
深入淺出解讀"多巴胺(Dopamine)論文"、環境配置和例項分析

Paper: Dopamine–a research framework for deep reinforcement Learning
Github: https://github.com/google/dopamine
論文的首頁明顯告訴我們,這是一篇Google出的論文(所以值得一讀),該文作者提出了一種新的深度強化學習研究框架: 多巴胺(Dopamine),旨在於豐富DRL的多樣性,該框架是一個開源的,基於tensorflow平臺的的最先進的智慧體實現平臺,並通過深入研究RL中不同研究目標的分類來補充這一產品。雖然並非詳盡無遺,但分析強調了該領域研究的異質性以及框架的價值。
Introduction
目前很多強化學習的研究主要集中在特定領域的決策,比如視覺識別後的控制(atari)等,由於複雜的相互作用的轉變,為深度RL研究編寫可重複使用的軟體也變得更具挑戰性。首先,寫一個智慧體需要一個architecure,比如用openai的baseline實現DQN,它的智慧體由6個模組組成,其次,現在有很多演算法可供選擇,因此在一個實現中全面實現通常需要犧牲簡單性。 最重要的是深度RL研究的日益多樣化使得很難預見下一個研究專案可能具備的軟體需求。
這篇文章提出的多巴胺的目的是為深度強化學習提供一個基礎研究,它強調的是緊湊,而不是全面,第一個版本由12個python檔案,這些為Arcade學習環境提供了最先進的,基於價值的智慧體的測試實現。該程式碼旨在為該領域的新手容易理解,同時為所有智慧體提供互動式筆記本,訓練模型和可下載的訓練資料,以及包括以前釋出的學習曲線的源。
同時作者確定了不同的研究目標,並討論了支援這些目標的程式碼的期望:architecture research, comprehensive studies, visualization, algorithmic research, and instruction,並在設計Dopamine時考慮了最後兩個目標,他們的研究只在於在深層RL框架生態系統中扮演著獨特的角色。
深度強化學習的軟體研究
深度學習社群現已確定了許多對其研究目標至關重要的操作:元件模組化,自動區分和視覺化等,由於強化學習是一個比較新的領域,導致在對軟體的共識一直很elusive(難懂的;難捉摸的),該文不會詳盡的去解釋,但強調了該研究自然屬性的多樣性。為了能夠對重點突出研究,作者僅從下面兩個方面研究:
- 深度強化學習的基礎研究。
- 應用於或評估模擬環境。
同時,該文的研究環境為:Arcade Learning Environment(該環境是一個為很多研究者提供實現atari遊戲智慧體的簡單的框架:Arcade Learning Environment,
case研究
所謂的架構研究涉及元件之間的互動,包括網路拓撲,以建立深度RL代理。 DQN在使用代理體系結構方面具有創新性,包括目標網路,重放記憶體和Atari特定的預處理。 從那時起,如果沒有預料到代理由多個互動元件組成就變得司空見慣了,通常情況下從以下三個方面著手:
- Algorithmic research 架構研究
- Comprehensive studies
- Visualization
不同目標的不同軟體的研究從下面四個角度開始
- Comprehensive studies
- Architecture research
- Algorithmic research
- Conclusions.
