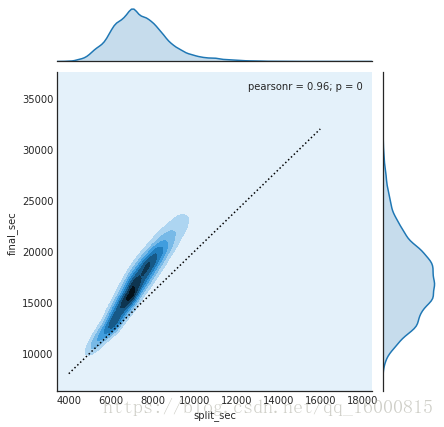
可以使用六邊形塊代替頻次直方圖
with sns.axes_style('white'):
g=sns.jointplot('split_sec','final_sec',data,kind='hex',color='r')
g.ax_joint.plot(np.linspace(4000,16000),np.linspace(8000,32000),':b')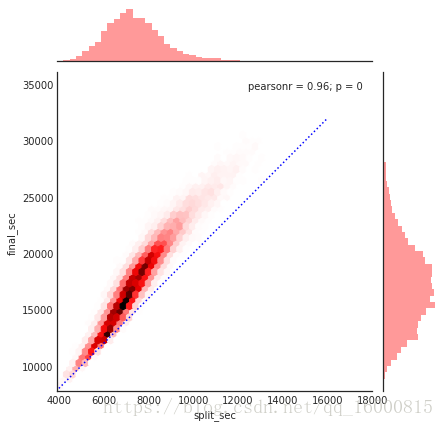
上圖表示的是馬拉松前半程成績與全程成績的對比。圖中的實點線表示一個人全程保持一個速度跑完馬拉松,即上半程與下半程耗時相同。然而實際的成績分佈表明,絕大多數人都是越往後跑得越慢(也符合常理)。如果你參加過跑步比賽,那麼就一定知道有些人在比賽的後半程速度更快—也就是在比賽中“後半程加速”。
建立一列split_frac來表示前後半程的差異,衡量比賽選手後半程加速或前半程加速的程度。
data["split_frac"]=1-2*data['split_sec']/data['final_sec']data.head()| age | gender | split | final | split_sec | final_sec | split_frac | |
|---|---|---|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 | 3938 | 7731 | -0.018756 |
| 1 | 32 | M | 01:06:26 | 02:09:28 | 3986 | 7768 | -0.026262 |
| 2 | 31 | M | 01:06:49 | 02:10:42 | 4009 | 7842 | -0.022443 |
| 3 | 38 | M | 01:06:16 | 02:13:45 | 3976 | 8025 | 0.009097 |
| 4 | 31 | M | 01:06:32 | 02:13:59 | 3992 | 8039 | 0.006842 |
如果前後半程差異係數( split_frac)小於0,就表示這個人是後半程加速型選手。畫出差異係數的分佈圖。
sns.distplot(data['split_frac'],kde=False,color='g')
plt.axvline(0, color="r",linestyle="--")#畫垂直x軸的線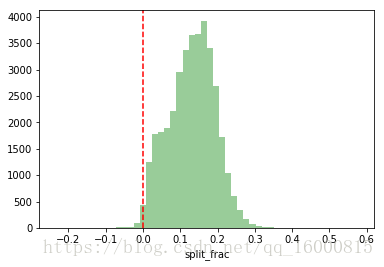
上圖表示前後半程差異係數分佈圖,0表示前後半程耗時相同。
sum(data['split_frac']<0)251
在大的4萬名馬拉松比賽選手中,只有250個人能做到後半程加速。再來看看前後半程差異係數與其他變數有沒有相關性。用一個矩陣圖pairgrid畫出所有變數間的相關性。
g=sns.PairGrid(data,vars=['age','split_sec','final_sec','split_frac'],hue='gender',palette='Set2',\
hue_kws={"marker": ["o", "s"]})
g.map(plt.scatter,alpha=0.8,linewidths=1, s=40)
g.add_legend()
g=sns.PairGrid(data,vars=['age','split_sec','final_sec','split_frac'],hue='gender',palette='hls',\
hue_kws={"marker": ["o", "^"]})
g.map_offdiag(plt.scatter,alpha=0.8,linewidths=1, s=40)#非對角線繪製散點圖
g.map_diag(plt.hist)#對角線繪製直方圖
g.add_legend()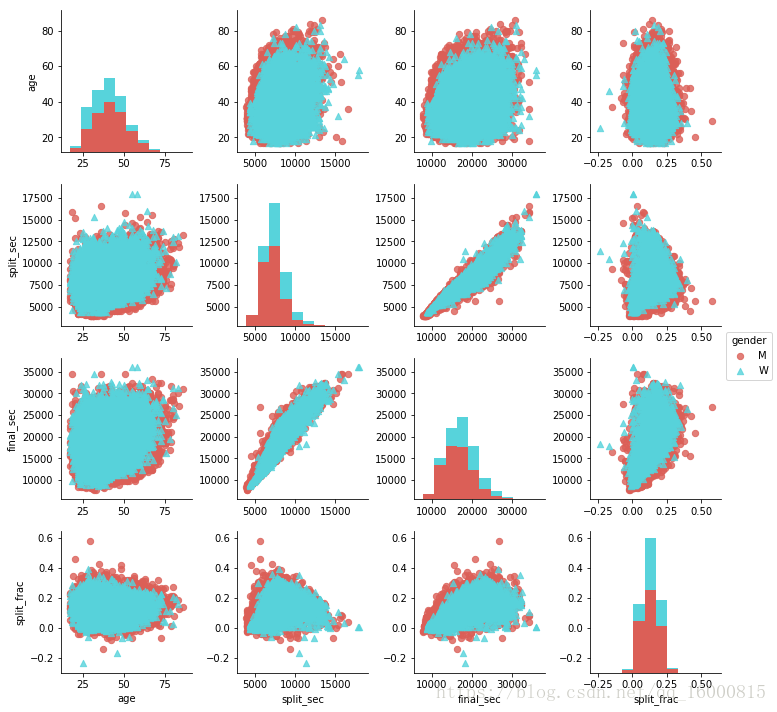
g=sns.PairGrid(data,vars=['age','split_sec','final_sec','split_frac'],hue='gender',\
palette=sns.color_palette("hls", 5),hue_kws={"marker": ["s", "d"]})
g.map(plt.scatter,alpha=0.8)
g.add_legend()
從圖中可以看出,雖然前後半程差異係數與年齡沒有顯著的相關性,但是與比賽的最終成績有顯著的相關性:全程耗時最短的選手,往往都是在前後半程儘量保持節奏一致、耗時非常接近的人。
對比男女選手之間的前後半程差異係數的頻次直方圖如下圖所示:
sns.kdeplot(data[data.gender=='M'].split_frac,label='men',shade=True)
sns.kdeplot(data[data.gender=='W'].split_frac,label='women',shade=True)
plt.xlabel('split_frac')
plt.ylim([0,10])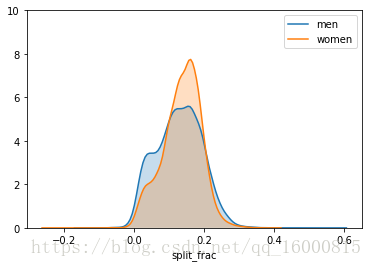
在前後半程耗時接近的選手中,男選手比女選手要多很多!男女選手的分佈看起來幾乎都是雙峰分佈。我們將男女選手不同年齡(age)的分佈函式畫出來,看看會得到什麼啟示。
用小提琴圖( violin plot)畫出這兩種分佈,如下圖所示。
小提琴圖其實是箱線圖與核密度圖的結合,箱線圖展示了分位數的位置,小提琴圖則展示了任意位置的密度,通過小提琴圖可以知道哪些位置的密度較高。在圖中,白點是中位數,黑色盒型的範圍是下四分位點到上四分位點,細黑線表示須。外部形狀即為核密度估計(在概率論中用來估計未知的密度函式,屬於非引數檢驗方法之一)。