多巴胺(Dopamine)
在多巴胺的設計中,google 設計它滿足了兩個條件:自給自足且緊湊、可靠且可重複:

自給自足且緊湊可以幫助研究者實現一個簡單的框架,並且可以集中進行演算法研究,同時可靠則保證了實驗、演算法的結果具有trust。
多巴胺的整體結構設計
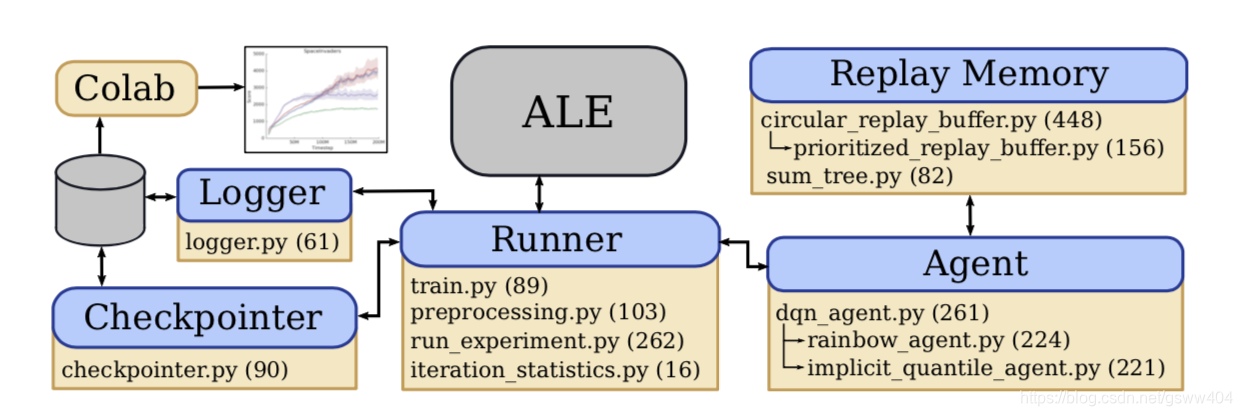
其中:藍盒子是軟體元件。 黃色框表示組成軟體元件的檔名; 有向箭頭表示類繼承,而括號中的數字表示非註釋Python行的數量。
- Runner類管理代理和ALE之間的互動(例如,採取步驟和接收觀察)以及簿記(例如,分別通過檢查指標和記錄器進行檢查點和記錄)。
- Checkpointer負責定期儲存實驗狀態,使故障後能夠正常恢復,並重新學習重量。
- 記錄器負責將實驗統計(例如,累積的培訓或評估獎勵)儲存到磁碟以進行視覺化。
- Colab提供互動式筆記本,以便於這些統計資料的視覺化。
可靠且可重複:
作者為所有程式碼庫提供了一整套測試,程式碼覆蓋率超過98%。除了幫助確保程式碼的正確性之外,這些測試還提供了另一種形式的文件,補充了隨框架提供的常規文件和互動式筆記本。
多巴胺使用gin-config 【config過程】來配置不同的模組。 Gin-config是引數注入的簡單方案,即動態更改方法的預設引數。 在多巴胺中,在單個檔案中指定實驗的所有引數。 下面程式碼顯示了預設DQN代理設定的配置示例(附錄D中提供了所有代理的完整gin-config檔案)
DQNAgent.gamma = 0.99
DQNAgent.epsilon_train = 0.01
DQNAgent.epsilon_decay_period = 250000 # agent steps
DQNAgent.optimizer = @tf.train.RMSPropOptimizer()
tf.train.RMSPropOptimizer.learning_rate = 0.00025
Runner.sticky_actions = True
WrappedReplayBuffer.replay_capacity = 1000000
WrappedReplayBuffer.batch_size = 32
基準線對比
作者在探索的目的不是提供一組最佳的超引數,而是提供一致的集合作為基線,同時促進超引數探索的過程。下圖是實驗的資料顯示:

同時作者也將已釋出設定的結果與預設設定進行比較(下圖),平均超過5次執行。 在每個遊戲中,已釋出和預設設定之間的y-scales是不同的; 這主要是因為預設設定中使用了粘滯action。

重新審視ARCADE學習環境:一個測試案例
Episode終止
當一個人正常停止遊戲時,ALE認為一個episode完成:當他們完成遊戲或者用盡生命時。 將這種終止條件稱為“遊戲結束”。 Mnih等引入了一種稱為生命損失的啟發式方法,當玩家失去生命時,它會在重放記憶中新增人工插曲邊界。 在最近的文獻中已經使用了episode終止的兩種定義。 在多巴胺中執行此實驗包括修改以下gin-config選項:
AtariPreprocessing.terminal_on_life_loss = True
下圖顯示了兩種情況下報告的效能差異。雖然episode表明,Life Loss啟發式技術可以提高一些簡單遊戲的效能,但是Bellemare等人指出,它阻礙了其他人的表現,特別是因為智慧體無法瞭解失去生命的真實後果。根據Machado等人的指南,在預設設定中禁用了Life Loss啟發式。

測量訓練資料和總結學習效能
多巴胺支援兩種執行方式:train和train_and_eval。 前者僅測量訓練期間的平均分數,而後者則與評估執行相交學習。

粘性動作影響在智慧體上的效能
原始ALE具有確定性轉換,其獎勵可以記憶行動序列以獲得高分的代理。為緩解此問題,最新版本的ALE實現了粘性操作。粘性動作使用粘性引數ς,這是環境執行代理程式之前操作的概率,而不是代理程式剛剛選擇的那種 - 有效地實現了一種動作形式。 在多巴胺中執行此實驗包括修改以下gin-config選項:
Runner.sticky_actions = False
下圖演示了使用或不使用粘性操作執行時效能上的差異。雖然在某些情況下(Rainbow播放SPACE INVADERS)粘性動作似乎可以提高效能,但它們通常會降低效能。同時平均分數學習曲線(rainbow超越DQN); 因此,並根據Machado等人提出的建議,多普胺預設啟用粘滯動作。

環境安裝
Ubuntu
1、設定初始化虛擬環境
sudo apt-get update && sudo apt-get install virtualenv
virtualenv --python=python2.7 dopamine-env
source dopamine-env/bin/activate
這將建立一個名為dopamine-env的目錄,其中包含虛擬環境。 最後一個命令啟用環境。
2、將依賴項安裝到多巴胺。如果無法訪問GPU,請在下面的行中將tensorflow-gpu替換為tensorflow(有關詳細資訊,請參閱Tensorflow說明)。
sudo apt-get update && sudo apt-get install cmake zlib1g-dev
pip install absl-py atari-py gin-config gym opencv-python tensorflow-gpu
注:在安裝過程中,您可以安全地忽略以下錯誤訊息:tensorflow 1.10.1要求numpy <= 1.14.5,> = 1.13.3,但是您將擁有不相容的numpy 1.15.1。
3、下載多巴胺原始檔
git clone https://github.com/google/dopamine.git
Mac OS
同樣的道理,和以上以上的過程一樣,程式碼為:
pip install virtualenv
virtualenv --python=python2.7 dopamine-env
source dopamine-env/bin/activate
brew install cmake zlib
pip install absl-py atari-py gin-config gym opencv-python tensorflow
git clone https://github.com/google/dopamine.git
在獲得源後便是測試初始化可以成功執行,通過以下命令:
cd dopamine
export PYTHONPATH=${PYTHONPATH}:.
python tests/atari_init_test.py
標準Atari 2600實驗的切入點是dopamine/atari/train.py。 要執行基本DQN代理,
python -um dopamine.atari.train \
--agent_name=dqn \
--base_dir=/tmp/dopamine \
--gin_files='dopamine/agents/dqn/configs/dqn.gin'
預設情況下,這將啟動一個持續2億幀的實驗。 命令列介面將輸出有關最新訓練集的統計資訊:
[...]
I0824 17:13:33.078342 140196395337472 tf_logging.py:115] gamma: 0.990000
I0824 17:13:33.795608 140196395337472 tf_logging.py:115] Beginning training...
Steps executed: 5903 Episode length: 1203 Return: -19.