sns.violinplot('gender','split_frac',data=data,palette=['lightblue','lightpink'])
# 分組的小提琴圖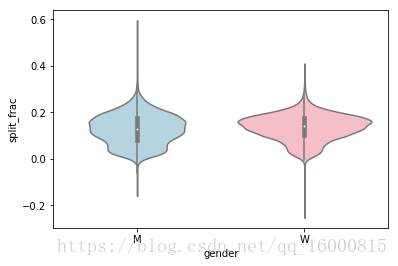
觀察這幅圖,對比兩個由年齡構成函式的小提琴圖,在陣列中建立一個新列,表示每名選手的年齡段。
data['age_dec']=data['age'].map(lambda x: 10*(x//10))data.head()| age | gender | split | final | split_sec | final_sec | split_frac | age_dec | |
|---|---|---|---|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 | 3938 | 7731 | -0.018756 | 30 |
| 1 | 32 | M | 01:06:26 | 02:09:28 | 3986 | 7768 | -0.026262 | 30 |
| 2 | 31 | M | 01:06:49 | 02:10:42 | 4009 | 7842 | -0.022443 | 30 |
| 3 | 38 | M | 01:06:16 | 02:13:45 | 3976 | 8025 | 0.009097 | 30 |
| 4 | 31 | M | 01:06:32 | 02:13:59 | 3992 | 8039 | 0.006842 | 30 |
with sns.axes_style(style='whitegrid'):
sns.violinplot('age_dec','split_frac',data=data,inner='quartile',\
palette="muted")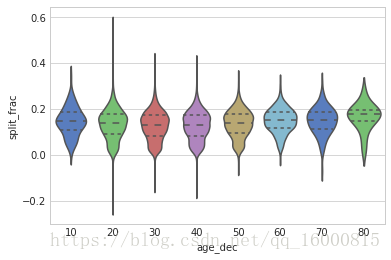
# 通過hue分組的小提琴圖,相當於分組之後又分組
with sns.axes_style(style='whitegrid'):
sns.violinplot('age_dec','split_frac',hue='gender',data=data,inner='quartile',\
palette="muted")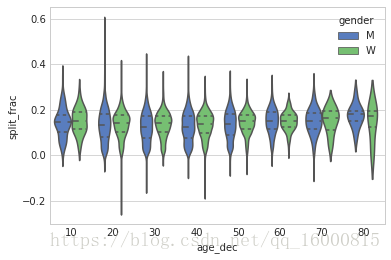
# 分組組合的小提琴圖,其實就是hue分組後,各取一半組成一個小提琴圖
with sns.axes_style(style='whitegrid'):
sns.violinplot('age_dec','split_frac',hue='gender',data=data,split=True,inner='quartile',\
palette=['red','orange'])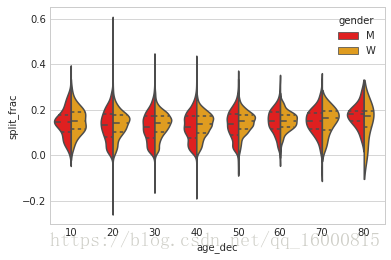
上圖是用小提琴圖表示不同性別,年齡段的前後半程差異係數。通過上圖可以看出男女選手的分佈差異:20多歲至50多歲各年齡段的男選手的前後半程差異係數概率密度都比同年齡段的女選手低一些(或者可以說任意年齡都如此)。
還有一個令人驚訝的地方是,所有八十歲以上的女選手都比同年齡段的男選手的表現好。這可能是由於這個年齡段的選手寥宴無幾,樣本太少。
(data.age>80).sum()
7
讓我們再看看後半程加速型選手的資料:前後半程差異係數與比賽成績正相關嗎?我們可以輕鬆畫出圖形。下面用implot為資料自動擬合一個線性迴歸模型,如下圖所示。
g=sns.lmplot('final_sec','split_frac',col='gender',data=data,\
markers='s',scatter_kws=dict(color='c'))
g.map(plt.axhline,y=-0.1,color='r',ls='--')
g.map(plt.axhline,y=0,color='r',ls='--')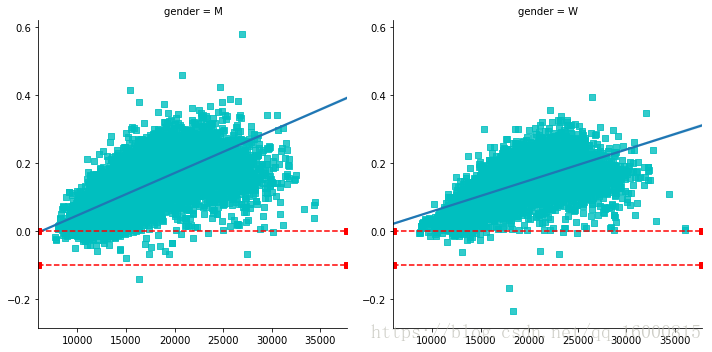
從上圖明顯可以看出前後半程差異係數與比賽成績正相關,有顯著後半程加速的男性選手比賽成績在15000秒左右,即4小時之內的種子選手。低於這個成績的選手很少有顯著的後半程加速。有顯著後半程加速的女性選手比賽成績大於15000秒,接近20000秒,主要是由於前半程耗時(過多)大於後半程耗時。
下面再從多種圖形模式的角度對資料進行探索性分析。
# 繪製箱線圖
#在分析資料的時候,箱線圖能夠直觀地識別資料集中的異常值(檢視離群點)
ax = sns.boxplot(x=data['final_sec'])
ax = sns.boxplot(x=data['split_sec'])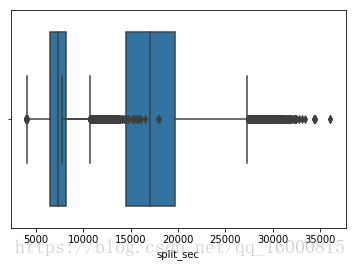
# 豎著放的箱線圖,也就是將x換成y
ax = sns.boxplot(y=data['final_sec'])
ax = sns.boxplot(y=data['split_sec'])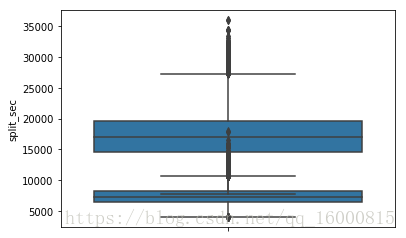
# 分組繪製箱線圖,分組因子是gender,在x軸不同位置繪製
ax = sns.boxplot(x="gender", y="final_sec", data=data,palette='RdBu',linewidth=3)