通常情況下,多巴胺通過gin配置是非常簡單的
安裝依賴包
安裝多巴胺的一種簡單的替代方法是作為Python庫:
# Alternatively brew install, see Mac OS X instructions above.
sudo apt-get update && sudo apt-get install cmake
pip install dopamine-rl
pip install atari-py
從root目錄下,通過以下命令測試:
python -um tests.agents.rainbow.rainbow_agent_test
例項建立
在本節中,將演示如何通過繼承其中一個提供的代理來建立新代理。 此程式碼僅用於說明目的。
首先設定預設資訊
DQNAgent.gamma = 0.99 # 衰減係數
DQNAgent.update_horizon = 1
DQNAgent.min_replay_history = 20000 # agent steps
DQNAgent.update_period = 4
DQNAgent.target_update_period = 8000 # agent steps
DQNAgent.epsilon_train = 0.01
DQNAgent.epsilon_eval = 0.001
DQNAgent.epsilon_decay_period = 250000 # agent steps
DQNAgent.tf_device = ’/gpu:0’ # use ’/cpu:*’ for non-GPU version
DQNAgent.optimizer = @tf.train.RMSPropOptimizer()
tf.train.RMSPropOptimizer.learning_rate = 0.00025
tf.train.RMSPropOptimizer.decay = 0.95
tf.train.RMSPropOptimizer.momentum = 0.0
tf.train.RMSPropOptimizer.epsilon = 0.00001
tf.train.RMSPropOptimizer.centered = True
Runner.game_name = ’Pong’
Runner.sticky_actions = True
Runner.num_iterations = 200
Runner.training_steps = 250000 # agent steps
Runner.evaluation_steps = 125000 # agent steps
Runner.max_steps_per_episode = 27000 # agent steps
WrappedReplayBuffer.replay_capacity = 1000000
WrappedReplayBuffer.batch_size = 32
繼續開始代部分:
import numpy as np
import os
from dopamine.agents.dqn import dqn_agent
from dopamine.atari import run_experiment
from dopamine.colab import utils as colab_utils
from absl import flags
BASE_PATH = ’/tmp/colab_dope_run’
GAME = ’Asterix’
LOG_PATH = os.path.join(BASE_PATH, ’random_dqn’, GAME)
class MyRandomDQNAgent(dqn_agent.DQNAgent):
def __init__(self, sess, num_actions):
"""This maintains all the DQN default argument values."""
super(MyRandomDQNAgent, self).__init__(sess, num_actions)
def step(self, reward, observation):
"""Calls the step function of the parent class, but returns a random
action.
"""
_ = super(MyRandomDQNAgent, self).step(reward, observation)
return np.random.randint(self.num_actions)
def create_random_dqn_agent(sess, environment):
"""The Runner class will expect a function of this type to create an
agent."""
return MyRandomDQNAgent(sess, num_actions=environment.action_space.n)
# Create the runner class with this agent. We use very small numbers of
# steps
# to terminate quickly, as this is mostly meant for demonstrating how one
# can
# use the framework. We also explicitly terminate after 110 iterations (
# instead
# of the standard 200) to demonstrate the plotting of partial runs.
random_dqn_runner = run_experiment.Runner(LOG_PATH,
create_random_dqn_agent,
game_name=GAME,
num_iterations=200,
training_steps=10,
evaluation_steps=10,
max_steps_per_episode=100)
print(’Will train agent, please be patient, may be a while...’)
random_dqn_runner.run_experiment()
print(’Done training!’)