# 分組箱線圖,分組因子是gender,不同的因子用不同顏色區分
# 相當於分組之後又分組
ax = sns.boxplot(x="age_dec", y="final_sec", hue="gender",
data=data, palette="husl")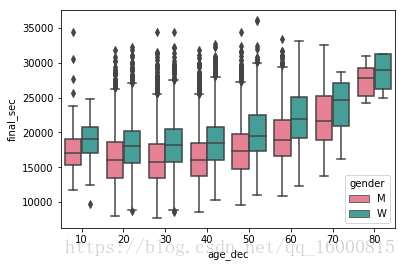
# 改變x軸順序,order引數
ax = sns.boxplot(x="age_dec", y="final_sec", hue="gender",
data=data, palette="husl",order=[80,70,60,50,40,30,20,10],linewidth=1.5)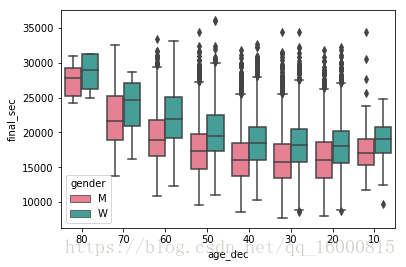
# 散點圖
ax1 = sns.stripplot(x=data["age_dec"])
# 分組的散點圖
ax = sns.stripplot(x="gender", y="split_sec", data=data)
ax = sns.stripplot(x="age_dec", y="split_sec", data=data)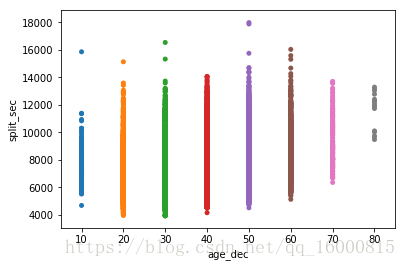
#散點圖通常將重疊。這使得很難看到資料的完整分佈。一個簡單的解決方案是使用一些隨機的“抖動”調整位置(僅沿著分類軸)
## 新增抖動項的散點圖,jitter=True
ax = sns.stripplot(x="age_dec", y="split_sec", data=data,jitter=True)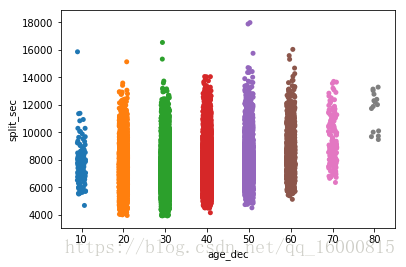
#按照hue=gender分組
ax = sns.stripplot(x="age_dec", y="split_sec",hue='gender',data=data,jitter=True,\
palette=sns.hls_palette(8, l=.5, s=.8))
#分開繪製split=True控制
ax = sns.stripplot(x="age_dec", y="split_sec",hue='gender',data=data,jitter=True,\
palette=sns.hls_palette(8, l=.5, s=.8),split=True)
#按照hue=age_dec分組
ax = sns.stripplot(x='gender', y="split_sec",hue="age_dec",data=data,jitter=True,\
palette=sns.color_palette("hls", 8),split=True)
# 散點圖+小提琴圖
ax = sns.violinplot(x="age_dec", y="split_sec", data=data,palette='Set2')
ax = sns.stripplot(x="age_dec", y="split_sec",hue='gender',data=data,jitter=True,\
palette=sns.hls_palette(8, l=.5, s=.8))
# 箱線圖+散點圖
# whis 引數設定是否顯示箱線圖的離群點,whis=np.inf 表示不顯示
ax = sns.boxplot(x="gender", y="split_sec", data=data,whis=np.inf)
ax = sns.stripplot(x="gender", y="split_sec",hue='gender',data=data,jitter=True,\
palette=sns.hls_palette(8, l=.8, s=.8))
#柱狀圖
sns.barplot(x="age_dec", y="split_sec",data=data)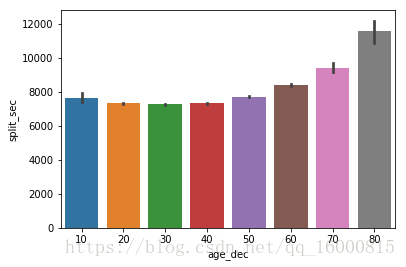
#按照hue分組的柱狀圖,預設統計的是age_dec變數的均值,estimator=np.mean
sns.barplot(x="age_dec", y="split_sec",hue='gender',data=data,palette=sns.color_palette("Set2", 10))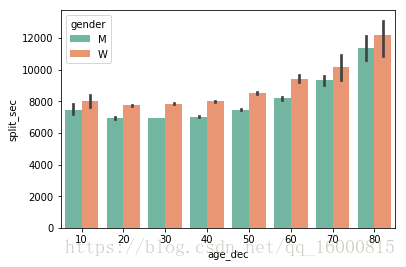
#修改預設的統計函式,estimator=max
sns.barplot(x="age_dec", y="split_sec",hue='gender',data=data,\
palette=sns.color_palette("Set1", 5),estimator=max)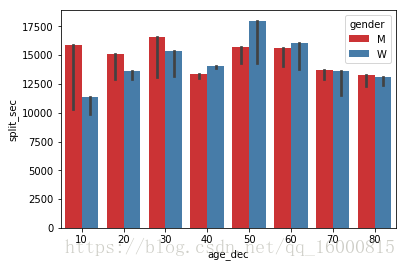
#頻數條形圖
sns.countplot(x="gender", data=data)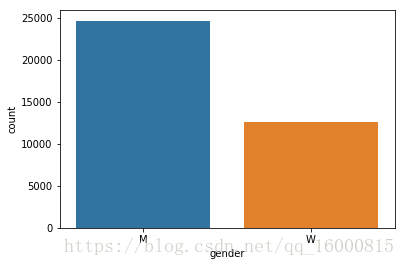
sns.countplot(x="gender",hue='age_dec',data=data)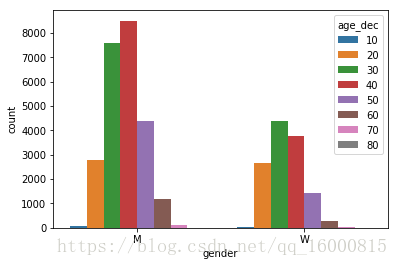
因子圖
因子圖也是對資料子集進行視覺化的方法,你可以通過它觀察一個引數在另一個引數間隔中的分佈情況
with sns.axes_style(style='ticks'):
g=sns.factorplot(x='age_dec',y='final_sec',hue='gender',data=data,kind='box')
g.set_axis_labels('Age_dec','Final_sec')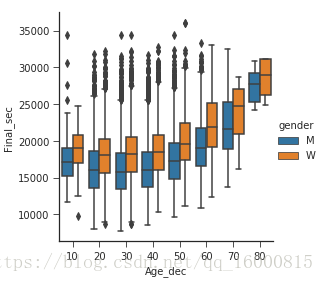