此程式碼段提供了一個互動式顯示,使用者可以根據訓練基線訓練和視覺化代理的效能,如下所示:
import seaborn as sns
import matplotlib.pyplot as plt
random_dqn_data = colab_utils.read_experiment(LOG_PATH, verbose=True)
random_dqn_data[’agent’] = ’MyRandomDQN’
random_dqn_data[’run_number’] = 1
experimental_data[GAME] = experimental_data[GAME].merge(random_dqn_data,fig, ax = plt.subplots(figsize=(16,8))
sns.tsplot(data=experimental_data[GAME], time=’iteration’, unit=’
run_number’,
condition=’agent’, value=’train_episode_returns’, ax=ax)
plt.title(GAME)
plt.show()
注:其中import seabore as sns 是個視覺化工具
最終結果如圖:
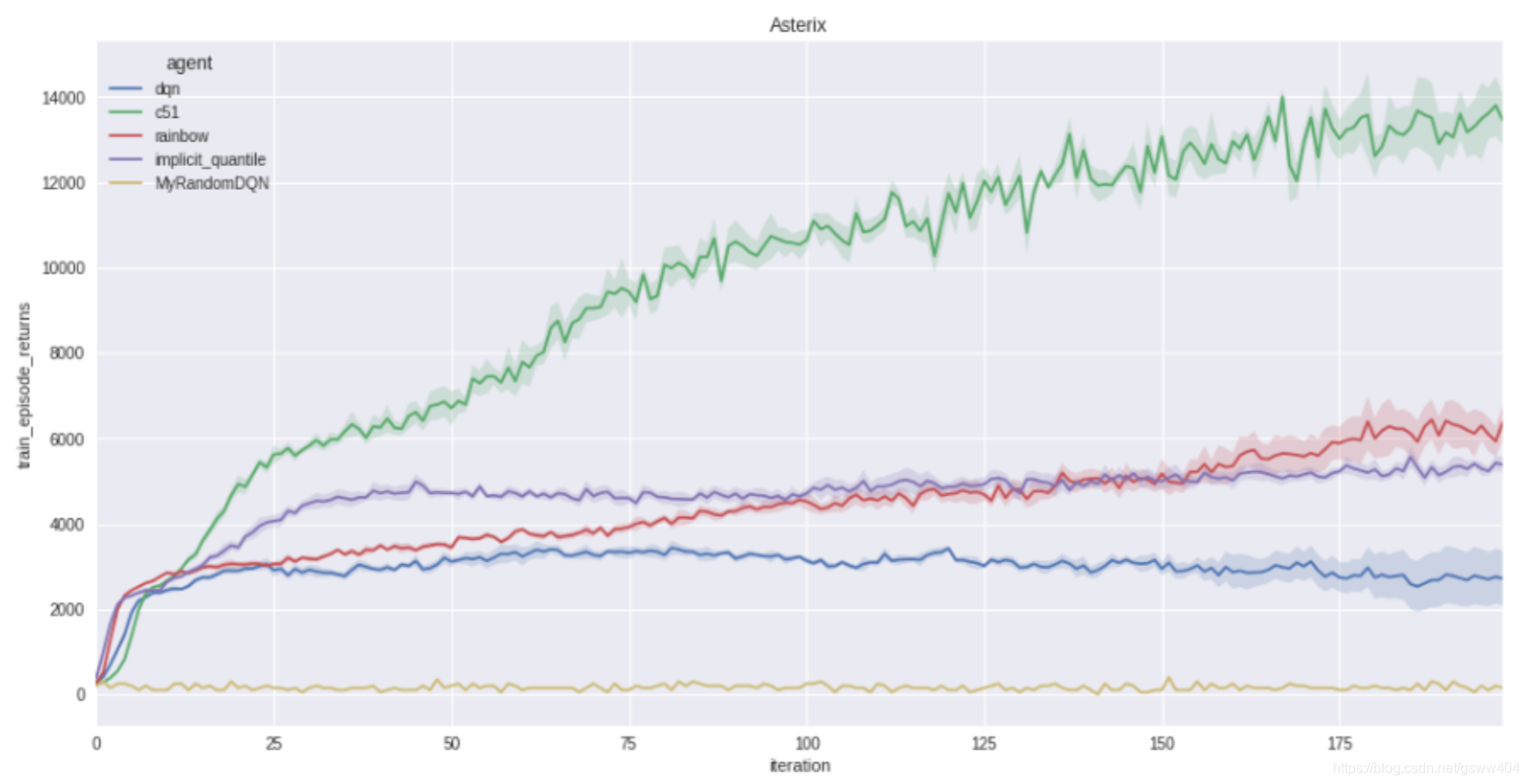
至此,以上是對多巴胺的部分解讀,關於更多的c51等請自行閱讀和安裝。部分程式碼請學習github原始碼,受能力有限,文中難免有錯誤之處,還望大家多提意見、以便做的更好!
參考文獻:
1、DOPAMINE: A RESEARCH FRAMEWORK FOR DEEP REINFORCEMENT LEARNING