with sns.axes_style(style='ticks'):
g=sns.factorplot(x='age_dec',y='final_sec',hue='gender',data=data,kind="violin",\
palette=sns.color_palette("dark"))
g.set_axis_labels('Age_dec','Final_sec')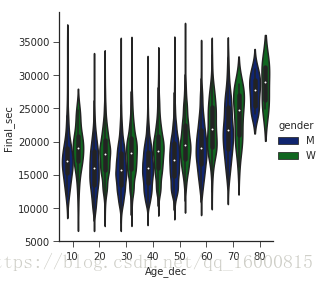
#col_wrap控制每行畫幾個圖,col控制分開繪圖的因子
g = sns.factorplot(x="gender",y='final_sec',col="age_dec", col_wrap=4,palette=sns.color_palette("bright"),\
data=data,kind="violin", size=4, aspect=.8)
g.set_axis_labels('gender','final_sec')
#col_wrap控制每行畫幾個圖,kind控制繪圖的型別,size控制圖形的大小
with sns.axes_style('dark'):
g = sns.factorplot(x="gender",col="age_dec", col_wrap=2,palette=sns.color_palette("coolwarm", 7),\
data=data,kind="count", size=4, aspect=.8)
g.set_xlabels('gender')
g.set_ylabels('Count')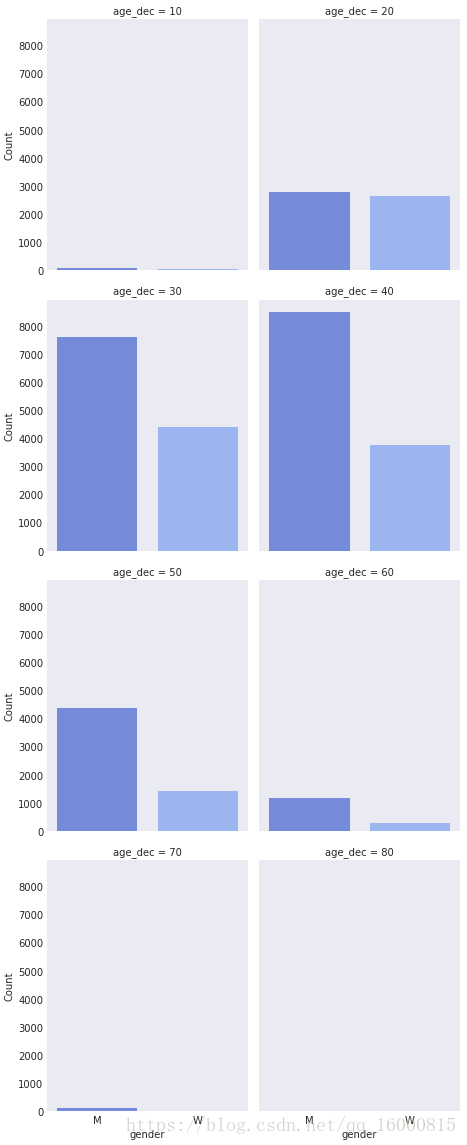
迴歸圖lmplot
g = sns.lmplot(x="split_sec", y="final_sec", data=data,markers='^',scatter_kws=dict(color='r'),\
line_kws=dict(color='g',linestyle='--'))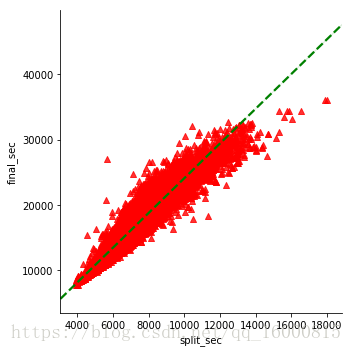
# 分組的線性迴歸圖,通過hue引數控制
g = sns.lmplot(x="split_frac", y="final_sec",hue="gender", data=data,markers=['s','d'],\
palette=dict(M="g", W="m"))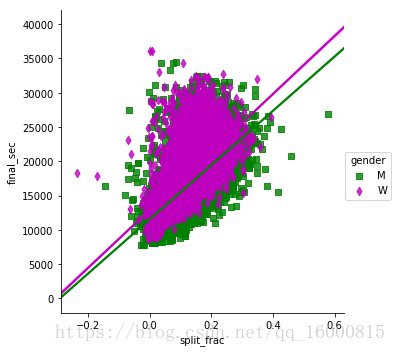
#按照gender分組,畫在兩張圖上
g = sns.lmplot(x="split_frac", y="final_sec",col="gender", data=data,markers='x',\
palette=sns.set_palette("husl"))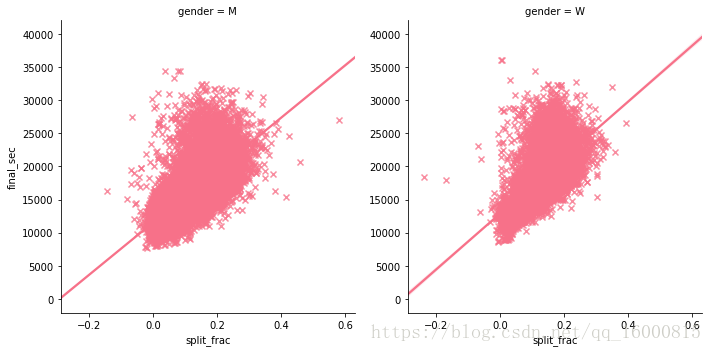
## col+hue 雙分組引數,既分組,又分子圖繪製,jitter控制散點抖動程度
g = sns.lmplot(x="split_frac", y="final_sec",hue='gender',col="gender", data=data,markers='s',\
line_kws=dict(color='b',linestyle='--'),palette=sns.set_palette("husl",3),x_jitter=.2,aspect=1)
g.map(plt.axvline,x=0,color='r',ls='-')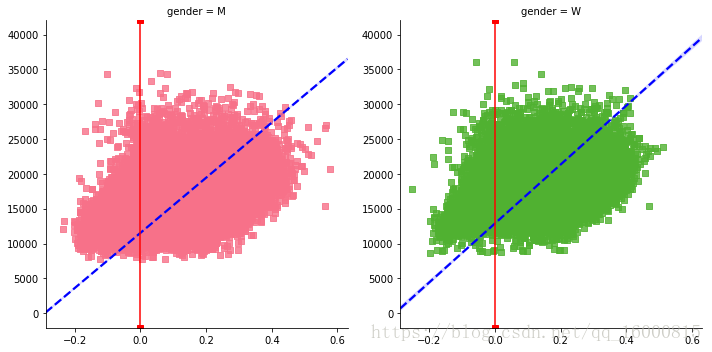
g = sns.lmplot(x="split_frac", y="final_sec",hue='age_dec',col="age_dec", data=data,markers='d',\
line_kws=dict(color='g',linestyle='--'),palette='Set3',\
col_wrap=4, size=3,x_jitter=.2,aspect=1)
g.map(plt.axvline,x=0,color='y',ls='-')
g.set_axis_labels("split_frac","final_sec")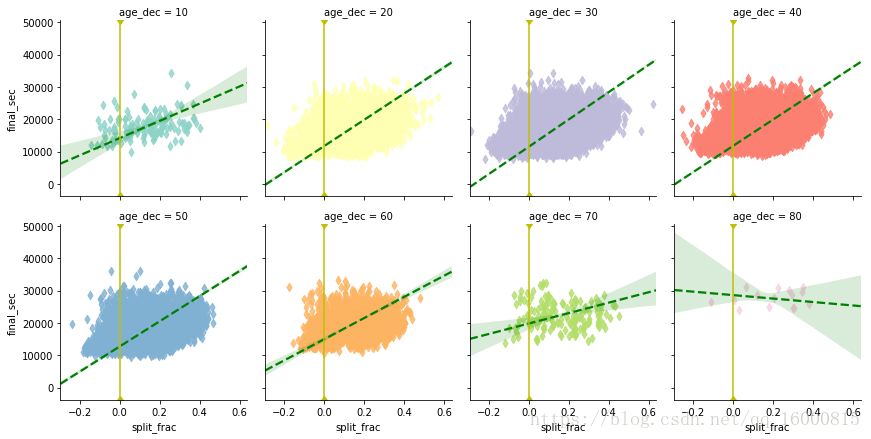
# 既然col可以控制分組子圖的,那麼row也是可以控制分組子圖的
g = sns.lmplot(x="split_frac", y="final_sec",col='gender',row="age_dec",data=data,markers='o',\
line_kws=dict(color='g',linestyle='--'),\
size=3,x_jitter=.1,aspect=1)
g.map(plt.axvline,x=0,color='r',ls='-')
g.set_axis_labels("split_frac","final_sec")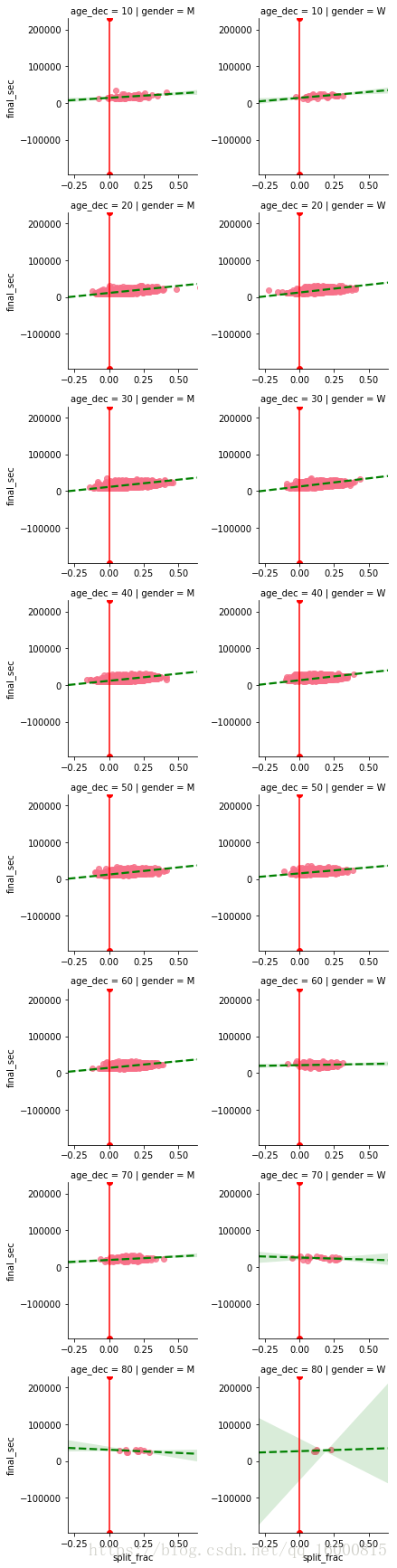
熱力圖heatmap
sns.heatmap(data[['gender','age','age_dec','split_sec','final_sec','split_frac']].corr())
sns.heatmap(data[['gender','age','age_dec','split_sec','final_sec','split_frac']].corr(),annot=True)